이번 시간에는 스케일드 닷-프로덕트 어텐션(Scaled dot-product Attention)에 대해서 알아보겠습니다.
닷-프로덕트 어텐션이란?
어텐션은 다양한 종류들이 존재 합니다. 그 중 가장 기본적인 Attention이 바로 닷-프로덕트 어텐션 입니다.
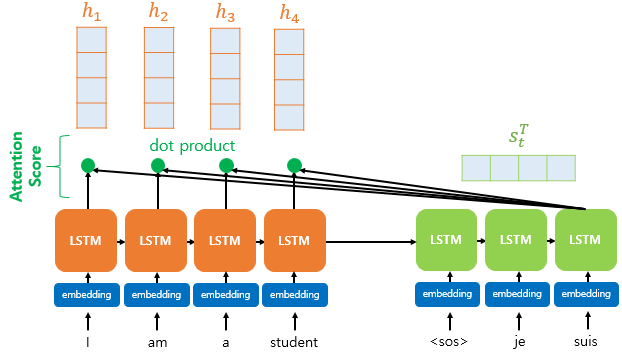
이전 seq2seq에서 Decoder는 2가지(이전 시점의 hidden state, 이전 시점의 출력)를 통해 현재 시점의 hidden state를 계산했습니다.
이때, Attention 모델에서는 계산을 위해 t시점의 Attention값이 필요하게 됩니다.
따라서 Attention model은 seq2seq + Attention값인 모델입니다.
즉, Attention 모델에서 핵심은 이 Attention을 어떻게 구하는가가 핵심이며, 이 Score를 구하는 방법에 따라서 닷-프로덕트 어텐션 / 루옹 어텐션 / 바다나우 어텐션 등으로 종류가 구분되게 됩니다.
위의 과정을 통해 Step 1. Attention Score를 구하게 됩니다.
Step 2. Softmax를 통해 Attention Distribution(분포)를 구한다.
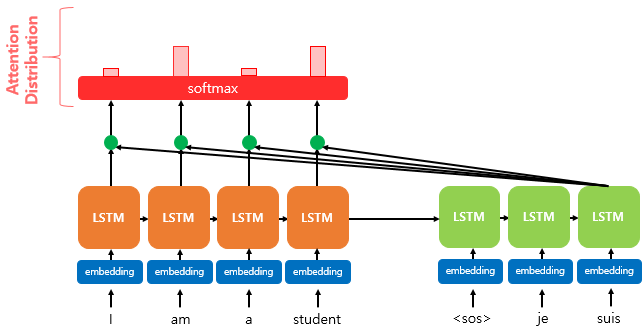
step 1을 통해서 구한 모든 Attention Score의 모음에 Softmax를 적용해 확률 분포를 얻어 내게 됩니다.
이를 통해 얻어낸 분포를 Attention Distribution이라고 하며
각각의 값을 Attention Weightfkrh gkqslek.
Step 3. Attention Weight와 Encoder의 hidden state를 가중합하여 Attention Value를 구한다.
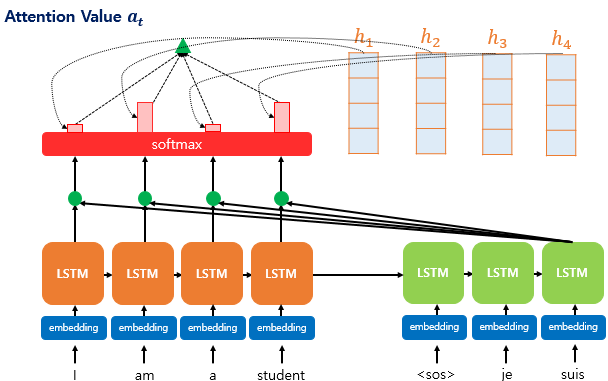
구해낸 Attention Distribution의 각 Attention Weight들을 해당 시점의 Encoder의 hidden state와 더해 나오는 Context Vector 값을 구한다.
Context Vector는 Encoder의 문맥을 내포하고 있다.
Step 4. Attention Value와 현재 시점 Decoder의 hidden state를 연결한다.
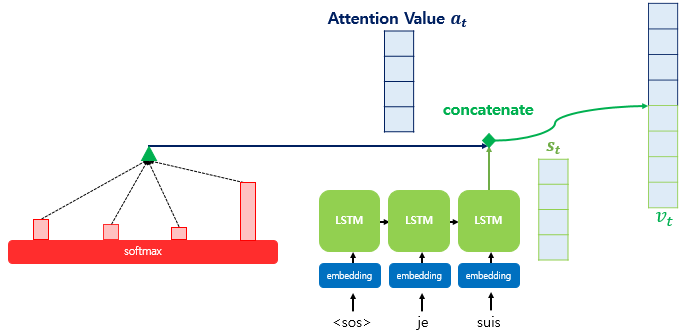
최종적으로 구해낸 Context Vector를 현재 시점의 Decoder의 hidden state를 결합(concatenate)를 수행한 최종 벡터 Vt는 Decoder의 예측값인 y_hat을 도출하기 위한 연산의 값으로 사용된다.
