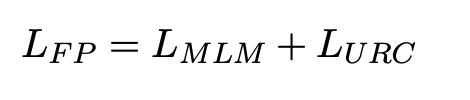Fine-grained Post-training for Improving Retrieval-based Dialogue Systems(2021) 논문 읽기①
0. Abstract
Retrieval-based dialogue systems(검색 기반 대화 시스템)은 Transformer(BERT)의 양방향 인코더 표현을 포함하는 pre-trained LM을 사용할 때 뛰어난 성능을 보여준다.
multi-turn response selection(다중 응답 대화) 동안 BERT는 여러 발화가 있는 context와 response간의 관계를 훈련하는데 중점을 둔다.
그러나, context에서 각 발화 간의 관계를 고려할 때 이런 훈련 방법은 불충분한 방법이다.
이로 인해 응답을 선택하는데 필요한 context flow를 완전하게 이해하지 못하는 문제가 발생한다.
이러한 문제를 해결하기 위해, 본 논문은 multi-turn dialogue의 특성을 반영하는 새로운 fine-grained post-training방법을 제안한다.
특히, 모델의 대화 세션에서 모든 short context-response 쌍을 훈련하여 발화 수준 상호 작용을 학습한다.
또한, 새로운 훈련 목표인 utterance relevance classification(발화 관련 분류)를 사용해 모델은 대화간의 의미론적 관련성와 일관성을 이해한다.
실험의 결과는 모델이 3가지 벤치마크 dataset에서 SOTA 성능을 달성한다는 것을 보여주며, 이는 fine-grained post-training이 response selection task에서 매우 효과적임을 시사한다.
1. Introduction
현재 인간과 자연스럽고 지속적으로 상호작용할 수 있는 대화 시스템을 구축하는 것이 상당히 인기있는 연구주제이다.
대화 시스템의 구현에는 generation-based(세대 기반 방식)과 retrieval-based(검색 기반 방식)의 두 가지 접근 방식이 있다.
검색 기반 방식은 응답 후보 중에서 올바른 응답을 선택하는 것을 목표로 한다.
초기 multi-turn response에서 대화 맥락을 응답과 일치시키기 위해 RNN을 활용할 것을 제안하였고, 이후 Attention 매커니즘의 등장에 따라 Attention 매커니즘을 사용하는 다중 턴 응답 모델들이 제안되어 왔다.
최근 transformer의 bidirectional encoder representation, BERT와 같은 pre-trained LM이 다중 응답 선택 모델애 적용되고 있으며 우수한 성능을 보여주고 있다.
최근에는 question answering과 dialogue systems과 같은 여러 자연어 처리 영역에서 사전 훈련된 언어 모델이 널리 사용되고 있다.
최고의 사전 훈련된 언어 모델 중 하나인 BERT는 처음에 대규모 및 일반 도메인 말뭉치에서 사전 훈련된 후 특정 작업에 적응하도록 미세 조정되고, 일반 데이터로 사전 훈련되기 때문에 도메인별 데이터에 적응하기 위한 post-training을 통해 성능을 향상시킬 수 있다.
이전의 일부 연구는 fine-tuning하기 전에 도메인 데이터를 학습할 수 있는 post-training 방법을 제안했다.
이전 연구에서 모델은 마스킹 언어 모델(MLM) 및 다음 문장 예측(NSP)과 동일한 pre-training objectives를 가진 도메인별 작업 데이터를 사용하여 post-training되었다.
본 논문에서는 대화에 적합한 새로운 post-training 방법을 개발하기 위해 간단하지만 강력한 fine-grained post-training을 2가지 제안한다.
첫 번째는, 전체 대화를 여러개의 short context-response 쌍으로 나누어 모델을 훈련시키는 것이다.
두 번째는, 주어진 발화와 대상 발화 사이의 관계를 보다 세분환된 레이블로 분류하는 utterance relevance classification(발화 관련 분류)라는 새로운 목표로 모델을 훈련시키는 것이다.
대화는 여러 발화와 하나의 발화에 응답을 포함하는 context로 구성된다.
post-training 동안 전체 context-response 쌍으로 학습하는 대신 여러 개의 새로운 short context-response쌍으로 나누어 학습하는 데 두 가지 이점이 있다.
