프로젝트 소개
해당 프로젝트는 빅픽처인터렉티브(이하 줄여서 빅픽처라고 부르겠습니다.)의 전적검색 팀 소속 인턴으로 일하면서 처음으로 진행했던 프로젝트입니다.
프로젝트의 이름은 롤체지지 시즌성적표입니다.
빅픽처는 게임 대회 사업, 전적검색 등 게이머들을 위한 서비스들을 다양하게 전개해 나가는 플랫폼 기업입니다.
그 중 롤체지지는 빅픽처에서 서비스하는 전적검색 서비스인 닥지지에 속해있는 전략적팀전투(TFT, 롤토체스, 롤체 등등 다양하게 불립니다.) 게임의 전적검색을 담당하는 사이트입니다.
롤체지지는 TFT를 즐겨하는 국내 유저들이 자주 찾고 이용하는 닥지지의 핵심 서비스입니다.
저는 이 롤체지지의 수 많은 서비스 중 신규 서비스이자 이벤트성 서비스인 시즌 성적표 라는 서비스의 프론트엔드 개발자로 참여하게 되었습니다.
프로젝트에 참여한 프론트엔드 개발자는 저 포함 총 2명으로, 인턴으로 입사한 이후 첫 프로젝트인 만큼 사수 개발자분과 함께 프론트엔드 작업을 하였습니다.
시즌성적표에 대한 좀 더 자세한 설명
시즌 성적표에 대한 소개를 위해선 TFT의 특징중 하나인 시즌에 대한 이해가 있어야 합니다.
시즌이란 특정 기간을 의미하며 특정 시즌 동안에 유저들은 해당 시즌에만 만날 수 있는 기물, 아이템, 특성 등을 사용하여 게임을 하게 됩니다.
시즌이 바뀌어 새로운 시즌이 열리면 기존에 있던 기물, 아이템, 특성과 같은 요소들이 변화하여 유저들은 시즌이 바뀔 때 마다 새로운 메타를 이용하여 TFT를 더 재밌게 즐길 수 있게 됩니다.
시즌 성적표는 이 시즌이 끝나고 난 뒤 해당 유저가 해당 시즌 동안 플레이 했던 기록을 살펴보고, 기록할만한 의미가 있는 경기 및 경기에서 사용한 요소들을 추출하여 성적표 형태로 보여주는 컨텐츠입니다.
유저들은 해당 성적표를 보고 이번 시즌 동안 얼마나 잘 플레이 했었는지 파악할 수 있고, 다음 시즌에서도 좋은 성적표를 받기 위해 열심히 노력하는 동기부여를 받을 수 있습니다.
KPT 회고를 활용한 회고록
KPT 회고방법은 아래의 포스트를 참고했습니다.
[프로젝트 회고] 회고 작성법-cks3066
Keep
하나의 거대한 기능을 컴포넌트 단위로 분리
컴포넌트를 통한 관심사의 분리 및 코드의 가독성 증가는 리액트를 활용하는 어느 프론트엔드 개발자라도 적용하는 방식이라고 생각합니다.
다만 당시 인턴으로 첫 프로젝트를 맡은 저에겐 컴포넌트라는 개념 자체는 있었지만, 왜 분리 해야 하고, 분리해서 얻는 이점에 대해 잘 몰랐던 상태였습니다.
따라서 시즌 성적표의 일부 기능을 만들고 사수 개발자분과 함께 코드 리뷰를 하면 화면상에 구현한 UI가 어느 위치에 어느 코드인지 파악하는데 많은 시간과 노력이 들었습니다.
인턴으로 일하기 전엔 거의 대부분의 코딩 작업은 혼자서 하는 작업이 많았고, 팀프로젝트를 하더라도 혼자서 로직의 중요한 부분은 전부 처리하고, 나머지 자잘한 부분만 팀원들에게 채워달라고 부탁하는 방식으로 팀프로젝트를 진행해왔기 때문에 협업에 필요한 스킬에 대한 부분이 많이 부족했었습니다.
해당 프로젝트를 진행하면서 사수 개발자님께서 짠 코드를 보면서 컴포넌트를 어떻게 사용하면 좋을지 생각해보게 되었고, 나름대로의 기준을 정해서 컴포넌트를 분리해보려고 노력해보았습니다.
다만 컴포넌트를 너무 잘게 분해하여 특정 컴포넌트에는 상태나 로직에 대한 코드 없이 스태틱한 UI 코드만 들어 있는 경우도 발생하여, 이런 부분들은 코드 리뷰 시간에 사수 개발자님과 함께 고쳐가며 적절하게 컴포넌트를 분리할 수 있는 방법에 대해 알 수 있는 시간이 되었습니다.
다국어 서비스
다국어 서비스 역시 인턴으로 들어오고 난 뒤로 처음 해보는 작업이었습니다.
개인 프로젝트를 진행할 때도, 다른 언어에 대한 고려를 전혀 해본적이 없었기에 어떻게 처리하는지 굉장히 궁금했었습니다.
저희가 사용한 방식은 next-i18next이란 라이브러리를 활용하였습니다.
프로젝트 내부에 언어별 json 파일을 생성하고, 해당 json 파일에 동일의 key를 가지지만, 언어마다 다른 value 값을 갖는 [key-value]쌍들을 배치합니다.
한국어(.../ko/common.json)
{
"cost": "코스트",
"copy": "복사",
"round": "라운드",
}영어(.../en/common.json)
{
"cost": "Cost",
"copy": "Copy",
"round": "Round",
}그 후 라이브러리의 도움으로 useTranslation 이란 훅을 통해 필요한 다국어 처리 된 텍스트를 불러와 사용하였습니다.
또한 Next.js에서 지원하는 SSR을 통해 시즌 성적표 페이지에 필요한 요소들을 가져오고 있었기 때문에 다국어 처리에 필요한 json 파일도 SSR에서 데이터를 가져오는 시간 동안에 처리할 수 있도록 하였습니다.
대략적인 코드의 모습은 이렇습니다.
import { serverSideTranslations } from 'next-i18next/serverSideTranslations'
export async function getServerSideProps({ locale }) {
return {
props: {
...(await serverSideTranslations(locale, [
'common',
'footer',
])),
},
}
}출처: https://github.com/i18next/next-i18next#serversidetranslations
이렇게 서버에서부터 가져온 다국어 데이터를 바탕으로 useTranslation 훅을 통해 다국어 처리를 쉽게 할 수 있었습니다.
const MainText = () => {
const { t } = useTranslation('common') //훅 선언
return <div>{t("common:cost")}</div> // "코스트" or "Cost"
}t 함수에 json 파일에서 정의했던 key 값을 넘겨주면 됩니다.
t 함수는 Next.js의 Router 객체의 locale 속성의 값이 무엇인지에 따라 타겟 언어 파일을 찾아(json 파일) t함수의 인자로 전달 된 키 값을 찾아 텍스트를 리턴하게 됩니다.
property accessor의 경우
.이 아닌:으로 처리합니다.
