내가 하고자 하는 것
추후 정리해서 올릴거지만, 음성으로 말하면 음성으로 대답해주는 챗봇을 만들어보고자 이것저것 건들어보게되었다.
게다가 이번 Chat-GPT4o 가 출시되면서 파급효과가 더 커지고 말하는 음성도 매우 자연스러운것을 보고,
개인적인 재미측면에서는 내가 좋아하는 게임 캐릭터봇과 대화하는 형태나
비즈니스 측면에서는 서비스 CS를 해주는 봇
콘텐츠 측면에서는 재미있게 책을 읽어주는 봇으로 만들수 있을 것 같아 시작하게 되었다.
개발 과정 정리
Java, Spring이 주 언어다 보니 Python으로 적용해보면서 여러 시행착오가 있었다.
(에디터라던지, 패키지및 가상환경이라던지, 문법이라던지)
그래도 내가 깊게 들어가는 것이 아니기에 금방할 수 있었고,추후에 관련된 개념은 정리하고자 한다.
0. 세팅하기
- 파이썬 설치하기
- Openai 설치하기
- whisper 설치하기
- 개인적인 환경세팅
- fastAPI 설치
- conda 설치
-
별도의 가상환경을 만들어서 위에 있는 패키지들을 설치함.
-
1. 음성 → 텍스트 변환
위스퍼 모델 연결하기
-
OpenAI에서 제공해주는 음성인식 모델이다.
링크 : https://github.com/Gloom-shin/whisper/blob/main/README.md -
만약 실행시
UserWarning: FP16 is not supported on CPU; using FP32 instead warnings.warn("FP16 is not supported on CPU; using FP32 instead")이 나타났다면- Whisper 모델이 CPU에서 FP16 대신 FP32를 사용하고 있다는 경고가 나타나고 있는 것으로 이는 Whisper가 CPU에서 실행될 때 나타나는 정상적인 경고이며, 모델이 제대로 작동하고 있다는 의미
-
작성 코드
from fastapi import FastAPI, UploadFile, File, HTTPException
import whisper
import os
from fastapi.responses import JSONResponse
import logging
app = FastAPI()
# Whisper 모델 로드
model = whisper.load_model("base")
@app.get("/")
def read_root():
return {"message": "Welcome to the Whisper TTS API"}
@app.post("/transcribe/")
async def transcribe_audio(file: UploadFile = File(...)):
# if file.content_type not in ["audio/mpeg", "audio/wav", "audio/mp4", "audio/x-m4a"]:
# raise HTTPException(status_code=400, detail="Invalid file type")
audio_path = f"temp_{file.filename}"
with open(audio_path, "wb") as audio_file:
audio_file.write(await file.read())
try:
result = model.transcribe(audio_path)
except Exception as e:
logging.error(f"Error during transcription: {e}")
raise HTTPException(status_code=500, detail="Error during transcription")
finally:
os.remove(audio_path)
return JSONResponse(content=result)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="127.0.0.1", port=8000)이 과정을 통해, 음성파일 전송시 텍스트응답이 잘 온다는 것을 확인하였다.
2.텍스트 → GPT 연결
- openAI설치 필요!
- 공식문서 링크 : https://platform.openai.com/docs/guides/text-generation/chat-completions-api
from fastapi import FastAPI, UploadFile, File, HTTPException
import openai
import os
import whisper
from fastapi.responses import JSONResponse
import logging
app = FastAPI()
# OpenAI API 키 설정
openai.api_key = "키값"
# client = OpenAI(
# # This is the default and can be omitted
# )
#whisper 모델 로드
model = whisper.load_model("base")
@app.get("/")
def read_root():
return {"message": "Welcome to the Whisper TTS API"}
@app.post("/transcribe/")
async def transcribe_audio(file: UploadFile = File(...)):
# if file.content_type not in ["audio/mpeg", "audio/wav", "audio/mp4", "audio/x-m4a"]:
# raise HTTPException(status_code=400, detail="Invalid file type")
# 업로드된 오디오 파일 저장
audio_path = f"temp_{file.filename}"
with open(audio_path, "wb") as audio_file:
audio_file.write(await file.read())
try:
# Whisper 모델을 사용하여 음성 인식
result = model.transcribe(audio_path)
text = result["text"]
logging.info(f"Transcription text: {text}")
# ChatGPT에 질문
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": text
}
],
)
logging.info(f"ChatGPT response: {response}")
response_message = response.choices[0].message.content
except openai.error.PermissionError as e:
logging.error(f"Permission error: {e}")
raise HTTPException(status_code=403, detail="Permission denied. Check your API key's permissions.")
except openai.error.InvalidRequestError as e:
logging.error(f"Invalid request error: {e}")
raise HTTPException(status_code=400, detail="Invalid request. Check your API request parameters.")
except openai.error.RateLimitError as e:
logging.error(f"Rate limit error: {e}")
raise HTTPException(status_code=429, detail="Rate limit exceeded. Please try again later.")