첫째, 모델은 이전 훈련 방법에서 간과되었던 내부 발화 간의 상호작용을 학습할 수 있을 것이다.
둘째, 이전의 multi-trun response selection 모델은 여러 발화가 있는 context와 response사이의 관련 정보를 식별하는데 중점을 둔다.
관련 정보를 이해하기 위해 BERT는 context 내부의 발화 사이의 관계를 점진적으로 확장하고 학습하는 대신 context와 response 사이의 관계를 나타내는 입력으로 전체 context를 취한다.
전체 context와 response사이의 관계는 self-Attention을 통해서 학습될 수 있다.
하지만 대화 속 발언간의 관계는 쉽게 간과되기 때문에 이를 해결하기 위해 전체 대화를 여러 short context-response 쌍으로 나눈다.
각 쌍은 내부 발화로 구성되므로 모델은 발화 수준의 상호 작용을 학습할 수 있다.
두 번째 장점은 모델이 발화 간의 관계를 더 정확하게 포착할 수 있다는 것이다.
일반적으로 response와 관련된 발화는 response에 가깝게 위치해있으며, short context-response 쌍은 응답에 가까운 발화로만 구성되므로 더 세분화된 훈련이 가능하다.
fine-grained post-training의 또다른 전략은 발화 관련 분류(URC)라고 불리는 새로운 훈련 목표를 사용하는 것이다.
BERT에 사용되는 NSP의 경우, 모델은 대상 발화가 무작위인지 다음 발화인지 구별한다.
타 논문에서 언급한 바와 같이, NSP로 훈련된 모델은 발화의 의미적론적인 의미를 구별하는 topic prediction을 쉽게 학습할 수 있으나 선택한 발화가 연속적인지 여부를 구별하는 일관성 예측이 부족하다.
타 논문에서 사용되는 문장 순서 예측(SOP)의 경우, 두 시퀀스의 순서가 훈련되기 때문에 발화 간의 일관성이 잘 학습이되지만, 두 시퀀스가 의미적으로 유사하기 때문에 주제 예측은 상대적으로 불충분하다.
multi-turn dialogue에서 의미론적으로 유사한 발화를 구별하고 선택된 발화가 연속적인지 여부를 결정하는 것이 중요하므로, 주제와 일관성을 학습하기 위해 대상 발화를 세 가지 범주(랜덤, 의미론적으로 유사, 다음)로 분류하는 URC를 제안한다.
본 논문의 연구의 기여는 아래와 같이 요약할 수 있다.
-
fine-grained post-training 중 short context-response 쌍 훈련을 통해 모델은 기존 방법에서 쉽게 간과할 수 있는 내부 발화 간의 상호작용을 효과적으로 학습한다. 그로인해 response selection의 성능이 크게 향상 된다.
-
새로운 URC를 고안함으로써, 본 논문은 발화 간의 의미론적 관련성과 일관성을 모두 측정하는 모델의 능력을 향상시켜 적절한 응답을 선택하도록 모델을 개선한다.
3가지 벤치마크(Ubuntu, Douban, E-commerce)에서 성능을 개선해 SOTA 성능을 달성하였다.
구체적으로, 우리 모델은 Ubuntu Corpus V1, Douban Corpus 및 E-commerce Corpus에서 이전의 최첨단 방법에 비해 R10@1에서 각각 2.7%p, 0.6%p, 9.4%p의 절대적인 개선을 달성했다.
2. Related Work
대화 시스템을 구축하기 위한 기존 방법은 검색 기반 접근법과 세대 기반 접근법의 두 그룹으로 분류할 수 있다.
최근 연구는 multi-turn dialogue context가 제공될 때 시스템이 가장 적절한 응답을 선택하는 multi-turn retrieval dialogue 시스템에 초점을 맞추고 있다.
Lowe은 Ubuntu Internet Relay Chat(IRC) Corpus V1이라는 새로운 벤치마크 데이터 세트와 RNN 기반 baseline model을 제안했다.
Kadlec은 LSTM과 CNN을 인코더로 사용하여 컨텍스트와 응답을 효과적으로 인코딩하려는 이중 인코더 기반 모델을 제안했다.
Attention 메커니즘의 등장으로 Attention 메커니즘을 응답 선택 대화 시스템에 적용한 deep attention matching network와 같은 모델이 제안되었다.
