Transformer - 2. Attention과 Self-Attention (by WikiDocs)
Transformer Attention의 종류
Transformer에 사용되는 Attention은 3가지가 있습니다.
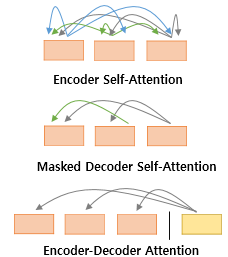
-
Self-Attention @ Encoder (첫 번째 그림)
-
Self-Attention with mask @ decoder (두 번째 그림)
-
Attention from Encoder @ decoder (세 번째 그림)
첫번째 그림인 Self-Attention은 Encoder에서 이루어지지만,
두번째 그림인 Self-Attention과 세번째 그림인 Encoder-Decoder Attention은 디코더에서 이루어집니다.
셀프 어텐션은 본질적으로 Query, Key, Value가 동일한 경우를 말합니다.
반면, 세번째 그림 Encoder-Decoder Attention에서는 Query가 Decoder의 벡터인 반면에 Key와 Value가 Encoder의 벡터이므로 Self-Attention이라고 부르지 않습니다.
Self-Attention @ Encoder : Query = Key = Value
Self-Attention with mask @ decoder : Query = Key = Value
Attention from Encoder @ decoder : Query : Decoder Vector / Key = Value : Encoder Vector
Attention의 개념
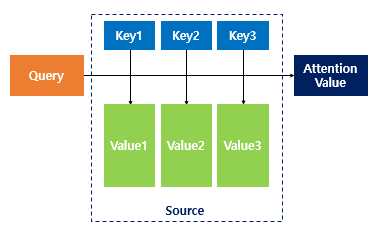
Attention 함수는 주어진 Query(쿼리)에 대햇서 모든 key(키)와의 유사도를 각각 계산합니다.
유사도를 가중치로 하여 key와 mapping 되어 있는 각각의 value(값)에 반영해줍니다.
이후 유사도가 반영된 value(값)을 모두 더하여 리턴하게 됩니다.
Self-Attention
그렇다면 Self-Attention은 무엇일까요?
해당 Attention을 자기자신에게 수행한다는 의미입니다.
기존 seq2seq의 Attention의 Q,K,V의 정의를 보면
1. seq2seq에서 어텐션에서 Q, K, V
- Query : t시점(time-step)의 decoder셀에서의 hidden state
- key : 모든 시점의 encoder셀의 hidden state
- value : 모든 시점의 encoder셀의 hidden state
위의 t라는 것은 시점에 따라서 계속 변화하는 값을 가지게 됩니다.
변화하는 값에 따라서 Query를 수행하므로 결국 전체 시점에 대해서 일반화가 가능하게 됩니다.
2. 전체 시점의 일반화한 Q, K, V
- Query : 모든 시점의 decoder셀에서의 hidden state
- key : 모든 시점의 encoder셀의 hidden state
- value : 모든 시점의 encoder셀의 hidden state
전체 시점에서 일반화한 값을 보면 각각의 hidden state는 Decoder에서의 값인지, Encoder에서의 값인지에 대한 차이 밖에 없게 됩니다.
즉, Q는 decoder의 hidden state고, K는 Encoder의 hidden state 점에서의 차이가 발생합니다.
하지만, Self-Attenion은 Q,K,V가 전부 동일합니다.
3. Self-Attention의 Q, K, V
- Query : 입력 문장의 모든 단어 Vector들
- Key : 입력 문장의 모든 단어 Vector들
- Value : 입력 문장의 모든 단어 Vector들

위 문장을 해석하면 "그 동물은 길을 건너지 않았다. 왜냐하면 너무 피곤했기 때문이다."입니다.
여기서 "it"은 무엇일까요?
사람은 당연히 동물이라고 답변을 할 것입니다.
하지만 기계의 경우 "it"이 "street"인지 "animal"를 모를겁니다.
이때, Self-Attention은 입력 문장 내의 단어들끼리 유사도를 계산하면서 "it"이 "street"보다는 "animal"에 더 연관되어 있으 확률이 높다는 것을 알아내게 될 것 입니다.
마지막은 Transformer에서 3가지 Attention이 어디에 있는지 그림으로 확인해보며 끝마치도록 하겠습니다.
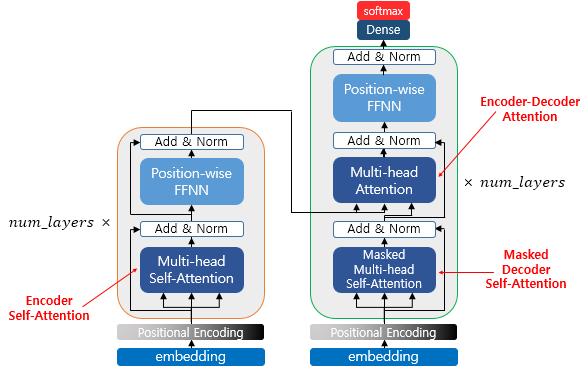
이미지에는 Multi-head Attention이라고 나와 있습니다.
이는 간단히 말하자면 Attention Layer가 여러개가 존재해 병렬적으로 Attention을 수행하는 방법을 의미합니다.