따라서 내부적으로 라우터의 locale 값을 바꿔주면 다국어 변경이 가능합니다.
router.push(..., ..., { locale: "ko" | "en" })API에서 내려 받은 데이터 처리 및 최적화를 위한 useMemo 사용
시즌 성적표 작업을 하면서 처음으로 성적표 API를 통해 데이터를 가져오고 난 후 방대한 양의 데이터를 보고 깜짝 놀랐던 적이 있었습니다.
전적검색 도메인의 특성상 데이터의 양이 많을 수 밖에 없는데, 이는 다음과 같은 이유가 있습니다.
- 특정 유저의 전적 데이터는 단순히 승,패만 적힌 것이 아니고, 해당 게임을 하면서 사용했던 기물, 아이템, 특성에 대한 모든 정보가 필요하다.
- 이런 아이템들에 대한 상세 정보는 너무 길고, 중복 되기 때문에 따로 레퍼런스 데이터로 저장하고 있는데, 해당 레퍼런스 데이터도 API에 포함시켜 보내주고 있음
- 레퍼런스 데이터 정도는 프론트에서 저장해서 사용해도 괜찮지 않냐고 생각할 수 있지만, 중간 중간 패치로 인해 값이 바뀌거나, 혹은 TFT의 제작사인 라이엇 측에서 갑작스럽게 API 구성요소들을 바꿀 수 있기 때문에 가변적인 요소가 많아 서버에서 관리하고, 프론트로 내려주는 방식이 적절함.
- 전적의 경우 특정 유저가 플레이한 경기를 바탕으로 보내주기 때문에 경기에 대한 정보가 유저들에게 보여야 하고, 해당 경기에는 같이 플레이한 유저에 대한 정보가 들어 있음.
- 따라서 전적검색을 요청한 유저 + 그 유저와 함께 플레이 했던 유저들 까지 모두 가져오면 데이터의 양이 엄청 늘어날 수 밖에 없음.
이런 이유로 인해 전적검색 프론트엔드 개발자분들께선 항상 받아온 데이터를 두번 이상 요청함으로 인해 과도한 네트워크 리소스 낭비가 일어나지 않도록 조심하고 있습니다.
그리고 이런 데이터의 리패치는 결국 리렌더링을 불러일으킬 가능성도 있기 때문에 useMemo에 대한 사용을 적극 권장하고 있습니다.
const setReportByGameMode = useMemo(
() => setReport.setReports.find(report => (isDoubleUp ? isQueueDoubleUp(report.queueId) : report.queueId === queue)),
[setReport, queue],
)예를 들어 위의 코드에선 유저의 성적표 데이터를 받아온 후 게임 모드(일반, 랭크, 더블업, 초고속)에 따라 성적표 데이터를 파싱해서 사용해야 하는 경우가 발생합니다.
이런 경우 매 렌더링 마다 파싱 작업을 진행하게 된다면, 방대한 성적표 데이터를 파싱하는 리소스 값이 비싼 연산을 계속하게 될 가능성이 있기 때문에 useMemo를 사용하여 메모이제이션 시켜 사용할 수 있습니다.
useMemo를 사용할 때 마다 과연 내가 적절하게 useMemo의 종속성 배열을 채워넣었는지 고민하게 됩니다.
이번 코드의 경우 setReport 라는 API로 부터 받은 성적표 데이터가 들어있는 객체와 queue 라는 게임 모드에 대한 정보를 담고 있는 변수를 종속성으로 설정하여 메모이제이션 하고 있습니다.
일단 리액트 쪽에서 권장하는 방식은 useMemo의 첫번째 인자로 전달한 함수에서 참조하고 있는 변수는 모두 종속성 배열에 담아서 사용해야 한다고 나와있습니다.(참조)
리액트의 권장방식에 따라 코드를 살펴봐도 일단은 참조 하고 있는 setReport, queue를 잘 적어주었으므로 종속성에 대한 고민은 어느정도 해결 되었습니다.
SEO 적용
해당 프로젝트를 진행하기 전 까지만해도 SEO에 대한 중요성이나 그 의미에 대해서도 잘 몰랐던 상태였습니다.
SEO = Search Engine Optimization
정도로만 이해하고 있었고, 그냥 구글 같은 검색 포털 사이트에서 검색했을 때 상단에 우리 사이트가 등장할 확률을 높여주는 요소 정도로만 이해하고 있었습니다.
이번 프로젝트를 진행하면서 SEO가 실제로 서비스하는 기업 입장에서 얼마나 중요한지 처음 알게 되었고,
사수 개발자님의 도움으로 SEO를 Next.js에서 적용하는 방법에 대해 많이 배울 수 있었습니다.
프로젝트의 SEO 처리를 위해 next-seo 라는 라이브러리를 활용했습니다.
next-seo 라이브러리를 사용하면 손쉽게 SEO를 관리할 수 있게 됩니다.
추가로 DefaultSeo 라는 컴포넌트를 제공하여, 페이지별로 적용될 공통 요소들을 뽑아서 _app.tsx 같은 곳에 적용시켜 모든 페이지에 적용 되도록 SEO를 세팅할 수도 있습니다.
프로젝트에 적용한 SEO 속성은 다음과 같습니다.
- title
- description
- OG
- canonical
- languageAlternates(다국어 지원을 하는 사이트의 경우 디폴트로 설정한 언어를 제외한 나머지 언어들을 통해 만들어 지는 URL들을 적어둘 수 있음.)
