Prototype Network를 NLP를 이용해 구현해보았다.
Phillip Lippe님이 CIFAR100과 DenseNet을 사용하여 작성하신 기존 코드를 Bert모델과 NLP Task에 맞게끔 조금씩 변경하면서 공부를 하였다,
그로인해 코드 구성과 ProtoNet을 구현하는 것이 다소 옳바르지 않을 수도 있다.
Colab을 사용하였고, Bert모델과 Pytorch Lightning을 통해 코드를 구현하였다.
ATIS Dataset을 통해서 Train, Valid, Test을 모두 사용하였으며
ATIS로 학습된 모델에 제 3의 Dataset인 SNIPS Dataset을 사용해 검증을 진행해 보았다.
- 구글 드라이브를 마운트
- ATIS와 SNIPS Dataset을 다운받기 위한 깃 클론
- pytorch lightning 및 transformers 설치
- 각종 라이브러리 import 및 config값 설정

- Dataset을 눈으로 확인하기 위해 DataFrame으로 만들어 주고
- 각 Dataset마다 label의 개수 확인
- 중복되는 label을 없애기 위해 합집합으로 묶어준 후 label과 index로 변경해주는 코드 작성

- 기존 str형의 label을 one-hot 인코딩 진행
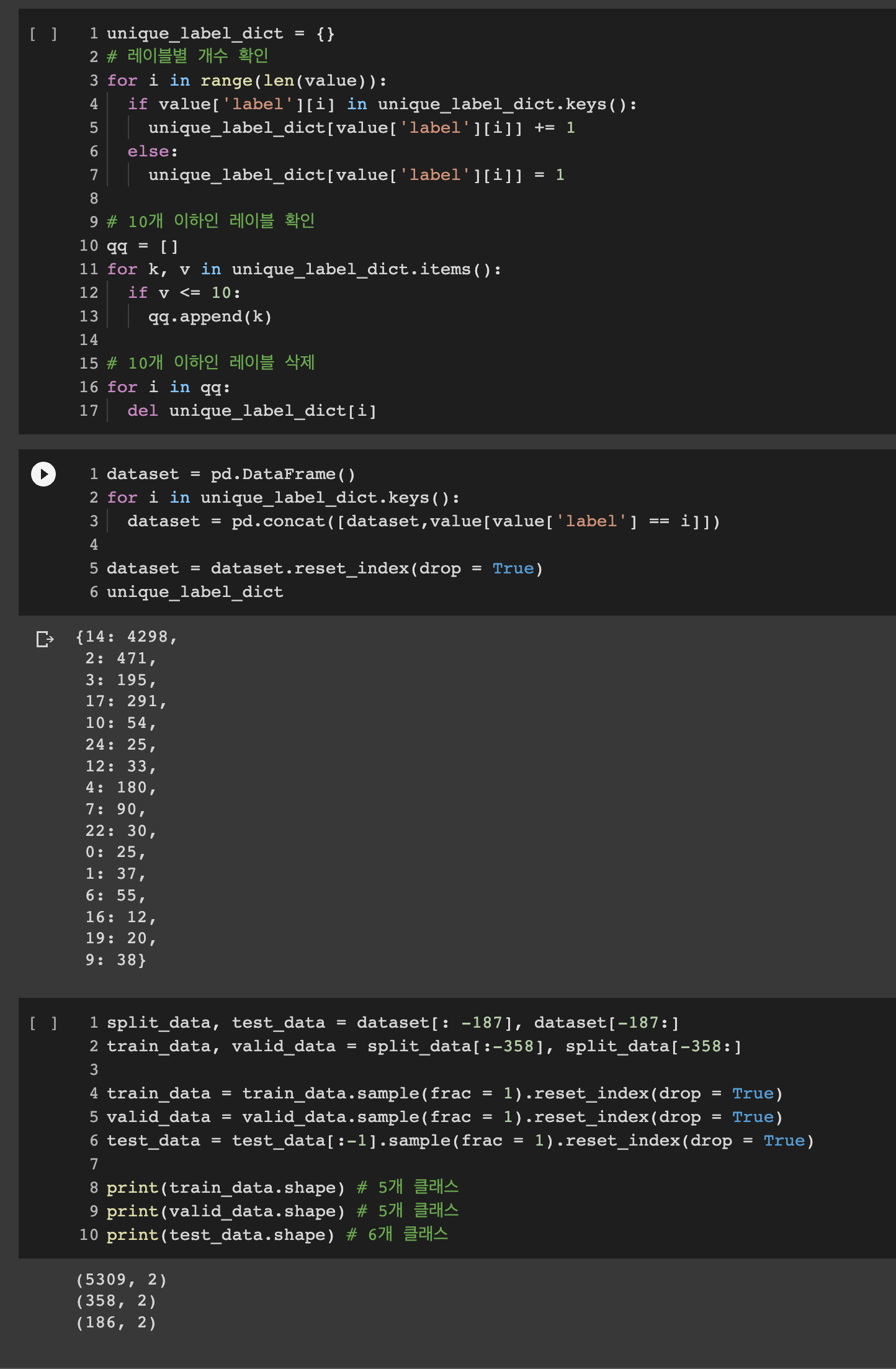
-