Chen과 Wang(2019)은 자연어 추론 모델을 응답 선택 작업에 적용했다.
Tao는 여러 상호 작용 블록을 통해 context와 response 간의 깊은 상호 작용을 수행했다.
Yuan는 multi-hop selector로 대화 context 정보를 제어하여 성능을 향상시켰다.
pre-trained LM은 응답 선택에서 인상적인 성능을 보여주었으며 그 중 하나인 BERT는 다중 레이어를 갖는 bidirectional transformer-based encoder이다.
본 논문은 layer의 수, Attention head의 수, hidden state size는 각 12, 12, 768인 BERT를 사용한다.
pre-trained LM에 대한 다양한 훈련 목표가 있다.
BERT는 MLM과 NSP의 두 가지 교육 목표를 사용한다.
전자(MLM)는 모델이 예측한 토큰의 15%를 무작위로 마스킹해 모델이 주어진 텍스트의 전반적인 contextual representation(상황적 표현)을 학습하는 것을 목표로 한다.
후자(NSP)의 방법에서, 모델은 두 개의 텍스트 sequences A와 B가 주어지며, 이 모델은 sequences B가 sequences A 다음 sequences인지 여부를 결정하도록 훈련된다.
모델은 특수 토큰 SEP로 분리된 sequences A와 B의 input을 취한다.
이 모델은 sequences A는 0, sequences B는 1로 segment embedding을 사용하고 그런 다음 CLS 토큰을 사용하여 모델은 sequences A와 B 사이의 관계를 예측한다.
AL-BERT의 경우 는 훈련 목표로 NSP 대신 문장 순서 예측(SOP)을 사용하였으며, SOP는 sequences A와 B의 순서가 올바른지 또는 스왑 되었는지 여부를 구분한다.
모델이 특정 영역을 이해하는 데 도움이 되는 post-training 방법은 응답 선택 과제에 도입되었다.
도메인 adaptation 외에도, post-training 방법은 NSP와의 대화 세션에서 두 sequences 간의 관계를 학습하기 때문에 data augmentation의 이점이 있다.
그러나 이 방법은 BERT의 pre-training 방법을 따를 뿐이므로 대화 특성을 반영하지 않는다.
이 문제를 해결하기 위해, 우리는 multi-turn dialogue에 적합한 새로운 post-training 방법을 제안하며 이 방법은 이전의 post-training에 비해 더 나은 성능을 달성했다.
3. Model
3-1. Problem Formalization
데이터셋 는 context , response , truth label 로 구성된 N의 삼중 집합이라고 가정한다.
context는 일련의 발화를 나타내며 이다. 여기서 은 최대 context의 길이이다.
j번째 발화 는 최대 sequence의 길이를 뜻하는 Token이 포함되어 있다.
각의 response 는 단일 발화이며, 은 주어진 삼중 truth label이며 여기서 이다. 이는 가 context 에 대한 올바른 반응임을 나타내며, 그렇지 않을 경우 으로 나타난다.
이 Task는 에 대해 일치하는 모델 을 찾는 것이다.
와 의 일치도는 주어진 context-response 쌍()에 대해 를 통해 구한다.
3-2. Fine-tuning BERT for Response Selection
본 연구는 context와 response 간의 관계를 분석하는 응답 선택 과제에 대한 BERT를 fine-turning하기 위한 이진 분류를 기반으로 한다.
기존 BERT 모델의 input의 형식(x)는 ([CLS], sequence A, [SEP], sequence B, [SEP])이며, 여기서 [CLS]와 [SEP]는 각각 CLS 및 SEP 토큰이다.
context-response 쌍의 일치 정도를 측정하기 위해 sequence A를 context로, sequence B를 response로 사용하여 input을 구성한다.
또한 발화 토큰(EOU)의 끝은 context에서 구별하기 위해 각 발화의 끝에 배치된다.
응답 선택을 위한 BERT의 input 형식은 아래와 같다.
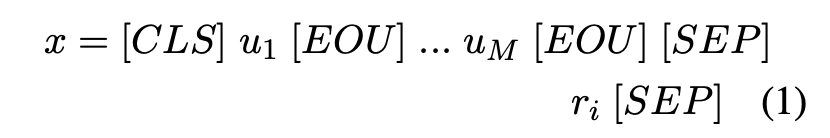
의 값은 position, segment, token embedding의 합을 통해 input vector가 된다.
