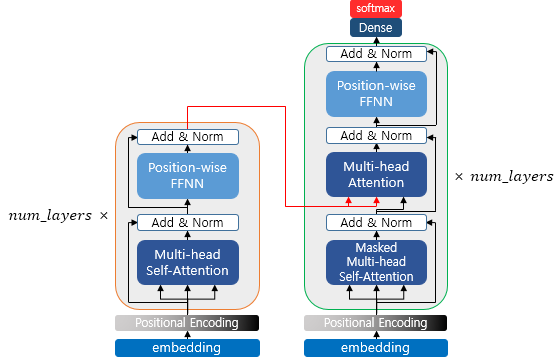
이전까지 Transformer의 Encoder의 구성에 대해서 살펴보았습니다.
Encoder의 경우 num_layer의 개수 만큼 연산을 순차적으로 한 후 마지막 층의 Encoder의 출력을 Decorder에게 전달하게 됩니다.
Decoder의 연산 또한 num_layer만큼 연산을 진행하는데 이때 마다, Encoder가 보낸 추력 값을 각 Decoder 연산층에서 사용하게 됩니다.
이제는 Encoder를 넘어 Decoder에서 어떤 방식으로 작동이 되는지 알아보도록 하겠습니다.
Self-Attention과 Look-ahead mask
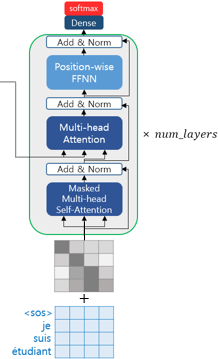
위 그림과 같이 Decoder도 인코더와 동일하게 임베딩 층과 포지셔널 인코딩을 거친 후의 문장 행렬이 입력됩니다.
Transformer 또한 seq2seq와 마찬가지로 교사 강요(Teacher Forcing)을 사용하여 훈련되므로 학습 과정에서 디코더는 번역할 문장에 해당되는 <sos> je suis étudiant의 문장 행렬을 한 번에 입력받습니다.
그리고 디코더는 이 문장 행렬로부터 각 시점의 단어를 예측하도록 훈련됩니다.
-
seq2seq의 Decoder에 사용되는 RNN 계열의 신경망은 입력 단어를 매 시점마다 순차적으로 입력받으므로 다음 단어 예측에 현재 시점을 포함한 이전 시점에 입력된 단어들만 참고할 수 있습니다.
- suis를 예측해야 하는 시점일 경우, RNN 계열의 seq2seq의 Decoder라면 현재까지 Decorder에 입력된 단어는 와 je뿐일 것입니다.
-
반면, Transforer는 문장 행렬로 입력을 한 번에 받으므로 현재 시점의 단어를 예측하고자 할 때, 입력 문장 행렬로부터 미래 시점의 단어까지도 참고할 수 있는 현상이 발생합니다.
- 동일하게 suis를 예측해야 하는 시점일 경우, Transformer는 이미 문장 행렬로 <sos> je suis étudiant를 입력 받을 것 입니다.
이처럼 Transformer의 Decoder는 현재 시점의 예측에서 현재 시점 보다 미래에 있는 단어들을 참고하지 못 하도록 룩-어헤드 마스크(Look-ahead mask)를 사용합니다.
즉, 미래 문장에 대한 미리 보기 방지용 마스크 입니다.
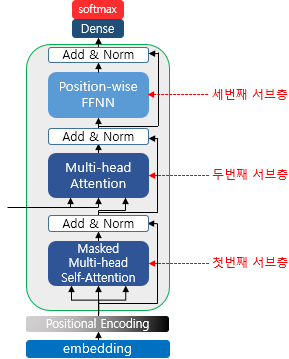
위 그림과 같이 룩-어헤드 마스크(Look-ahead mask)는 Decoder의 첫 번째 서브층에서 이루어지게 됩니다.
Decoder의 첫 번째 서브층의 Multi-head Attention은 Encoder의 첫 번째 서브층의 Multi-head Attention과 동일한 연산을 수행합니다.
다만 차이점은, Attention Score 행렬에서 마스킹을 적용한다는 점만 다릅니다.
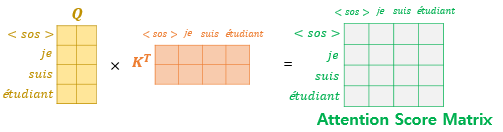
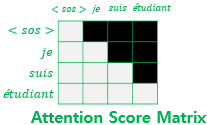
Self-Attention을 통해 Attention Score 행렬을 얻고 난 후 자기 자신보다 미래의 있는 단어들을 참고하지 못하도록 마스킹을 진행합니다.