실제 서비스 하고 있는 시즌 성적표 페이지의 Head 태그 속 SEO 처리 결과물
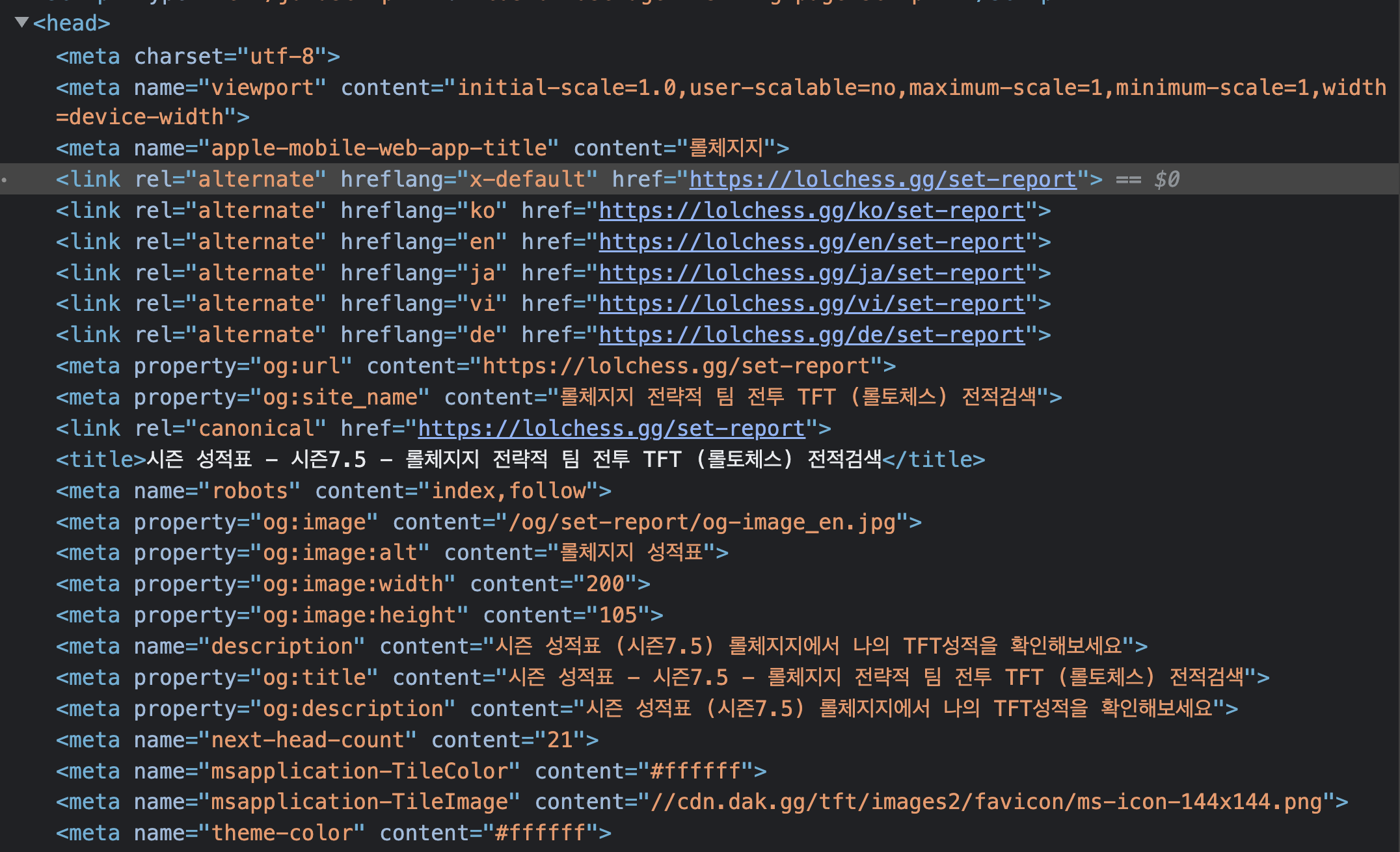
모달, 드롭다운 같은 프로젝트에서 공통적으로 사용 될 컴포넌트 개발
시즌 성적표는 크게 2 페이지로 구성 된 간단한 프로젝트였습니다.
- 시즌 성적표의 인덱스 페이지
- 유저의 검색 결과를 바탕으로 성적표 데이터를 보여주는 메인 페이지
두 페이지를 만들면서 다음과 같은 요소들이 중복적으로 사용 됨을 깨닫게 되었습니다.
- 소환사
라이엇에서 유저들을 부르는 명칭검색 form - 소환사 검색시 어느 지역 서버로 선택하여 검색할 것인지 판단하는 regionDropdown
글로벌 게임사인 라이엇에선 다양한 지역의 서버를 제공하고 있기에
서버(region)+소환사명을 통해서 정확하게 유저를 찾아내어 해당 유저의 시즌 성적표 데이터를 가져올 수 있게 됩니다.
사수 개발자님과 이에 관련하여 코드리뷰 도중 제가 두 페이지에서 중복적으로 사용 되는 공통 요소들을 하드 코딩하고 있는 걸 파악하시곤, 이를 모달, 드롭다운이란 두 페이지에서 공통으로 사용할 수 있는 공통 컴포넌트로 뽑아 내어 사용하는걸 추천하셨고, 이에 듣고 보니 중복을 제거하는 쪽으로 코드를 구성하는 것이 더 유지보수나 협업하는 과정에서 유리할 것으로 판단 되어 이들을 공통 컴포넌트로 제작하게 되었습니다.
이전까진 공통 컴포넌트를 제작해본 경험이 별로 없었기에 어떻게 하면 좋을지 고민하였고, 사수 개발자님의 도움을 받아 두 페이지에서 공통으로 사용할 수 있는 모달, 드롭다운 공통 컴포넌트를 제작하였습니다.
그 중 예시로 모달에 대한 코드를 보자면
import { HTMLAttributes, useState } from 'react'
import { ModalContext } from '@/components/Modal/context'
import ModalPortal from '@/components/Modal/ModalPortal'
interface IProps extends HTMLAttributes<HTMLDivElement> {
trigger: JSX.Element
content: JSX.Element
}
const Modal = ({ trigger, content, ...props }: IProps) => {
const [open, change] = useState(false)
const onToggle = () => change(prev => !prev)
return (
<ModalContext.Provider value={{ open, onToggle }}>
<div {...props}>
<div>{trigger}</div>
{open && <ModalPortal>{content}</ModalPortal>}
</div>
</ModalContext.Provider>
)
}
export default Modal우선 모달의 경우 모달을 띄우는 이벤트 핸들러를 가지고 있는 Trigger 와 트리거 되었을 때 보여질 모달의 본체인 Content 로 크게 나뉘어지게 됩니다.
그리고 모달의 열고 닫힘을 파악하기 위한 open 이란 상태를 만들고, 이 값을 반대로 뒤집을 수 있는(boolean) onToggle 함수를 제작합니다.
원래라면 이들을 props로 전달하거나, 상태관리 라이브러리를 활용하여 하위 컴포넌트로 전달하겠지만,
이번 기회엔 Context API를 사용하여 상태를 전달하였습니다.
Context API를 사용하면 하위 컴포넌트에 props drilling 현상을 방지하고, useContext 훅을 통해 쉽게 상태 값을 받아낼 수 있어 코드의 가독성을 높이는데 많은 도움이 됩니다.
