
MySQL 엔진 아키텍쳐
MySQL은 MySQL 엔진과 스토리지 엔진으로 구분할 수 있다.
MySQL은 다른 DBMS에 비해 구조가 독특하다고 하는데, 문맥상 두 엔진을 나눈 구조 때문인 것으로 보인다.
또한 이후 설명하겠지만, 독특한 구조 중 대표적인 것이 플러그인 스토리지 엔진 모델이다.
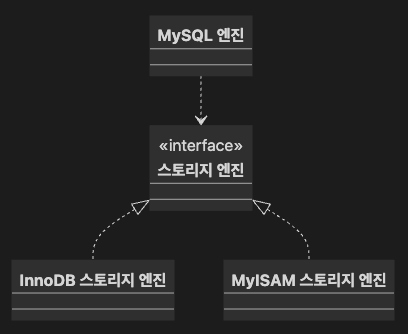
MySQL 엔진
- 클라이언트로부터의 접속 및 쿼리 요청을 처리하는
커넥션 핸들러 SQL 파서및전처리기- 쿼리의 최적화된 실행을 위한
옵티마이저
스토리지 엔진
- 실제 데이터의 저장, 읽기
MySQL에서 MySQL 엔진은 하나지만, 스토리지 엔진은 여러 개를 동시에 사용할 수 있다.
테이블이 사용할 스토리지 엔진을 지정하면, 해당 테이블은 모든 읽기, 변경 작업이 정의된 스토리지 엔진으로 처리된다.
스토리지 엔진은 성능 향상을 위해 특수 기능을 내장하고 있다.
- MyISAM: 키 캐시
- InnoDB: 버퍼 풀
핸들러 API
MySQL 엔진의 쿼리 실행기에서 데이터를 쓰거나 읽을 때, 각 스토리지 엔진에 쓰기 또는 읽기를 요청하는데, 이러한 요청을 핸들러 요청이라고 한다.
그리고 여기서 사용되는 API를 핸들러 API라고 한다.
InnoDB 스토리지 엔진 또한 핸들러 API를 사용하여 MySQL 엔진과 데이터를 주고 받는다.
명확히 InnoDB 스토리지 엔진만 언급하는데, 다른 스토리지 엔진은 핸들러 API를 사용하지 않는다는 것인가?
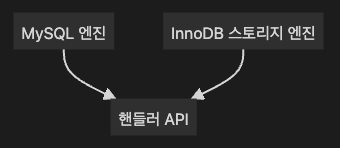
의존 관계로 나타낸다면 이렇지 않을까
SHOW GLOBAL STATUS LIKE 'Handler%'; 명령으로 작업이 얼마나 있었는지 확인할 수 있다.
Prometheus 모니터링 툴에서도 Handler 통계를 볼 수 있는데, read_rnd_next, read_key, read_next 수치에 대한 설명이 다음과 같아 나와있다.
read_rnd_next
- 풀 테이블 스캔 시 증가
- 높을수록 좋지 않다.
read_key
- 인덱스로 읽기가 완료되면 증가
read_next
- 스토리지 엔진에 "다음 인덱스 항목 읽기" 요청이 있을 때 증가
- 높을수록 인덱스 스캔이 수행되고 있다는 뜻
페스타고 운영 서버 기준, 유휴 상태에서 1분에 read_rnd_next 150, write 75, external_lock 0.26 정도로 기록되었다.
기본으로 사용되는 수치가 이 정도가 아닐까 한다. (모니터링으로 발생하는 쿼리가 포함되니 해당 값은 상대적이다.)

MySQL 스레딩 구조
MySQL은 프로세스 기반이 아닌, 스레드 기반으로 작동하고, 크게 포그라운드, 백그라운드 스레드로 구분할 수 있다.
select thread_id, name, type, processlist_user, processlist_host from performance_schema.threads order by type, thread_id; 명령으로 실행 중인 스레드의 목록을 확인할 수 있다.