마스킹 후 Attention Score 행렬의 각 행을 보면 자기 자신과 이전의 단어들만 참고할 수 있도록 되어 있습니다.
이 외에는 Self-Attention이라는 점과 Multi-head Attention을 수행한 다는 점에서 Encoder와 동일합니다.
Look-ahead mask 구현
Look-ahead mask는 padding mask와 동일하게 앞서 구현한 scaled dot-product Attention 함수에 mask라는 인자로 구현이 됩니다.
- padding mask를 써야하는 경우, scaled dot-product attention 함수에 padding mask를 전달하고
- Look-ahead mask를 써야하는 경우, scaled dot-product attention 함수에
Look-ahead mask를 전달하면 됩니다.
def create_look_ahead_mask(x):
seq_len = tf.shape(x)[1]
look_ahead_mask = 1 - tf.linalg.band_part(tf.ones((seq_len, seq_len)), -1, 0)
padding_mask = create_padding_mask(x)
return tf.maximum(lood_ahead_mask, padding_mask)print(create_look_ahead_mask(tf.constant([[1, 2, 3, 4, 5]])))tf.Tensor(
[[[[0. 1. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 0. 1. 1.]
[0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0.]]]], shape=(1, 1, 5, 5), dtype=float32)위 코드의 결과값 처럼 우측 상단은 1로 채워졌습니다.
1로 설정이 되는 부분이 Look-ahead mask 입니다.
하지만 이전에 padding maks가 추가가 되었다면 해당 부분도 동일하게 1로 채워지게 될 것입니다.
print(create_look_ahead_mask(tf.constant([[0, 5, 1, 5, 5]])))tf.Tensor(
[[[[1. 1. 1. 1. 1.]
[1. 0. 1. 1. 1.]
[1. 0. 0. 1. 1.]
[1. 0. 0. 0. 1.]
[1. 0. 0. 0. 0.]]]], shape=(1, 1, 5, 5), dtype=float32)Encoder-Decoder Attention
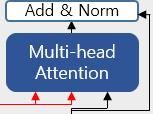
Encoder-Decoder Attention은 Decoder의 2번째 서브층에 존재합니다.
이번 층은 Multi-head Attention을 수행한 다는 점에서는 이전의 Attention들과 같으나, Self-Attention은 아닙니다.
Self-Attention은 Query, Key, Value가 같은 경우를 말하는데 Encoder-Decoder Attention은 Query가 Decoder에서 넘어온 행렬인 반면, Key와 Value는 Encoder의 행렬이기 때문입니다.
- 각 서브층에서의 Q, K, V의 관계 정리
- Encoder의 1번째 서브층 : Query = Key = Value
- Decoder의 1번째 서브층 : Query = Key = Value
- Decoder의 2번째 서브층 : Query : Decoder의 행렬 / Key = Value : Encoder의 행렬
위 그림에서 보면 빨간색 2개의 화살표는 각각 Encoder에서 넘어온 Key, Value값의 행렬을 의미합니다.
반면 검은색 1개의 화살표는 Decoder의 1번째 서브층에서 넘어온 Query값의 행렬를 의미합니다.
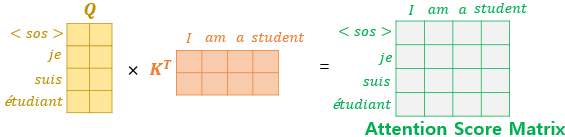
Query가 Decoder 행렬, Key가 Encoder 행렬일 때, Attention Score 행렬을 구하는 과정은 다음과 같으며 그 외에 Multi-head Attention을 수행하는 과정은 다른 Attention들과 동일합니다.
Transformer의 Attention 정리
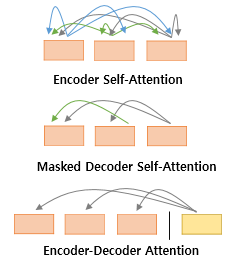
Transformer에는 총 3가지의 Attention이 이루어집니다.
모두 Multi-head Attention을 수행하고, 해당 함수 내부에서 Scaled dot-product Attention 함수를 호출하는데 각 함수에 전달하는 마스킹은 아래와 같습니다.
-
Encoder의 Self-Attention : padding mask를 전달
-
Decoder의 1번째 서브층의 Masked Self-Attention : Look-ahead mask를 전달
-
Decoder의 2번째 서브층의 Encoder-Decoder Attention : padding mask를 전달