다만 Context API를 사용하는 경우 open 상태값의 변경이 일어나면, open 상태값을 구독하지 않는 경우에도 무조건 리렌더링이 일어나게 되므로 비효율적인 렌더링이 발생할 수 있습니다.
다만 모달의경우 왠만해선 Trigger , Content 모두 useContext 를 통한 모달 제어 상태값을 원하기 때문에 Context API의 변화로 인한 하위 컴포넌트의 무조건 적인 리렌더 이슈는 무시해도 괜찮다고 판단하였습니다.
Context API의 무분별한 리렌더 방지를 위해선 React.memo를 통해 Context API를 구독한(useContext를 사용하는) 컴포넌트만 리렌더링 시켜 해결할 수 있습니다.
또한 <ModalPortal/> 이란 컴포넌트를 통해 Content 값을 React.createPortal() 을 사용하여 엘리먼트 트리의 최상단 부분에 지정한 <div id="modal"/> 이란 컴포넌트 내부로 Content 값을 넣도록 설정하였습니다.
이는 너무 엘리먼트 트리의 깊숙한 부분에 모달 Content가 생성 되어 모달이 어디있는지 파악하기 힘든 부분을 개선하기 위해 사용하였습니다.
//ModalPortal.tsx
import { PropsWithChildren } from 'react'
import ReactDOM from 'react-dom'
const ModalPortal = ({ children }: PropsWithChildren) => {
const container = typeof document !== 'undefined' ? document.getElementById('modal') : null
return container ? ReactDOM.createPortal(children, container) : null
}
export default ModalPortal
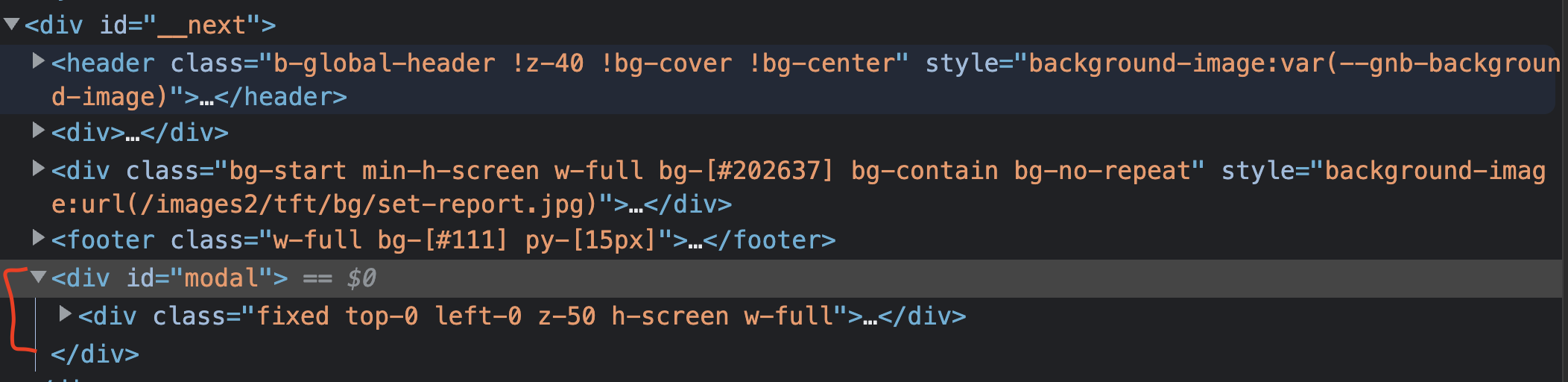
사진에서 볼 수 있듯이 모달 컴포넌트의 Content로 전달 된 컴포넌트는 포털의 기능으로 인해 엘리먼트 최상단 트리에 위치한 포털 전용 <div id="modal"/> 로 이동합니다.
공통 컴포넌트 모달의 사용 예시입니다.
import React from 'react'
import Modal from '@/components/Modal'
import Content from '@/views/setReport/components/RegionModal/Content'
import Trigger from '@/views/setReport/components/RegionModal/Trigger'
const RegionModal = () => {
return <Modal trigger={<Trigger />} content={<Content />} />
}
export default RegionModalNext.js를 통한 SSR(getServerSideProps)
간단하게 SSR에 대해 생각해보자면 클라이언트에서 전부 담당했던 렌더링을 서버 쪽에서 먼저 렌더링 후에 만들어진 HTML 코드와 리액트 JS 코드가 같이 브라우저에 전송 되어 유저들이 이를 받아 사이트를 이용할 수 있게 됩니다.
CSR의 경우 브라우저에서 JS 코드를 받아 실행 시키고, 렌더링 된 결과물이 HTML에 적용 되어 유저는 초기에 빈 페이지를 볼 가능성이 높지만, SSR의 경우 서버에서 렌더링한 HTML 코드를 같이 보내주기 때문에 초기 빈 페이지를 볼 확률이 매우 낮습니다.
물론 서버에서 뭔가 문제가 있거나 요청한 페이지의 렌더링이 오래걸리는 경우라면 SSR이라 하더라도 초기 로딩 시간이 걸릴 수 있습니다.
다만 이는 어디까지나 브라우저가 서버에 요청한 리퀘스트에 대한 리스폰스 값이 오지 않아서 생기는 로딩이지 CSR의 경우와 다릅니다.
CSR의 경우 이미 서버로 보낸 리퀘스트(페이지 요청)를 통해 리액트 코드가 담긴 JS를 받아 왔고, 이를 실행시켜 클라이언트 측에서 렌더링 하는 과정에서 생기는 로딩입니다.
따라서 SSR의 로딩은 브라우저의 탭을 보면 아이콘이 있고, 그 아이콘에 로딩 스피너(뺑글이)가 생기지만, CSR의 경우 개발자가 의도한 UI를 통해 로딩을 보여주게 됩니다(로딩 스피너도 이중 하나의 옵션입니다.)
SSR은 서버에서 렌더링한 결과물을 보내 화면을 페인트하고, 보낸 JS는 브라우저 측에서 읽어 HTML 코드에 이벤트 핸들러 같은 함수들을 붙여 사이트를 상호작용 할 수 있게 만들어 줍니다.
이를 하이드레이션(Hydration)이라 부릅니다.
(하이드레이션에 대한 자세한 설명은 이쪽을 참고해주세요)
(리액트18에서 효율적으로 하이드레이션을 처리할 수 있는 방법이 등장하였는데, 해당 설명이 잘 정리되어 있습니다.)