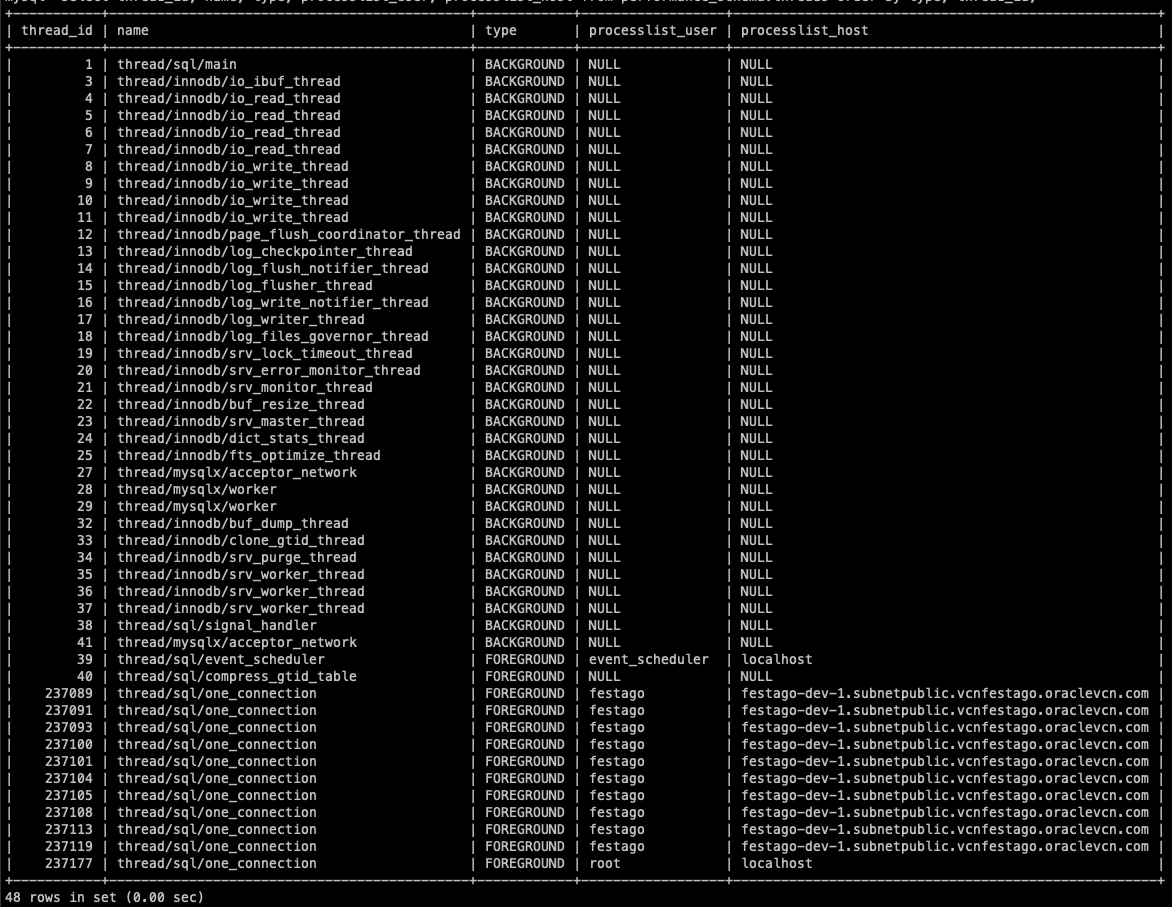
Spring을 사용한다면 Hikari CP의 커넥션 풀 개수에 맞게 10개의 포그라운드 스레드가 실행중인 것을 볼 수 있다.
뒤에서 설명하겠지만, MySQL 커뮤니티 에디션에서 사용하는 스레드 모델은 커넥션 당 스레드 하나가 사용된다.