BERT의 transformer block은 self-Attention 매커니즘을 통해 context가 input표현과 response의 Cross Attention을 계산한다.
그런 다음, BERT에서 첫 번째 입력 Token의 hidden vectordls 가 context-response 쌍의 aggregate representation으로 사용된다.
context와 response 사이의 일치도인 최종 점수 는 단층 신경망을 통해 를 통과하여 얻는다.
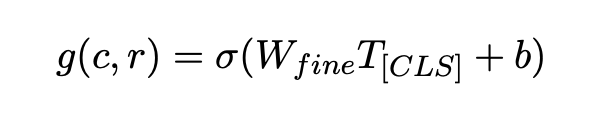
위 식에서 은 fine-turning을 위한 task-specific trainable parameter이며, 최종적으로 Cross-entropy loss function을 사용하여 업데이트 된다.
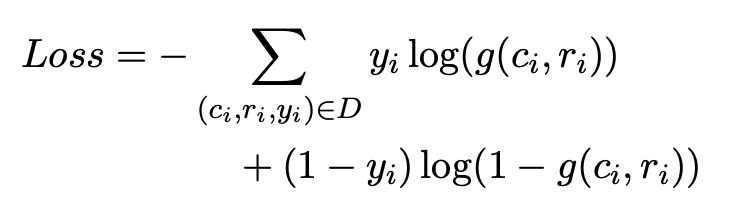
3-3. Fine-grained Post-training
multi-turn dialogue 정보를 효과적으로 파악하여 적절한 응답을 선택하는 능력을 향상시키기 위해, 우리는 아래 그림과 같이 간단하지만 강력한 fine-grained post-training을 제안한다.
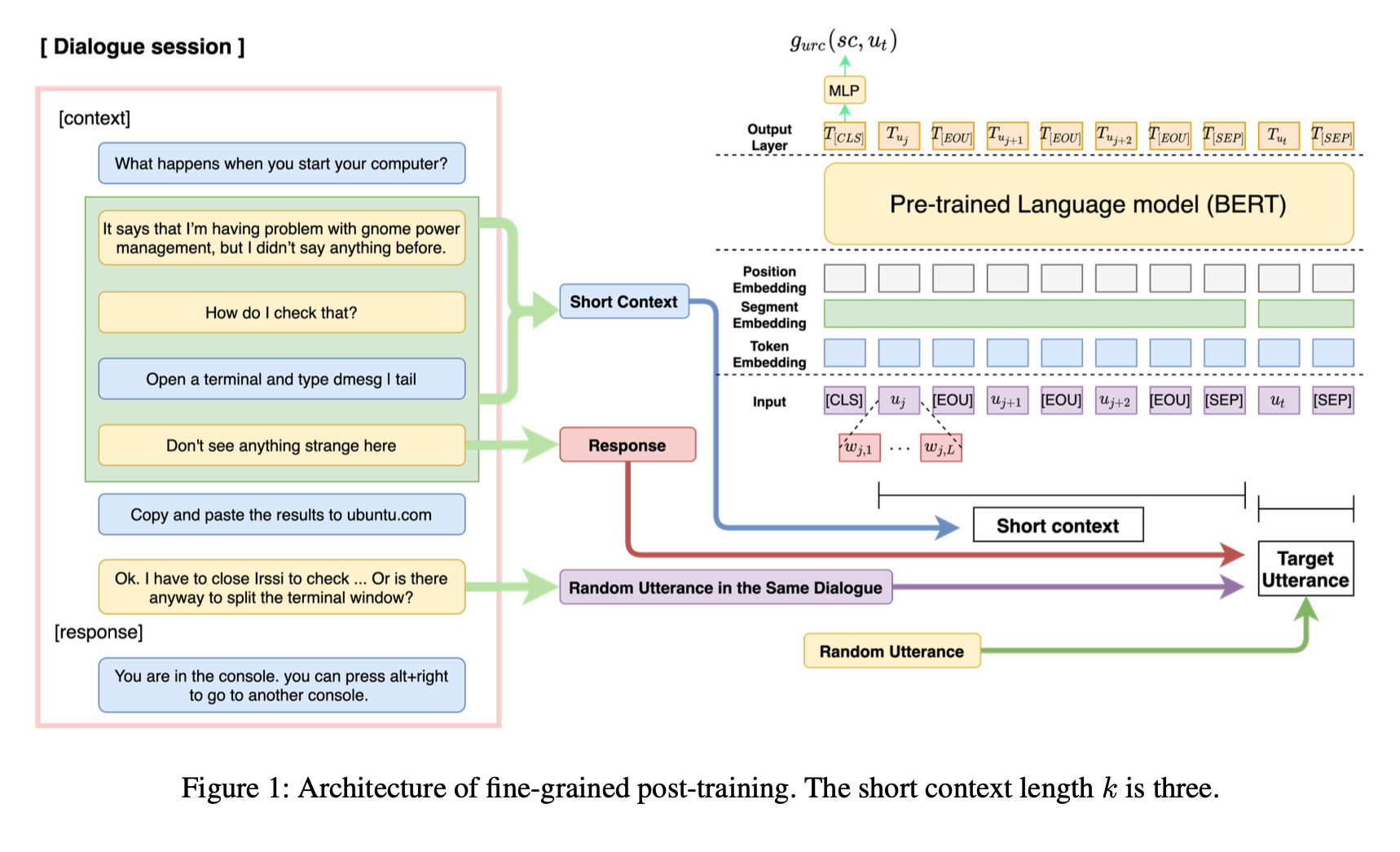
fine-grained post-training에는 2가지 학습 전략이 있다.
전체 대화 세션은 여러 개의 short context-response 쌍으로 나뉘며, URC는 training objectives 중 하나로 사용된다.