Next.js에선 추가적인 작업을 하지 않는다면, 작업한 페이지를 미리 서버에서 프리렌더링을 진행하고, 만들어진 HTML 파일을 리퀘스트에 따라 서브하고, JS 코드를 브라우저에 보내 하이드레이션 시켜줍니다.
이를 Next.js 측에선 Automatic Static Optimization 라고 부릅니다.
다만 getServerSideProps을 통해 데이터 패치를 하고 있다면, Automatic Static Optimization은 일어나지 않습니다.
예시)getServerSideProps를 사용한 경우
getServerSideProps 사용한 about 페이지->about.js로 만들어짐->매 리퀘스트마다 getServerSideProps를 돌려서 HTML 코드, JS 코드를 생성하여 클라이언트에 보내주고, 하이드레이션 작업 진행->정상적으로 유저 상호작용이 가능한 사이트가 됨.
예시)getServerSideProps를 사용하지 않은 경우
getServerSideProps로 만들어지지 않은 /profile 페이지->profile.html로 만들어짐->페이지 리퀘스트가 들어오면 프리렌더 된 HTML 파일과 필요한 JS 코드를 클라이언트에 보내 하이드레이션 시킴->유저는 프리렌더 된 HTML 코드를 서버 통신을 통해 바로 받아볼 수 있기 때문에 스태틱하지만 그래도 요청한 페이지의 UI가 얼추 보임.->그 동안 JS 코드가 돌면서 이벤트 핸들러 같은 클라이언트 측에서 필요한 JS 요소들을 하이드레이션 시켜줌->정상적으로 인터랙티브한 사이트를 이용할 수 있음.
이러한 이유로 최근 SSR의 인기는 높아졌으며, SSR을 지원하는 프레임워크들도 점차 늘어났습니다.
시즌 성적표 역시 Next.js로 만들어졌고, SSR을 사용할 수 있는 환경이었기 때문에 SSR 도입에 대한 고민을 했었습니다.
Next.js 공식 문서의 getServerSideProps 섹션에서 When should I use getServerSideProps 파트를 보면 Next.js에서 getServerSideProps를 사용하길 추천하는 환경이 기술되어 있습니다.
You should use getServerSideProps only if you need to render a page whose data must be fetched at request time. This could be due to the nature of the data or properties of the request (such as authorization headers or geo location). Pages using getServerSideProps will be server side rendered at request time and only be cached if cache-control headers are configured.
If you do not need to render the data during the request, then you should consider fetching data on the client side or getStaticProps.
getServerSideProps 라는 이름에서도 알 수 있듯이 SSR로 구현이 필요한 경우는 매 리퀘스트 마다 서버에서 데이터를 패치해야 하는 경우에 사용하면 가장 좋다고 기술되어 있습니다.
또한 공식문서의 다른 섹션인 Fetching data on the client side 을 살펴보면 어느때 getServerSideProps를 사용하지 않고, 클라이언트 측에서 데이터 패치가 일어나면 좋은지 환경을 기술하고 있습니다.
If your page contains frequently updating data, and you don’t need to pre-render the data, you can fetch the data on the client side. An example of this is user-specific data:
First, immediately show the page without data. Parts of the page can be pre-rendered using Static Generation. You can show loading states for missing data
Then, fetch the data on the client side and display it when ready
This approach works well for user dashboard pages, for example. Because a dashboard is a private, user-specific page, SEO is not relevant and the page doesn’t need to be pre-rendered. The data is frequently updated, which requires request-time data fetching.
핵심은
페이지에 자주 데이터 업데이트, 즉 데이터 패치가 자주 일어나는 경우라면 굳이 getServerSideProps를 사용하지 않고, 클라이언트 측에서 데이터 패치를 처리하면 좋다 입니다.
이를 바탕으로 시즌 성적표 프로젝트의 성격에 대해 생각해보았습니다.
과연 getServerSideProps를 적용시킴으로 인해 얻을 수 있는 이점이 무엇일까?
사실 시즌 성적표 자체는 굉장히 스태틱한 페이지이고, 유저는 단순히 소환사명을 입력하고, 성적표를 확인하기만 하면 되기 때문에 데이터의 업데이트가 자주 일어날 필요가 전혀 없습니다.
그렇다고 getServerSideProps로 불러오기엔 API 호출로 인한 데이터양이 너무 많아 리스폰스를 받는데 걸리는 시간이 오래걸려 유저가 지루하게 브라우저 아이콘이 돌아가는 모습만 볼 수도 있습니다.
어느쪽을 선택해도 큰 이슈는 없는 상황에서 저와 사수개발자님은 getServerSideProps를 사용하지만, 실제 데이터 패치는 클라이언트 측에서 동작하도록 세팅하였습니다.
이렇게 한 이유는 다음과 같습니다.
getServerSideProps를 쓴 이유
- 시즌 성적표에서 잘못 된 시즌 혹은 잘못 된 region을 사용하여 API 서버로 리퀘스트를 보내는 경우 이를 사전에 프론트엔드에서 방지할 수 있음.(리다이렉트 혹은 404 page)
- 다국어 처리를 위한 next-i18next 라이브러리에서 SSR일때 언어 json 파일을 읽어올 수 있으므로, 이를 활용하면 심리스하게 i18n 적용을 시킬 수 있음.
클라이언트 측에서 API 서버로 데이터 패치를 한 이유
- 시즌 성적표 뿐만 아니라 전적검색 API 서버의 특징이기도 한 대기열 시스템 때문
- API 서버의 대기열 큐가 밀리는 경우 API 서버는 리스폰스로 데이터를 주는 것이 아니라, 해당 요청 앞으로 몇개의 요청이 들어와 큐에 쌓여 있는지 보여줌.
- 즉, API 서버에서 넘겨주는 리스폰스 값이 항상 일정하지 않을 수 있고, 대기열 큐에 잡혀있는 경우 특정 ms 이후(보통 500ms) 다시 요청을 해야 하므로, 이를 처리하는 방법은 getServerSideProps에서 처리하기 어려움.
- 따라서 성적표 데이터에 대한 패치는 클라이언트 측에서 처리하는 것이 좀 더 알맞음.
한줄로 간단히 요약하자면 getServerSideProps로 리퀘스트에서 불필요한 요청을 API 서버로 보내지 않고 걸러낼 수 있고,
클라이언트 측에서의 데이터 패칭을 통해 대기열 큐 관련 처리를 유연하게 처리하고, 잦은 데이터 업데이트를 처리하기 쉬웠기 때문에
SSR + Client Side Data Fetching 이란 전략을 사용하게 되었습니다.