하지만 엔터프라이즈 에디션과 Percona MySQL에서는 스레드 풀 모델을 사용할 수 있는데, 이때는 커넥션과 스레드의 관계가 N:1이 된다. (스레드 하나가 여러 커넥션을 처리)
포그라운드 스레드 (클라이언트 스레드)
포그라운드 스레드는 사용자 스레드, 클라이언트 스레드와 같은 의미로 사용된다.
포그라운드 스레드는 최소 MySQL에 접속된 클라이언트의 수만큼 존재하는데, 주로 각 클라이언트 사용자가 요청하는 쿼리 문장을 처리한다.
클라이언트가 사용을 마치고, 커넥션을 종료하면 해당 커넥션을 담당하던 스레드는 다시 스레드 캐시로 되돌아간다.
이때 이미 스레드 캐시에 일정 개수 이상의 대기 중인 스레드가 있으면, 해당 스레드는 캐시에 넣지 않고 종료된다.
포그라운드 스레드는 데이터를 MySQL의 데이터 버퍼나 캐시로부터 가져오며, 버퍼나 캐시에 없는 경우에는 직접 디스크의 데이터나 인덱스 파일로부터 데이터를 읽어와서 작업을 처리한다.
MyISAM 테이블은 디스크 쓰기 작업까지 포그라운드 스레드가 처리하지만, InnoDB 테이블은 데이터 버퍼나 캐시까지만 포그라운드 스레드가 처리하고 나머지 버퍼로부터 디스크까지 기록하는 작업은 백그라운드 스레드가 처리한다.
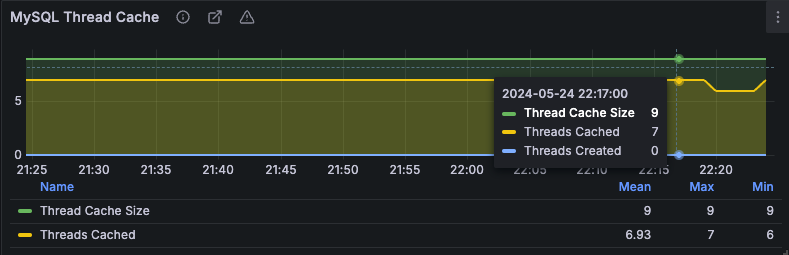
기본으로 설정된 thread_cache_size는
-1인데, 해당 값은 자동으로 설정하겠다는 뜻이다.
기본 값은8 + (max_connections / 100)공식을 사용한다.
따라서Thread Cache Size가 9인 것을 볼 수 있다.
백그라운드 스레드
MyISAM의 경우 포그라운드 스레드가 쓰기 작업을 처리하기에 큰 해당 사항이 없지만, InnoDB의 경우 여러 작업이 백그라운드 스레드로 처리된다.
- 인서트 버퍼 병합
- 로그를 디스크에 기록
- InnoDB 버퍼 풀의 데이터를 디스크에 기록
- 데이터를 버퍼로 읽기
- 잠금, 데드락 모니터링
모두 중요한 역할이지만, 가장 중요한 것은 로그를 기록하는 스레드와 버퍼의 데이터를 기록하는 쓰기 스레드이다.
InnoDB에서도 데이터를 읽는 작업은 포그라운드 스레드에서 처리되기에 읽기 쓰레드를 많이 설정할 필요는 없지만, 쓰기 스레드는 아주 많은 작업을 백그라운드로 처리하기에 일반적인 내장 디스크를 사용할 때는 2~4 정도, DAS 또는 SAN과 같은 스토리지는 디스크를 최적으로 사용할 수 있을 만큼 충분히 설정하는 것이 좋다.
DAS, SAN은 NAS와 같이 시스템에 직접 연결된 저장소가 아닌, 외부 스토리지를 뜻한다.
용량과 확장성이 높지만, 네트워크를 추가로 타야하므로, IO 성능이 낮기에 충분히 설정하라는 것 같다.

읽기 스레드와 쓰기 스레드는
innodb_write_io_threads,inno_read_io_threads전역 변수를 통해 설정하고 확인할 수 있다.
기본 값은 둘 다 4이다.