전자 전략을 통해 모델은 대화의 관련 내부 발화의 상호 작용을 학습하고, URC를 통해 발화들 사이의 의미론적 관련성과 일관성을 배운다.
3-3-1. Short Context-response Pair Training
utterance level interaction을 학습하기 위해 대화 세션의 모든 발화를 사용하여 여러 개의 short context-response 쌍을 구성하여 모델을 post-training한다.
모든 발언을 response로 간주하고 이전 발언 를 short context으로 간주한다.
short context는 대화 세션의 평균 발화 수보다 적은 수의 발화를 포함한다.
각각의 short context-response 쌍은 내부 발화 상호 작용을 학습하도록 훈련되어 최종적으로 모델이 대화 세션의 모든 발화 사이의 관계를 이해할 수 있게 하며, context가 짧은 길이로 구성되기 때문에 모델이 response와 밀접하게 관련된 발화의 상호 작용을 학습할 수 있다.
3-3-2. Utterance Relevance Classification
NSP의 목표는 발언 간의 일관성을 포착하기에 부적절하다. 왜냐하면 NSP는 주로 임의의 발화와 다음 발화 사이를 분류하여 주제의 의미론적 관련성을 학습하기 때문이다.
SOP를 목적 함수로 사용하면 모델이 유사한 주제를 가진 두 발화의 일관성을 학습하기 때문에 의미론적 관련성을 구별하는 능력이 감소한다.
대화에서 의미론적 관련성과 일관성을 모두 핟습하기 위해 아래 그림과 같이 URC(발화 관련 분류)라고 하는 새로운 tarining objective를 제안한다.