Problem
기능 중 하나를 라이브러리 이슈로 인해 완벽하게 구현하지 못한 점
지금은 사라진 기능이지만, 초기 릴리즈를 위해 개발하는 과정에서 유저에게 성적표 페이지를 이미지로 변환 하여 다운로드 받을 수 있게 하는 기능이 존재했습니다.
결론부터 말씀드리자면, 해당 기능은 데스크탑에선 잘 동작했지만(크롬, 사파리 같은 유명 브라우저에서 테스트) 모바일에선 다운로드가 되지 않거나, 이미지의 품질이 떨어지거나, 이미지가 원본 페이지의 요소들을 모두 담지 못하는 등 많은 오류사항들이 발생하여 현재는 없어진 기능입니다.
초기 릴리즈 당시 해당 기능을 구현하기 위해 성적표 페이지를 이미지로 변환하는 기술이 필요했고,
관련 라이브러리가 없는지 찾아봤더니 역시나 누군가가 이미 HTML -> Img 로 변환 시키는 라이브러리를
구현해두었습니다.
html-to-image, html2canvas, dom-to-image 와 같은 다양한 라이브러리 후보군 중, 쉽고, 빠르고, 정확성이 높은 dom-to-image 를 사용했습니다.
라이브러리를 활용하여 기능은 쉽게 구현했습니다.
물론 그 당시 제 생각이었고, 문제는 많았지만, 일단 개발 환경인 데스크탑 + 크롬 브라우저에서 잘 돌아가니 괜찮다고 착각해버렸습니다.
그 후 시간은 흘러 개발 기간이 끝나고 QA 기간 중 들어오는 피드백을 처리하던 중 해당 기능에 문제가 있다는 소식을 접하게 되었습니다.
이슈 내용은 다음과 같았습니다.
- 사파리 브라우저에서 저장을 하면 성적표 컴포넌트 몇가지가 없어진 채로 저장되고, 가끔은 저장이 안될 때도 있고, 레이아웃 정렬도 다 틀어진 채로 나오게 된다.
- 모바일의 경우 크롬이든 사파리든 이미지 저장 버튼을 눌러도 저장이 안된다.
이미지 저장 기능은 라이브러리 도움을 받아 정말 빠르게 구현했었는데, 문제가 많다고 하니 약간 당황하게 되었습니다.
QA 담당자분께 빠르게 수정하겠다고 말씀을 드리고, 고치려고 코드를 보아도 막상 감이 잡히지 않았습니다.
이미지 저장 기능의 핵심은 라이브러리였고, 이 라이브러리가 알아서 처리해주고 있었기 때문에 저는 라이브러리에서 제공하는 함수 하나만 딱 쓰고 있었던 것입니다.
분명 개발했을 때의 환경인 데스크탑 + 크롬 브라우저 환경에선 정상 작동했지만, QA담당자님의 말씀대로 다른 브라우저에선 계속 이상하게 이미지가 생성되고 있고, 모바일은 아예 다운로드가 되지도 않았습니다.
그렇게 눈물의 디버깅쇼를 시작하게 되었습니다.
에러 원인을 찾기 위해 계속 삽질을 하고, 라이브러리 문제인가 해서 라이브러리 후보군에 있었던 모든 라이브러리를 사용해 보면서 제발 해결되길 빌었지만, 해결 되지 않았습니다.
그렇게 디버깅에 하루 종일을 사용하고, 퇴근 후에도 집에서 왜 그런지 계속 찾아보았지만, 결국 마땅한 답은 나오지 않았습니다.
며칠 뒤면 QA 기간 후에 실서비스로 릴리즈가 나가야 하는데, 기능 중 하나가 고장났고, 그게 내 탓이라는 생각이 들자 정말 공포스럽고, 팀원분들께 미안하기도 한 생각에 잠겨, 그때가 새벽 2시였는데, 공포 + 현타감이 찾아와 아무것도 하지 못했습니다.
다음날에도 출근해야 하기 때문에 일단 누웠지만 정말 아무런 생각이 들지 않았고, 어떻게 해야 할지만 고민했었습니다.
다음날 회사에 나가 사수 개발자님께 현 사태에 대한 설명을 드리고, 죄송하다고 말씀드렸습니다.
사수 개발자님께선 괜찮다고 자기도 한번 체크해보겠다며 위로해주셨고, 그런 모습에 저도 더 열심히 이슈 디버깅을 했었습니다.
그렇게 사수 개발자님과 함께 이슈 디버깅을 하던 중, 데스크탑에서 사파리 같은 다른 브라우저를 사용 시에 레이아웃이 의도한 방향과 다르게 동작한 부분은 html, css를 수정하여 어느정도 해결할 수 있었습니다.(레이아웃에 대부분 flex, gap을 사용했었는데, 지금은 사파리 버전이 올라가 괜찮지만, 당시엔 gap이 먹지 않고, row-gap, column-gap으로 수정해야 했었습니다.)
눈물의 디버깅쇼를 통해 데스크탑쪽 대표 브라우저(크롬으로 대표 되는 크로미움 베이스 브라우저들, 사파리)에선 정상 동작하는 걸 확인할 수 있었습니다.
문제는 모바일쪽 성적표가 다운로드 되지 않는 경우였습니다.
기존 성적표를 이미지로 변환 후 라이브러리에서 전달해주는 이미지 데이터를 눈에 보이지 않는 <a/> 태그와 download 속성을 활용하여 다운로드 로직을 구성하고 있었는데, 모바일에선 이상하게도 이게 동작하지 않았습니다.
그래서 모바일 쪽도 계속 디버깅을 해보고, 마지막의 마지막까지 해결해보려 노력했지만, 결국 모바일쪽은 릴리즈 데드라인에 부딪혀 모바일에선 해당 기능을 숨김처리 하는 방식으로 릴리즈 하게 되었습니다.
현재는 호환성 문제인지, 통일감을 주기 위해서인지는 몰라도 데스크탑에서도 해당 기능이 사라진 상태입니다.
사수 개발자님께서도 이런 기능은 사실 백엔드에서 템플릿을 만들고, 거기에 가변 데이터(유저 데이터)를 집어 넣어서 프론트로 보내주는 방식으로 했어야 했다고 프론트에서 처리하기엔 힘든 기능이었다고 말씀해 주셨습니다.
깔끔한 결말도 아니고, 어떻게 보면 반쯤 구현된 기능이었어서 성적표 프로젝트를 진행하면서 많이 아쉬운 부분이었습니다.