사용자의 요청을 처리하는 도중 데이터의 쓰기 작업은 버퍼링되어 처리될 수 있지만, 읽기 작업은 절대 지연될 수 없다.
일반 사용 DBMS에는 대부분 쓰기 작업을 버퍼링해서 일괄 처리하는 기능이 탑재되어 있다. (InnoDB 또한 마찬가지)
하지만, MyISAM은 그렇지 않고, 포그라운드 스레드가 쓰기 작업까지 처리하므로, MyISAM을 사용한다면 일반적으로 쓰기 버퍼링 기능을 사용할 수 없다.
메모리 할당 및 사용 구조
MySQL의 메모리 공간은 글로벌 메모리 영역과 로컬 메모리 영역으로 구분할 수 있다.
글로벌 메모리 영역과 로컬 메모리 영역은 MySQL 내에 존재하는 많은 스레드가 공유해서 사용하는 공간 여부에 따라 구분된다.
글로벌 메모리 영역
글로벌 메모리 영역의 모든 메모리 공간은 MySQL이 실행되면서 운영체제로부터 할당된다.
운영체제의 종류에 따라 다르겠지만, 메모리 공간을 100% 할당하거나 예약해둔 뒤, 필요할 때 조금씩 할당해주는 경우가 있다.
따라서 MySQL 서버가 사용하는 정확한 메모리 양을 측정하는 것은 어렵다.
그냥 단순히 MySQL 시스템 변수로 설정해 둔 만큼 메모리를 할당받는다고 생각해도 된다.
포그라운드 스레드의 수와 무관하게 하나의 메모리 공간만 할당되나, 필요에 따라 2개 이상의 메모리 공간을 할당받을 수도 있다.
N개 이상이라고 하더라도, 모든 스레드에 의해 공유된다.
대표적인 글로벌 메모리 영역은 다음과 같다.
- 테이블 캐시
- InnoDB 버퍼 풀
- InnoDB 어댑티브 해시 인덱스
- InnoDB 리두 로그 버퍼
로컬 메모리 영역
세션 메모리 영역이라고 표현하며, MySQL에 존재하는 포그라운드 스레드가 쿼리를 처리하는 데 사용하는 메모리 영역이다.
클라이언트와 MySQL 사이의 커넥션을 세션이라고 하기에, 세션 메모리 영역이라고도 표현한다.
로컬 메모리는 각 포그라운드 스레드별로 독립적으로 할당되며 절대 공유되어 사용되지 않는다.
JVM으로 비유하면, 글로벌 메모리 영역은 Heap, 로컬 메모리 영역은 Stack 처럼 사용되는 것 같다.
가능성은 낮지만 최악의 경우, 소트 버퍼와 같은 로컬 메모리 영역 때문에 MySQL이 메모리 부족으로 멈춰 버릴 수 있으니, 적절한 메모리 공간을 설정하는 것이 중요하다.
로컬 메모리 공간의 또 한 가지 중요한 특징은 각 쿼리의 용도별로 필요할 때만 공간이 할당되고 필요하지 않은 경우에는 메모리 공간을 할당조차도 하지 않을 수 있다.
대표적으로 소트 버퍼와 조인 버퍼가 그렇다.
커넥션 버퍼와 결과 버퍼는 세션이 유지되는 동안 계속 할당된 상태로 존재하고, 소트 버퍼나 조인 버퍼는 쿼리를 실행하는 순간에 할당되었다가 다시 해제된다.

sort_buffer_size와innodb_sort_buffer_size두 종류가 있는데,innodb_sort_buffer_size는 InnoDB 인덱스를 생성하는 동안 데이터 정렬에 사용되는 크기라고 한다.
따라서sort_buffer_size를 조절해야 한다.
기본 값은 256KB이다.
또한 리눅스에서는 256KB 또는 2MB의 임계값이 있는데, 해당 값을 초과하면 메모리 할당 속도가 크게 느려진다고 한다.