Dataset을 살펴보면 class당 개수가 적은것들이 존재해 10개 이하의 label을 가지고 있는 class는 삭제해 준 후
-
Train / Valid / Test로 구분해주기 위해 class의 개수가 비슷하게 (5개, 5개, 6개)로 구성하게끔 수작업으로 Dataset을 분리
-
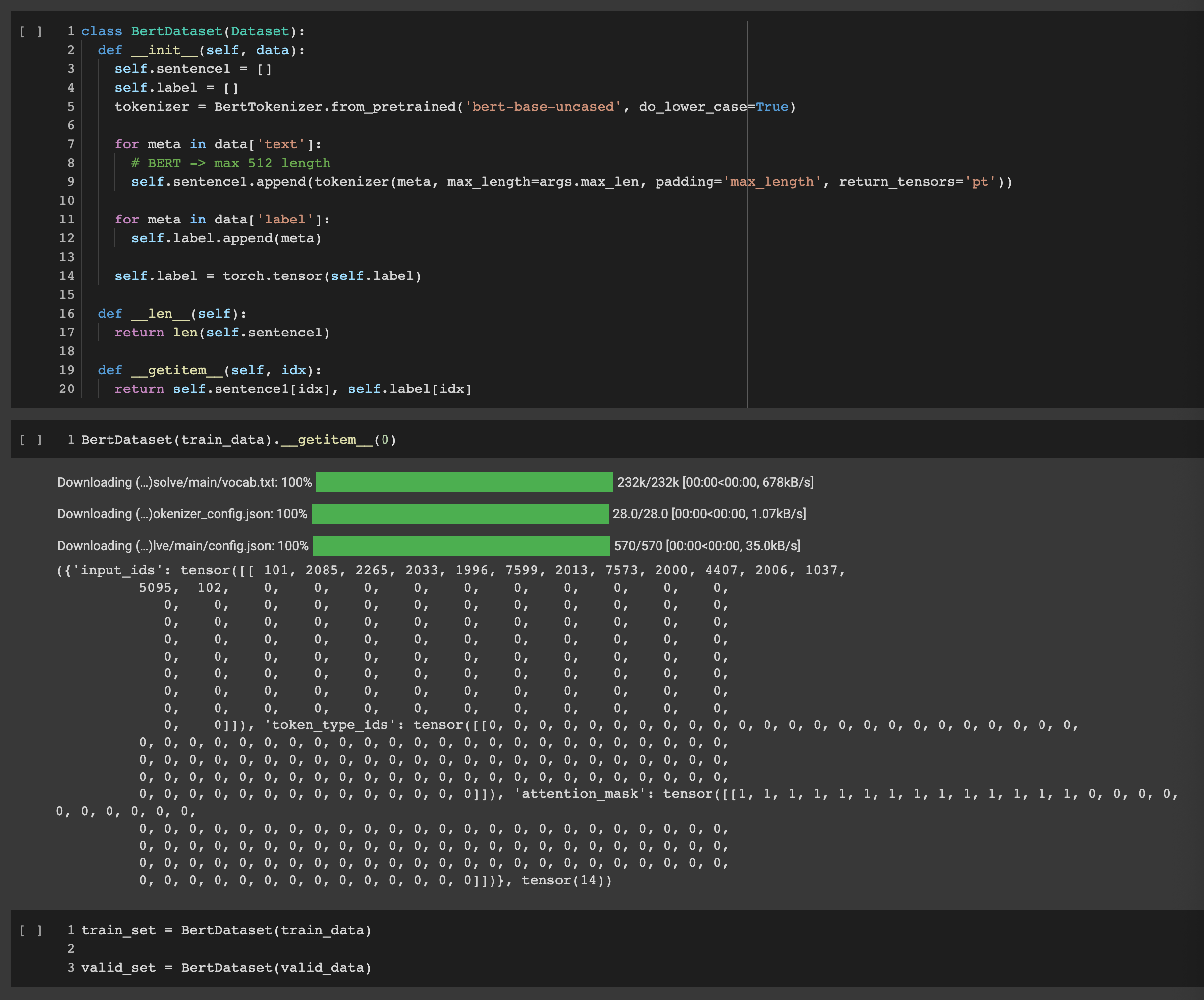
pytorch Dataset 클래스를 구성해 tokenizer로 변경하고 train과 valid Dataset을 변환

-
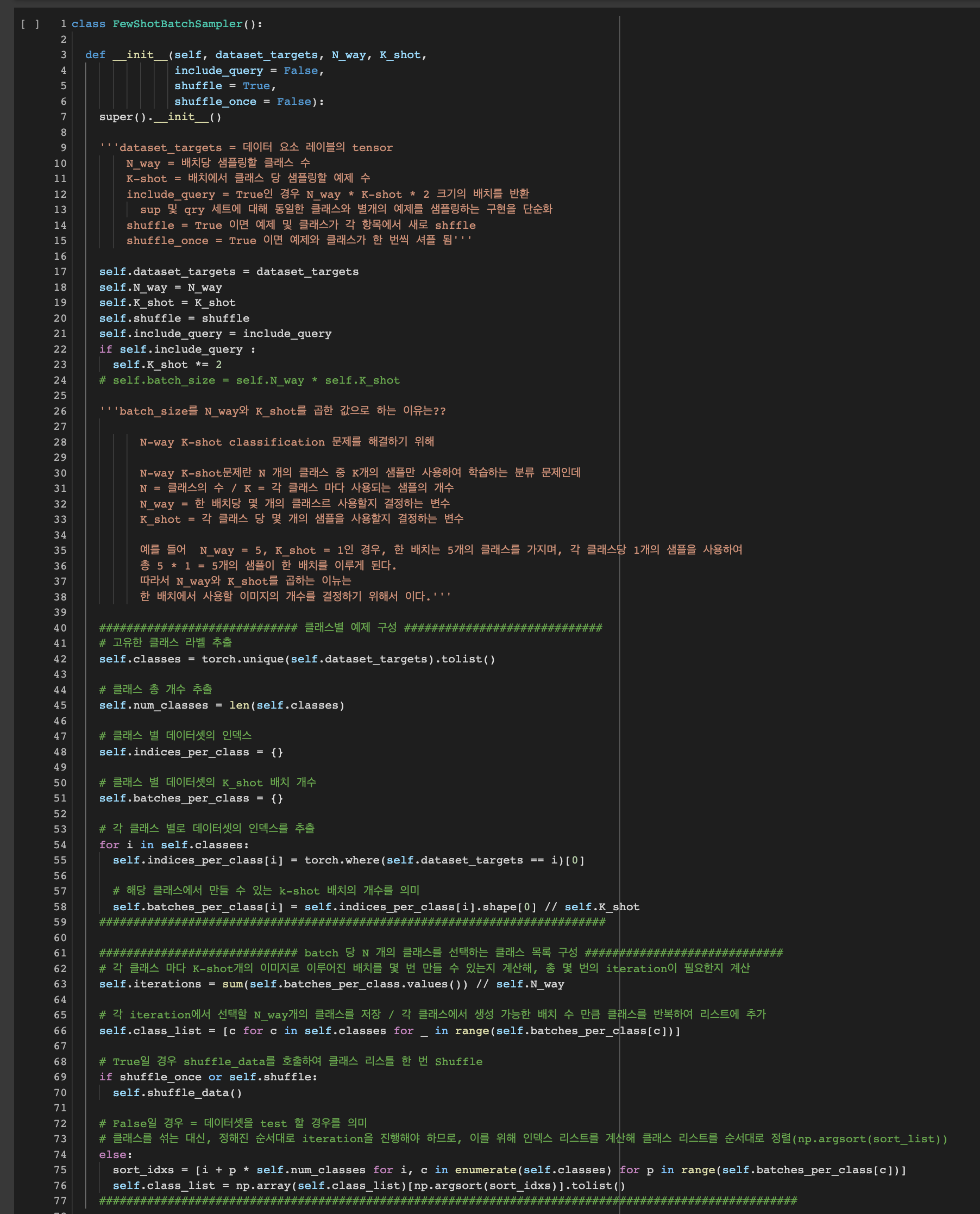
Quert_set과 Support_set으로 배치가 구성되야 하기 때문에 따로 batch_sampler를 구성
-
