Encoder는 2개의 서브층으로 구성되어 있고
Decoder는 3개의 서브층으로 구성되어 있습니다.
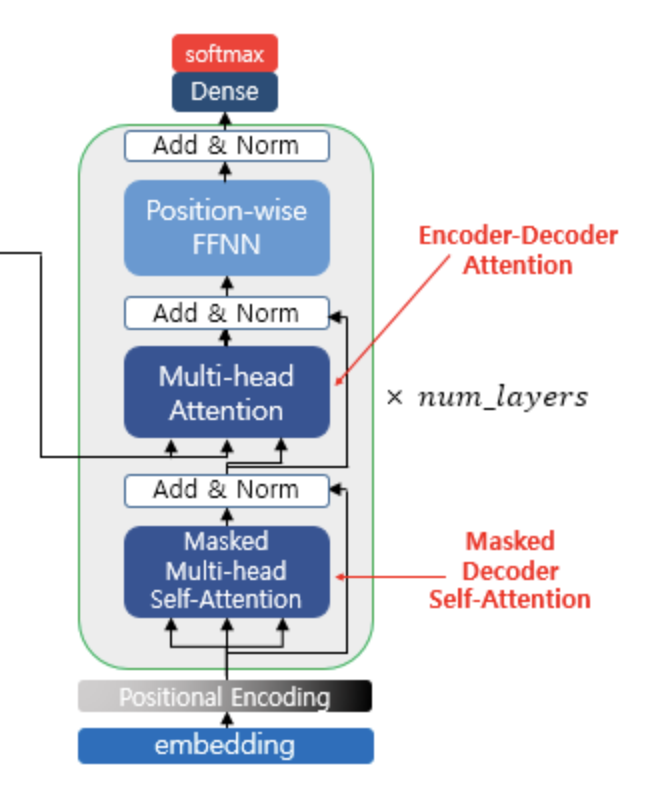
여기서 Decoder의 1번째와 2번째 서브층은 모두 Multi-head Attention입니다.
-
1번째 서브층은 Mask의 인자값으로 Look-ahead Mask
- why? Masked Self-Attention을 수행하기 때문
-
2번째 서브층은 Mask의 인자값으로 Padding Mask
-
3번째 서브층은 Position-Wise FFNN 연산을 수행하며
-
모든 서브층까지 연산된 이후에는 Dropout, Residual Connection, Layer Norm 이 수행됩니다.
Decoder 구현하기
def decoder_layer(dff, d_model, num_heads, dropout, name="decoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
enc_outputs = tf.keras.Input(shape=(None, d_model), name="encoder_outputs")
# 룩어헤드 마스크(첫번째 서브층)
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name="look_ahead_mask")
# 패딩 마스크(두번째 서브층)
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 멀티-헤드 어텐션 (첫번째 서브층 / 마스크드 셀프 어텐션)
attention1 = MultiHeadAttention(
d_model, num_heads, name="attention_1")(inputs={
'query': inputs, 'key': inputs, 'value': inputs, # Q = K = V
'mask': look_ahead_mask # 룩어헤드 마스크
})
# 잔차 연결과 층 정규화
attention1 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention1 + inputs)
# 멀티-헤드 어텐션 (두번째 서브층 / 디코더-인코더 어텐션)
attention2 = MultiHeadAttention(
d_model, num_heads, name="attention_2")(inputs={
'query': attention1, 'key': enc_outputs, 'value': enc_outputs, # Q != K = V
'mask': padding_mask # 패딩 마스크
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention2 = tf.keras.layers.Dropout(rate=dropout)(attention2)
attention2 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention2 + attention1)
# 포지션 와이즈 피드 포워드 신경망 (세번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention2)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(outputs + attention2)
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)Decoder 쌓기
Decoder역시 num_layer의 개수 만큼 층을 쌓아야 합니다.
def decoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name='decoder'):
inputs = tf.keras.Input(shape=(None,), name='inputs')
enc_outputs = tf.keras.Input(shape=(None, d_model), name='encoder_outputs')
# 디코더는 룩어헤드 마스크(첫번째 서브층)와 패딩 마스크(두번째 서브층) 둘 다 사용.
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name='look_ahead_mask')
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 디코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = decoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name='decoder_layer_{}'.format(i),
)(inputs=[outputs, enc_outputs, look_ahead_mask, padding_mask])
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)
Transformer 구현하기
Encoder의 출력은 Decoder에서 Encoder-Decoder Attention에서 사용되기 위해 Decoder로 전달해줍니다.
그리고 Decoder의 끝단에는 다중 클래스 분류 문제를 풀 수 있도록, vocab_size 만큼의 뉴런을 가지는 출력층을 추가해줍니다.
def transformer(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name="transformer"):
# 인코더의 입력
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 디코더의 입력
dec_inputs = tf.keras.Input(shape=(None,), name="dec_inputs")
# 인코더의 패딩 마스크
enc_padding_mask = tf.keras.layers.Lambda(
create_padding_mask, output_shape=(1, 1, None),
name='enc_padding_mask')(inputs)
# 디코더의 룩어헤드 마스크(첫번째 서브층)
look_ahead_mask = tf.keras.layers.Lambda(
create_look_ahead_mask, output_shape=(1, None, None),
name='look_ahead_mask')(dec_inputs)
# 디코더의 패딩 마스크(두번째 서브층)
dec_padding_mask = tf.keras.layers.Lambda(
create_padding_mask, output_shape=(1, 1, None),
name='dec_padding_mask')(inputs)
# 인코더의 출력은 enc_outputs. 디코더로 전달된다.
enc_outputs = encoder(vocab_size=vocab_size, num_layers=num_layers, dff=dff,
d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[inputs, enc_padding_mask]) # 인코더의 입력은 입력 문장과 패딩 마스크
# 디코더의 출력은 dec_outputs. 출력층으로 전달된다.
dec_outputs = decoder(vocab_size=vocab_size, num_layers=num_layers, dff=dff,
d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[dec_inputs, enc_outputs, look_ahead_mask, dec_padding_mask])
# 다음 단어 예측을 위한 출력층
outputs = tf.keras.layers.Dense(units=vocab_size, name="outputs")(dec_outputs)
return tf.keras.Model(inputs=[inputs, dec_inputs], outputs=outputs, name=name)
딥러닝 지식의 백지에서 깜지까지