이유는malloc()대신mmap()을 사용하기 때문이라고 한다.
https://stackoverflow.com/questions/24166760/sort-buffer-size-vs-innodb-sort-buffer-size
대표적인 로컬 메모리 영역은 다음과 같다.
- 정렬 버퍼
- 조인 버퍼
- 바이너리 로그 캐시
- 네트워크 버퍼
플러그인 스토리지 엔진 모델
맨 처음 MySQL이 독특한 구조를 가진다고 했는데, 대표적인 것이 바로 플러그인 스토리지 엔진 모델이다.
단순 스토리지 엔진 뿐 아닌, 전문 검색 엔진을 위한 검색어 파서, 인증을 위한 Native Authentication, Caching SHA-2 Authentication 등도 모두 플러그인으로 구현되어 제공된다.
기본으로 제공되는 스토리지 엔진 이외에 추가적인 기능이 필요하다면 제 3자가 만든 스토리지 엔진을 다운로드하여 사용하는 것도 가능하다.
뜬금없이 책에서 플러그인을 설명하다가 MySQL 엔진과 스토리지 엔진을 설명하는 부분이 나오는데, 이전에 설명되지 않은 부분이 있어서 여기 작성한다.
GROUP BY, ORDER BY 등 복잡한 처리는 스토리지 엔진 영역이 아닌, MySQL 엔진의 처리 영역인쿼리 실행기에서 처리된다.
또한, 책에서 중요한 내용으로 "하나의 쿼리 작업은 여러 하위 작업으로 나뉘는데, 각 하위 작업이 MySQL 엔진 영역에서 처리되는지 아니면 스토리지 엔진 영역에서 처리되는지 구분할 줄 알아야 한다" 라고 나오는데, 이는 324 페이지의인덱스 컨디션 푸시다운항목을 참고하면 좋을 것 같다.
플러그인은 스토리지 엔진 말고도 여러 기능을 제공하는 것이 많으니, 관심이 있으면 MySQL 메뉴얼을 참고하자.
컴포넌트
MySQL 8.0 이후부터는 기존 플러그인 아키텍쳐를 대체하기 위해 컴포넌트 아키텍쳐가 지원된다.
플러그인은 다음과 같은 단점이 존재한다.
- MySQL과 인터페이스 할 수 있고, 플러그인끼리 통신 불가
- MySQL 서버의 변수나 함수를 직접 호출하기에 안전하지 않음 (캡슐화 안 됨)
- 상호 의존 관계를 설정할 수 없어서 초기화가 어려움
플러그인과 마찬가지로 관심이 있으면 MySQL 메뉴얼을 참고하자.
쿼리 실행 구조
쿼리를 실행하는 관점에서 SQL 구조는 다음과 같다.

쿼리 파서
사용자 요청으로 들어온 쿼리 문장을 토큰(MySQL이 인식할 수 있는 최소 단위의 어휘나 기호)으로 분리해 트리 형태의 구조로 만들어 내는 작업을 수행한다.
쿼리 문장의 기본 문법 오류는 이 과정에서 발견된다.
전처리기
파서 과정에서 만들어진 파서 트리를 기반으로 쿼리 문장에 구조적인 문제점이 있는지 확인한다.
각 토큰을 테이블 이름이나 컬럼 이름, 또는 내장 함수와 같은 개체를 매핑하여 존재 여부와 객체 접근 권한 등을 확인하는 과정을 이 단계에서 수행한다.
실제 존재하지 않거나 권한상 사용 할 수 없는 개체의 토큰은 이 단계에서 걸러진다.
옵티마이저
사용자의 요청으로 들어온 쿼리 문장을 저렴한 비용으로 가장 빠르게 처리할지를 결정한다.
실행 엔진 (쿼리 실행기)
실행 엔진은 밑의 핸들러와 영향이 깊은데, 핸들러에 명령을 요청하여 결과를 사용자나 다른 모듈로 넘기는 역할을 한다.