그래도 눈물의 디버깅쇼를 하면서 정말 똥줄이 탄다는 느낌이 뭔지 깨닫게 되었고, 크로스 브라우저 체크의 중요성에 대해서도 깨닫게 되었습니다.
괜히 caniuse 사이트가 존재하고, 브라우저 호환성을 체크하는게 아니라는걸 깨닫게 된 순간이었습니다.
컴포넌트 분리에 대한 기준점이 명확하지 않음
앞서 Keep 부분에서 컴포넌트의 분리를 통해 관심사를 분리 시키고, 커다란 기능을 잘게 부수어 top-down 방식을 코드에 녹이는 경험을 했다고 당당하게 말씀을 드렸지만
현실은 그리 녹록치 않았습니다. 컴포넌트를 어디까지 잘게 잘라서 구현해야 하는지, 해당 컴포넌트는 공통 컴포넌트로 구현해야 하는건 아닌지, 공통 컴포넌트에 너무 많은 자율성을 주어 프롭 지옥이 펼쳐지거나 하는 사이드 이펙트 들이 마구마구 등장했습니다.
사수 개발자님께도 이와 관련하여 상담을 드렸었는데, 사수 개발자님께서도 컴포넌트 분할은 쉬운일이 아니고, 팀 내에서 프론트엔드 개발자들끼리 서로 소통을 하며 룰을 정하는게 좋고, 경험이 쌓여야 하는 부분이라고 말씀해 주셨습니다.
특히 저희 프로젝트의 경우 styled-component, emotion과 같은 css-in-js 라이브러리를 사용하지 않고, tailwindcss를 사용하고 있었기에 너무 세세하게 컴포넌트 분할을 하다보면 컴포넌트에 로직은 없고, UI 값만 존재하는 경우도 발생하였습니다.
function MainText(){
return <h1>hardcoded text</h1>
}이런 로직은 css-in-js를 사용했다면 컴포넌트 분리가 굳이 필요하지 않은 경우였기에 이런 부분에서 아쉬움이 남았습니다.
한 컴포넌트 내에서 너무 많은 일들이 일어나고 있음
열심히 코딩을 하다보면 컴포넌트에 너무나도 많은 코드가 생기는 경우가 종종 있습니다.
특히나 데이터 패치를 담당하고 있는 최상위 컴포넌트인 경우 데이터 패치 상태에 따라 로딩 상태, 정상 상태, 에러 상태 같은 상태에 따른 UI들을 분기 처리 해야 하는 상황들이 생기게 됩니다.
그리고 이를 하나의 컴포넌트에 담으면 내일 아침에 다시 보면 절대 읽지 못할 정도로 복잡한 컴포넌트가 탄생하게 됩니다!
시즌 성적표 프로젝트도 다를바 없었습니다. 유저의 성적표 데이터를 보여주는 페이지의 최상단 컴포넌트에선 데이터 패치를 하고, 패치 상태에 따른 분기 처리가 된 UI 코드가 담겨있었습니다.
복잡해진 컴포넌트를 간단하게 하기 위해 정상 상태일 때 보일 요소들을 따로 컴포넌트로 만들어 압축시켰고, 데이터 패치 상태에 따른 분기 처리 되는 UI 코드 사이의 중복된 요소들을 따로 분리해 컴포넌트로 제작하는 등 컴포넌트 복잡도를 줄이기 위해 노력하였습니다.
const content = isError ? (
<ReportWrapper>
<NotFound />
</ReportWrapper>
) : isLoading ? (
<ReportWrapper>
<Loading data={data} />
</ReportWrapper>
) : (
<>
<SetReport data={data} />
{/* kakao script */}
<Script src={'https://developers.kakao.com/sdk/js/kakao.min.js'} strategy="lazyOnload" />
</>
)
return (
<>
{content}
</>
)이런식으로 content 라는 변수를 할당하여 패치 상태에 따른 보여질 컴포넌트를 분기 처리하였고, 실제 컴포넌트에서 렌더링 하는 것은 content변수로 고정시켜 복잡도를 줄이기 위해 노력하였습니다.
하지만 여전히 해당 코드에는 데이터 패치 상태에 따른 분기 처리 렌더링이 무조건 들어가야 합니다.
혹시 이런 분기 처리를 할 필요 없이, 데이터 패치 상태를 굳이 개발자가 명령형으로 나열하여 분기 렌더링하지 않고, 선언형 방식으로 처리할 수 있을까요?
그렇게 한다면 해당 컴포넌트는 로딩 상태도, 에러 상태도 관리할 필요 없이 무조건 정상 상태일때를 가정하고 컴포넌트를 코딩한다면 확실히 복잡도가 드라마틱하게 줄어들 것으로 보입니다.
물론 이렇게 말하는 이유는 그 정답을 이미 알고 있기 때문입니다 ㅎㅎ
리액트18이 상용화 되고 있는 현 시점에 리액트에는 선언형 컴포넌트를 사용하여 비동기 로직을 멋지게 처리할 수 있습니다.
그 핵심 키워드는 Suspense, ErrorBoundary 입니다.
Suspense를 사용하여 로딩 상태를 선언적으로 관리할 수 있고, ErrorBoundary를 통해 에러 상태를 선언적으로 관리할 수 있게 됩니다.
이에 대한 자세한 설명은 후에 다른 포스트로 찾아봽겠습니다.
만약 이들을 적용한 컴포넌트는 다음과 같이 변화할 것 입니다.
import {ErrorBoundary} from 'react-error-boundary' //ErrorBoundary를 함수형 컴포넌트에서도 쉽게 사용할 수 있게 도와주는 라이브러리
import {Suspense} from "react"
import {useQuery} from "@tanstack/react-query"
function ErrorFallback({error, resetErrorBoundary}) {
return (
<div role="alert">
<p>Something went wrong:</p>
<pre>{error.message}</pre>
<button onClick={resetErrorBoundary}>Try again</button>
</div>
)
}
function LoadingFallback(){
return <div>Loading...</div>
}
function SomeComponent(){
const { data } = useQuery(...) // react-query 사용
return <div>{JSON.stringify(data)}</div>
}
//page.tsx
export default function Page(){
return (
<ErrorBoundary
FallbackComponent={ErrorFallback}
onReset={() => {
// reset the state of your app so the error doesn't happen again
}}
>
<Suspense fallback={LoadingFallback}>
<SomeComponent />
</Suspense>
</ErrorBoundary> )
}
데이터 패치가 이루어지는 곳 SomeComponent는 이제 더 이상 로딩 상태, 에러 상태에 대한 분기 처리를 신경쓸 필요가 없어졌습니다.