스케일드 닷-프로덕트 어텐션
트랜스포머에서는 어텐션 챕터에 사용했던 내적만을 사용하는 어텐션 함수 가 아니라 여기에 특정값으로 나눠준 어텐션 함수인 를 사용합니다.
이러한 함수를 사용하는 어텐션을 어텐션 챕터에서 배운 닷-프로덕트 어텐션(dot-product attention)에서 값을 스케일링하는 것을 추가하였다고 하여 스케일드 닷-프로덕트 어텐션(Scaled dot-product Attention)이라고 합니다.
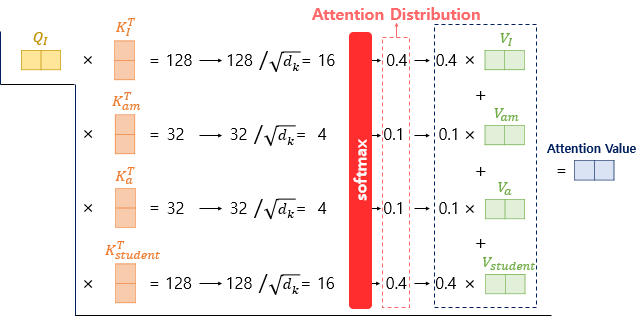
-
각 Q벡터는 모든 K벡터에 대해서 어텐션 스코어를 구하고,
-
어텐션 분포를 구한 뒤에 이를 사용하여 모든 V벡터를 가중합하여 어텐션 값 또는 컨텍스트 벡터를 구하게 됩니다.
-
그리고 이를 모든 Q벡터에 대해서 반복합니다.
행렬연산으로 일괄 처리하기
위에서 설명한 이미지와 글은 벡터 연산으로 계산한 것 입니다.
하지만, 행렬 연산을 사용하면 일관 계산이 가능해 더 빠르게 계산이 됩니다.
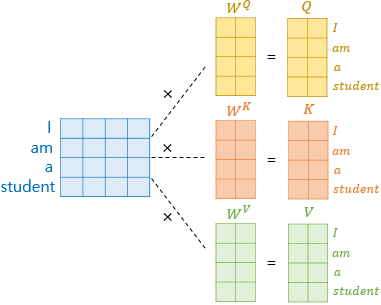
1. 문장 행렬에 가중치 행렬을 곱하여 Q,K,V 행렬을 각각 구합니다.
2. Q행렬을 K행렬을 전치한 행렬과 곱해 Attention Score를 구한다.
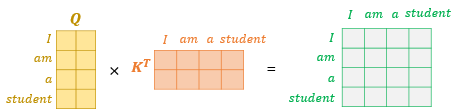
다시 말해 위의 그림의 결과 행렬의 값에 전체적으로 를 나누어주면 이는 각 행과 열이 어텐션 스코어 값을 가지는 행렬이 됩니다.
예를 들어 I 행과 student 열의 값은 I의 Q벡터와 student의 K벡터의 어텐션 스코어 값입니다.
3. Attention Score 행렬에 Softmax 함수를 사용하고, V행렬을 곱해 Attention Distribution을 구한다.
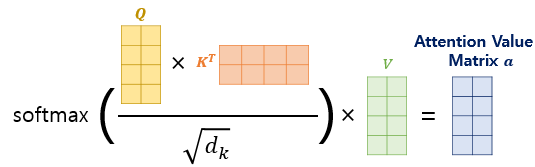
위의 그림은 계산식으로 나타내면 아래와 같고
실제 Transformer 논문에 기재된 수식과 정확하게 일치하게 됩니다.
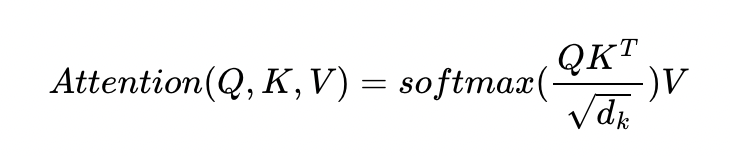
이 수식은 내적(Dot-Product)을 통해 단어 벡터 간 유사도를 구한 후에,
특정 값을 분모로 나눠주는 방식으로 Q와 k의 유사도를 구하였다고 하여 Scaled Dot Product Attention 이라고 합니다.