핸들러 (스토리지 엔진)
실행 엔진의 요청에 따라 데이터를 디스크로 저장하고, 디스크로부터 읽어 오는 역할을 한다.
핸들러는 스토리지 엔진을 의미한다.
쿼리 캐시
쿼리 캐시는 과거 빠른 응답을 필요로 하는 웹 기반의 응용 프로그램에서 매우 중요한 역할을 담당했다.
하지만 쿼리 캐시는 테이블의 데이터가 변경되면 캐시에 저장된 결과 중에서 변경된 테이블과 관련된 것들을 모두 삭제해야 했기에, 심각한 동시 처리 성능 저하를 유발했다.
또한 MySQL이 발전하며 성능이 개선되며, 쿼리 캐시는 계속된 성능 저하와 많은 버그의 원인이 되어 MySQL 8.0부터 역사의 뒤안길로 사라졌다.
스레드 풀
MySQL 엔터프라이즈 에디션은 스레드 풀 기능을 제공한다.
하지만 책에서는 MySQL 엔터프라이즈 에디션의 스레드 풀이 아닌 Percona MySQL에서 제공하는 스레드 풀 기능을 설명한다.
Percona MySQL에 대해 소개하는 블로그가 있는데, 기존 InnoDB 스토리지 엔진을 사용하는 MySQL보다 더 좋은 성능을 낸다고 한다.
하지만 2013년 글이기도 하고, 서비스 기업에서 MySQL을 고집하는 이유는 안정성이 더 우선이기 때문이지 않을까하는 뇌피셜 (DB는 변경이 무척 힘들고, 데이터 손실 가능성이 있으므로)
스레드 풀을 사용했을 때, 더 적은 포어그라운드 스레드로 제한된 개수의 스레드 처리에만 집중할 수 있게 하여 서버의 자원 소모를 줄이는 것이 목적이다.
스레드 풀은 성능을 높이는 것이 목적이 아니다.
마치 세마포어와 비슷한데, 한 번에 수많은 요청이 들어왔을 때, 스레드 풀 덕분에 처리할 수 있는 요청만 처리되므로 서버의 자원 소모를 줄인다.
TMI로 자바 21의 가상 스레드의 단점 중 하나가 이와 같다.
MySQL에 관한 내용이 아닌, 특정 구현체에 관한 내용이므로 생략한다.
트랜잭션 지원 메타데이터
DB 서버에서 테이블의 구조 정보와 스토어드 프로그램(프로시저) 등의 정보를 데이터 딕셔너리 또는 메타데이터라고 한다.
MySQL 5.7 까지는 테이블의 구조를 FRM 파일에 저장하고 일부 스토어드 프로그램 또한 파일 기반으로 관리했다.
하지만 파일 기반의 메타데이터는 생성 및 변경 작업이 트랜잭션을 지원하지 않기에 테이블의 생성 또는 변경 도중 MySQL 서버가 비정상적으로 종료되면 일관되지 않은 상태로 남는 문제가 있었다.
MySQL 8.0 버전부터는 이러한 문제를 해결하기 위해 메타데이터 정보를 모두 InnoDB 테이블에 저장하도록 개선됐다.
또한 MySQL이 작동하는 데 기본적으로 필요한 테이블들을 시스템 테이블이라고 하는데, 마찬가지로 8.0 버전부터는 모두 InnoDB 스토리지 엔진을 사용하도록 개선됐다.
시스템 테이블과 메타데이터 정보를 모두 모아 mysql DB에 저장한다.
mysql.ibd라는 이름의 테이블스페이스로 저장되는데, 해당 파일은 다른*.ibd파일과 함께 특별히 주의해야 한다.
이렇게 메타데이터와 시스템 테이블 모두 트랜잭션 기반의 InnoDB 스토리지 엔진에 저장되며 스키마 변경 작업 중 비정상적인 종료가 발생하더라도 Atomic을 보장받을 수 있다.
우테코 DB 강의 때 MyISAM vs InnoDB 과정에서 설명했던 것 같다.