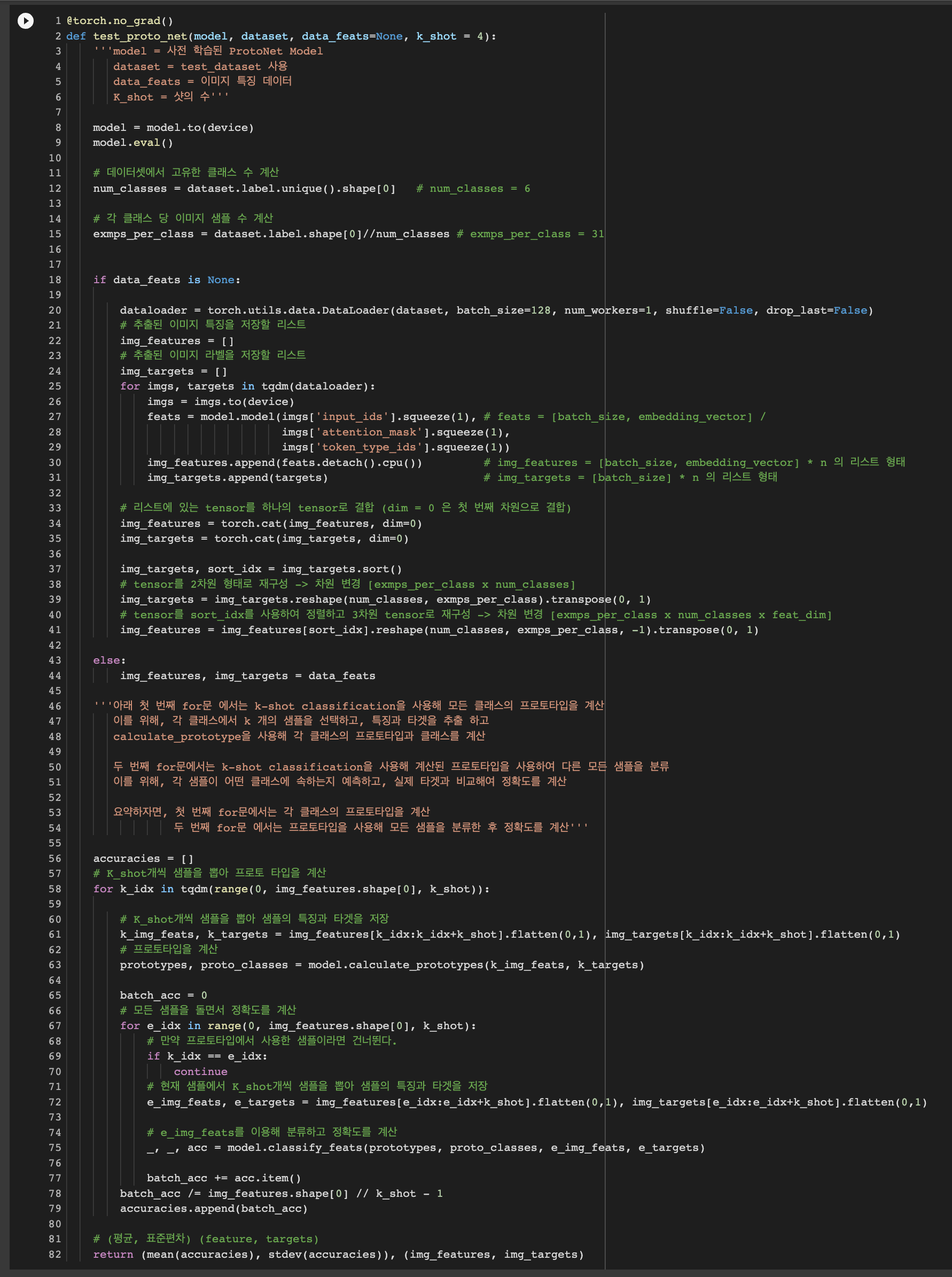
코드별 상세 구성은 코드 이미지 참고

-
pytorch Dataset과 batch_sampler를 통해 DataLoader 구성
-
split_batch 함수는 DataLoader를 통해 들어오는 data를 Query_set과 Support_set으로 분리해주기 위한 함수

- Bert-base 모델을 불러오고 학습을 위해 CLS 토큰만 필요하기 때문에 last_hidden_state[:,0,:] 만 return

- ProtoNet 모델로 batch로 data가 입력되면 Support_set을 통해 각 클래스별 Prototype을 구한 후 Query_set과의 유클리드 거리 계산을 통해 예측값과 정확도를 계산 후 Loss 역전파