대신 이들을 밖으로 빼내어 Suspense와 ErrorBoundary에 처리를 위임하였습니다.
따라서 SomeComponent는 이제 자신이 해야할 일, 즉 정상적으로 데이터가 들어왔을 경우 보여줄 UI, 상태에만 신경쓰면 됩니다.
이런식으로 앞서 명령형 방식 (로딩, 에러, 정상 상태를 받아 컴포넌트 내에서 if 분기 처리를 통해 조건부 렌더링 하던 방식, 성적표 코드에선 content 변수를 생각하시면 됩니다.) 에서 선언형 방식 (Suspense, ErrorBoundary로 로딩상태, 에러상태를 처리하는 컴포넌트로 감싸서 추상화 시킴. 이는 곧 리액트가 JSX를 통해 얻은 선언형 컴포넌트의 장점을 그대로 계승하는 것.) 으로 변경하는 경우 컴포넌트들은 각자 자신이 해야할 일만 처리하면 되기 때문에 (Suspense는 로딩, ErrorBoundary는 에러, SomeComponent는 정상적으로 데이터를 받은 경우) 흔히 컴포넌트에서 가장 중요하다는 관심사의 분리를 이뤄낼 수 있게 됩니다.
Suspense, ErrorBoundary, 그리고 리액트 18버전부터 도입되는 HTML Streaming, Selective Hydration를 통한 병렬적으로 비동기 처리하는 방식에 대해 자세히 알고 싶다면 해당 블로그 글을 참고해 주세요.
새롭게 사용한 기술들에 대한 깊이가 부족함
인턴으로 첫 프로젝트를 시작하면서 정말 많은 것들을 새롭게 배우게 되었습니다.
- SEO 처리를 통한 서치엔진의 눈에 더 잘띄게 만드는법
- i18n 를 통한 다국어 페이지를 쉽게 만들고, 유지보수 하기
- dom-to-image를 통한 HTML 엘리먼트를 바탕으로 이미지를 생성하는 방법
- Next.js에서 지원하는 다양한 페이지 렌더링 방식(SSR, CSR, Automatic Static Optimization)
등등 이것 말고도 정말 많은 것들을 새롭게 배우게 되었고, 확실히 사람은 데드라인이 있고, 누군가와 함께 프로젝트를 해서 이걸 말아먹으면 큰일 난다는 경계심을 어느정도 가지고 있을 때 가장 많이 배우고, 성장한다는걸 깨닫게 되었습니다.
하지만 사용하고, 깨달은건 좋지만, 어디까지나 해당 기술들을 필요에 의해 사용했던 것일뿐, 정확하게 해당 기술들이 무엇을 해결하고자 등장하였는지, 해당 기술들이 지원하는 영역의 범위는 어디까지인지 같은 깊이가 있는 영역에는 가지 못했던 것 같습니다.
그러나 새롭게 배운 지식들을 통해 비슷한 문제가 제게 주어질 경우 적어도 이전 경험에 따라 이렇게 하면 되겠다는 가이드라인이 머리에 그려질 수 있기에 새롭게 배울 수 있었다는 사실에 감사하고, 더 자주 써보면서 깊이를 늘려나가야겠다고 생각했습니다.
흔히 특정 기술을 처음부터 끝까지 정독하면 마스터 할 수 있다고 생각했었는데, 요즘엔 그렇게 하는 방식보단 어떤 기능을 구현해야 하는데, 이 기술이 필요해서 삽질하면서 파보는 경험에서 더 많은 것을 배우는 것 같습니다.
사실 자주 사용하지 않는 기술의 경우 이유가 있다고 생각하고, 리액트 같은 거의 코어가 되어버린 기술에 대해선 자주 사용하는 만큼 기술이 돌아가는 방법에 대해 깊게 파도 괜찮다고 생각하고 있습니다.
Try
- Suspense, ErrorBoundary를 활용하여 비동기 처리가 필요한 컴포넌트의 명령형 부분을 제거하고, 선언형으로 바꿔보기
- 리액트와 같은 자주 사용하는 기술에 대한 원리를 탐구하고, 가능하다면 영문 원서를 읽어가며 리액트가 어떻게 동작하는지에 대해 알아보기
- 컴포넌트 분리에 대한 명확한 기준에 대해 생각해보고, 구글링 하면서 남들은 어떻게 컴포넌트를 생성하고, 나누는지 파악해보기
- 성적표 이미지 저장 기능 사태를 다시는 겪지 않기 위해 미리미리 여러 환경에서 테스트해보는 습관을 들이기 프론트에서 테스트 코드 작성은 쉽지 않다고 들었는데, 그 부분도 탐구해보기(react-testing-library, jest, cypress)
느낀점
인턴으로 첫번째 프로젝트지만, 인생사 처음으로 다른 개발자들과 함께 일해본 프로젝트였다.
개발자뿐만 아니라, 기획자, 디자이너, 프론트, 백엔드, QA 이렇게 서비스 개발에 필요한 모든 인원들과 함께 한 프로젝트에 기여하는 일 자체가 처음이었다.
혼자서 코딩하는 일이 많았던 나에게 프로젝트의 주제도 주제지만 이렇게 일하는 방식, 협업에 굉장히 신선함을 느꼈던 것 같다.
특히 디자이너분께서 만들어 준 피그마 디자인을 보고 UI 구현하는 방식은 기존에 내가 직접 디자인해서 코딩해야 했던 작업을 줄여주었기에 너무나도 맘에 들었다.(혼자 프로젝트를 하다보니 디자인도 직접 생각해보곤 했다. dribble 같은 사이트에서 디자인 영감을 많이 얻곤 했다.)
첫 사회생활, 첫 회사생활을 하면서 진행한 프로젝트여서 그런지 개인적으로 애증이 많다.
코드는 지금 보면 정말 개판인데, 그 당시엔 정말 나름대로 열심히 했던 코드여서 왜 레거시가 생기는지 일정부분 이해할 수 있었다.
회사에서도 동료분들을 많이 만나고, 같이 점심 식사도 하고 얘기도 하면서 즐겁게 회사 생활을 보낼 수 있었다.
이 글을 빌어 다시한번 회사 동료분들께 감사의 인사를 드리고 싶다.
인턴으로 진행한 프로젝트는 총 3개로 앞으로 2개 더 남아있다.
다음으로 소개할 프로젝트는 사수 개발자분 없이 홀로 개발했던 프로젝트여서 좀 더 많은 노력과 애정이 담겨있다.
이만 느낀점을 마치고 다음 프로젝트 회고에서 봽겠습니다.
지금까지 길고도 긴 글 읽어주셔서 감사합니다!