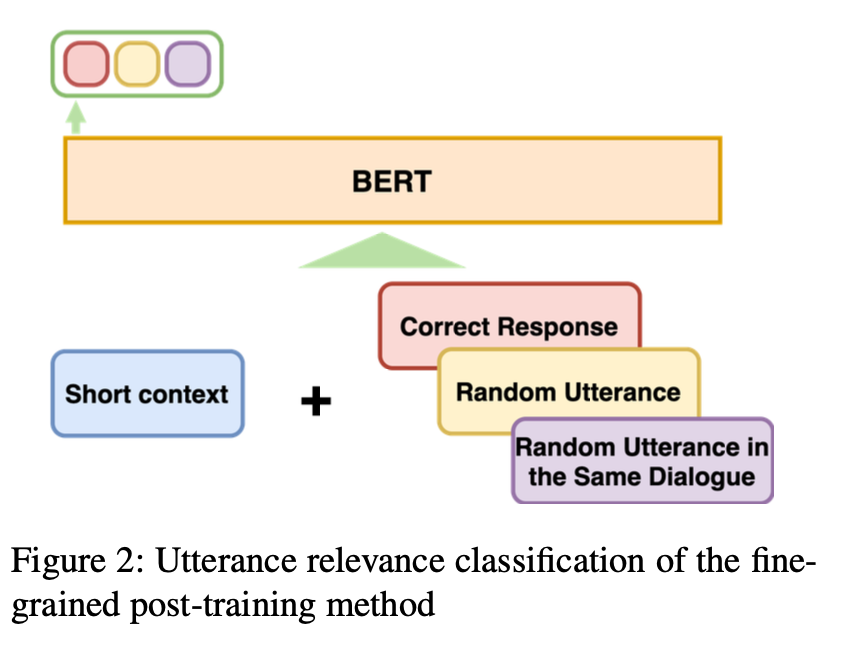
URC는 주어진 short context에 대한 대상 발화를 세 개의 레이블 중 하나로 분류한다.
첫 번째 레이블은 임의의 발화이다.
두 번째 레이블은 response가 아닌 동일한 대화 세션에서 무작위로 샘플링한 발화이다. 비록 동일한 대화 세션의 발언이 올바른 response와 유사한 주제를 가지고 있지만 일관성 예측에는 부적절하다.
세 번째 레이블은 올바른 응답이 선택 된다.
모델은 무작위 발화와 정답 사이의 분류를 수행하여 topic prediction을 학습하고, 모델은 동일한 대화 세션에서 무작위 발화와 정답을 분류하여 일관성 예측을 한다.
short context와 대상 발화의 관계를 3가지 경우로 분류함으로써 모델은 대화 세션의 의미 관련성 정보와 일관성 정보를 모두 학습할 수 있다.
3-3-3. Training Setup
fine-grained post-training(FP)의 방법은 [Figure 1]에 나와 있다.
첫째, 대화 세션 가 주어지면 연속 발화를 선택하고 short context-response 쌍 의 context length는 가 된다.
이 모델은 short context 과 주어진 대상 발화 사이의 관계를 분류한다.
대상 발화는 (1) 무작위 발화 , (2) 동일한 대화 세션 에 대한 무작위 발화, (3) 올바른 response ( 및 ) 중 3 가지 옵션 중 하나일 수 있다.
fine-grained post-training의 input sequence 는 아래 그림과 같이 나타낸다.
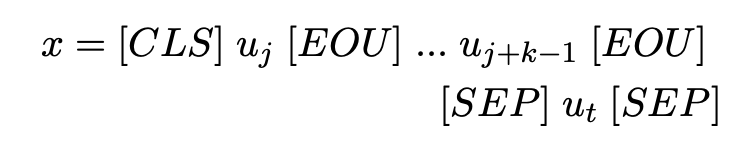
aggregate representation는 가 사용된다.
최종 점수를 뜻하는 는 단층 퍼셉트론을 통해 를 통과해 얻어지며, short context와 대상 발화 간의 관련성 정도는 score를 통해 얻어진다.
URC loss를 계산하기 위해, 아래와 같은 공식화된 cross-entropy loss function을 사용한다.
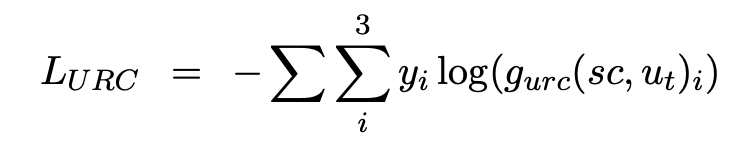
제안된 모델을 훈련하기 위해 MLM과 URC를 함께 사용한다.
MLM의 경우, 우리는 BERT와 달리 RoBERTa가 제안한 동적 마스킹 기법을 적용한다.
모델은 미리 결정된 토큰을 마스킹하여 학습하는 대신 매번 랜덤 토큰을 마스킹하여 학습하기 때문에 더 많은 상황 표현을 학습할 수 있기 때문이다.
모델을 최적화하기 위해 MLM과 URC의 cross-entropy loss를 사용하며 아래와 같이 공식화 된다.