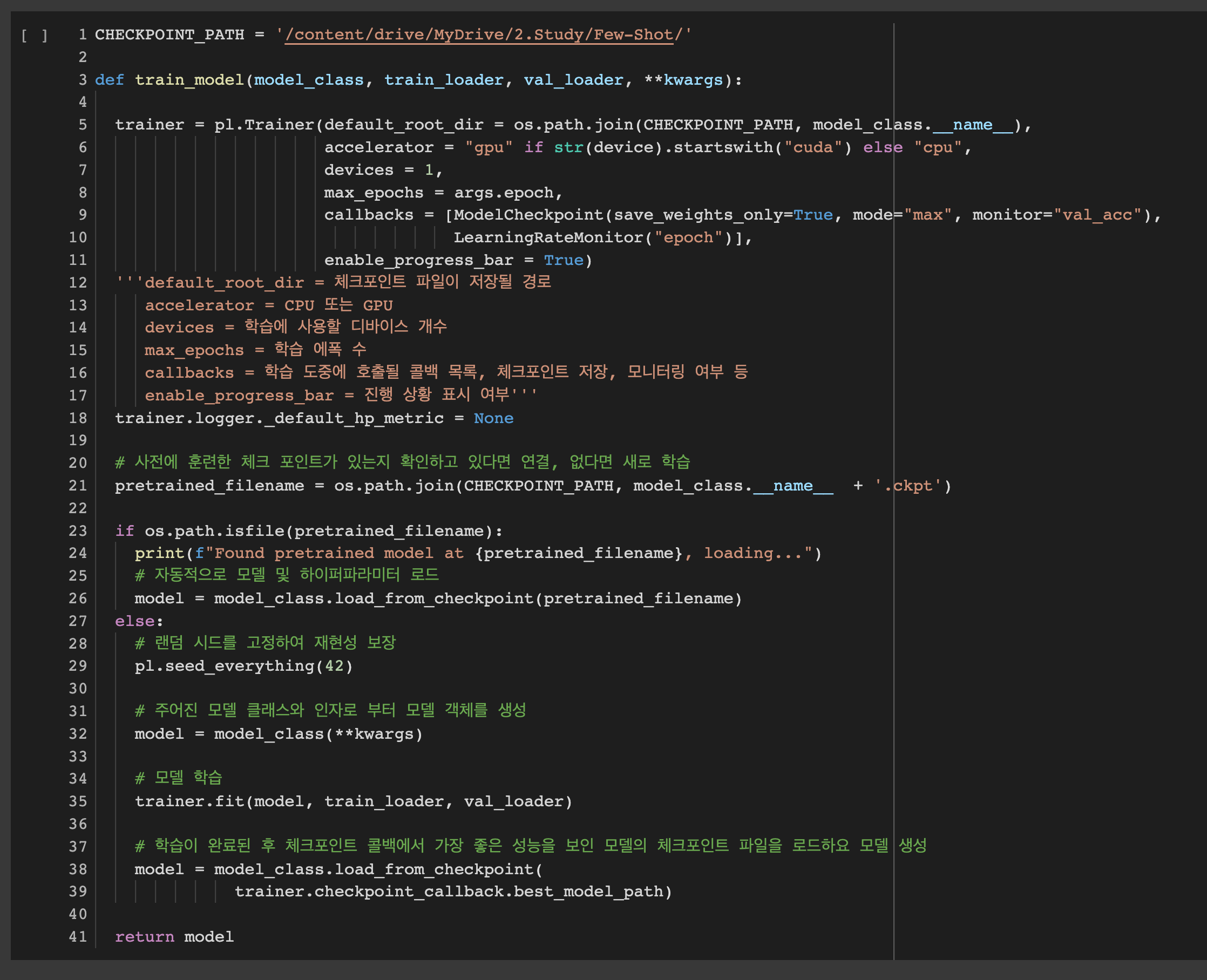
- Pytorch Lightning의 Trainer를 통해 모델을 학습

-
각 k-shot의 개수 별로 성능을 확인하기 위한 Test 함수
-
Test_set의 개수가 180개 밖에 안되기 때문에 k-shot의 크기를 16이상 했을 때, zero-division error가 발생하기 때문에 k-shot의 개수를 15 미만으로 잡고 성능확인을 진행하였다.

- 제 3의 Dataset인 SNIPS을 불러와 위와 동일하게 전처리를 진행하고 성능을 확인
- 성능의 결과는 Git에서 확인 가능
colab pro를 사용하고 50번 모델을 학습을 하였다.
기존 ATIS Dataset의 Test을 통해 검증해본 결과 k개의 개수가 증가할 수록 모델의 정확도가 증가하는 것을 볼 수 있다.
제 3의 Dataset인 SNIPS를 통해 검증해본 결과 동일하게 k개의 개수가 증가할 수록 모델의 정확도는 증가하는 추세를 보이나 모델이 한 번도 보지못한 Dataset이다 보니 정확도가 생각보다 낮은 것을 볼 수 있다.
epoch을 100 ~ 200으로 늘릴 경우 정확도의 변화가 있을 것으로 예상이 되나, 컴퓨팅 자원과 시간상 시도해 보지 못한 점이 아쉽다.
전체 코드와 코드별 설명은 Github에서 확인이 가능하다.