except Exception as e:
logging.error(f"Error during transcription or OpenAI API call: {e}")
raise HTTPException(status_code=500, detail=f"Error during transcription or OpenAI API call: {str(e)}")
finally:
# 임시 파일 삭제
os.remove(audio_path)
return JSONResponse(content={"transcription": text, "chatgpt_response": response_message})
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile = File(...)):
content = await file.read()
return {"filename": file.filename, "content_type": file.content_type, "content_length": len(content)}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="127.0.0.1", port=8001)
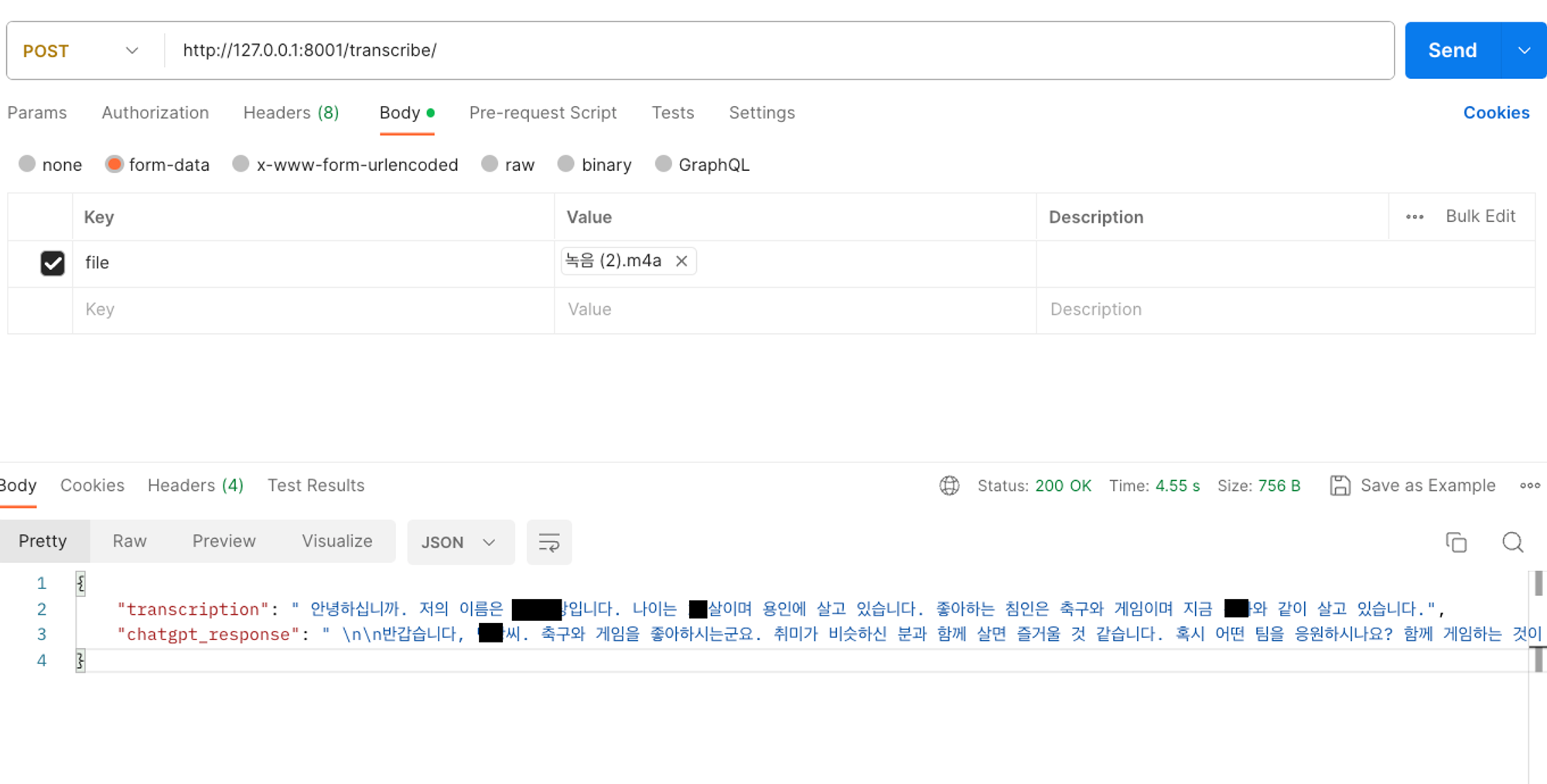
간단한 테스트를 통해, 음성파일 전송시 Chat-GPT가 응답해주는 것을 확인했다.
다만, 대답하는 GPT에게 내가 원하는 캐릭터의 형태로 시스템을 넣어줘야하는 작업과
원하는 목소리로 응답할 수 있는 작업이 추가적으로 필요하다.
에러 모음
1. INFO: 127.0.0.1:51267 - "POST /transcribe/ HTTP/1.1" 422 Unprocessable Entity
2. ERROR:root:Error during transcription or OpenAI API call: text
- 여러가지 이유가 있는 에러있겠지만, 보통 전송하는
content가 문제인 경우 나타난다.
# 에러 나는 코드
messages=[
{
"role": "system",
"content": "You are a poetic assistant, skilled in explaining complex programming concepts with creative flair."
},
{
"role": "user",
"content": text
}
]
## 변경한 코드
messages=[
{
"role": "user",
"content": text
}
],
3. ERROR:root:Error during transcription or OpenAI API call: type object 'OpenAI' has no attribute 'ChatCompletion’
- You tried to access openai.ChatCompletion, but this is no longer supported in openai>=1.0.0 - see the README at https://github.com/openai/openai-python for the API.
- You can run
openai migrateto automatically upgrade your codebase to use the 1.0.0 interface.
→ 과거 문법을 사용하고 있기 땜에
→ChatCompletion.create 사용:
- Alternatively, you can pin your installation to the old version, e.g.
pip install openai==0.28 - 버전을 다운그레이하여 해결할 수 있으나, 추천하지 않다고 하여 최신 문법으로 사용
pip install --upgrade openai최신 버전으로 바꿔주기
# 이전 문법
response = openai.ChatCompletion.create(
# 최신 문법
response = openai.chat.completions.create(
4. ERROR:root:Error during transcription or OpenAI API call: You exceeded your current quota, please check your plan and billing details. For more information on this error, read the docs:
- OpenAI API의 사용한도가 초과했다는 의미로 크레딧 충전이 필요하다.
- 결제하면 해결됨.
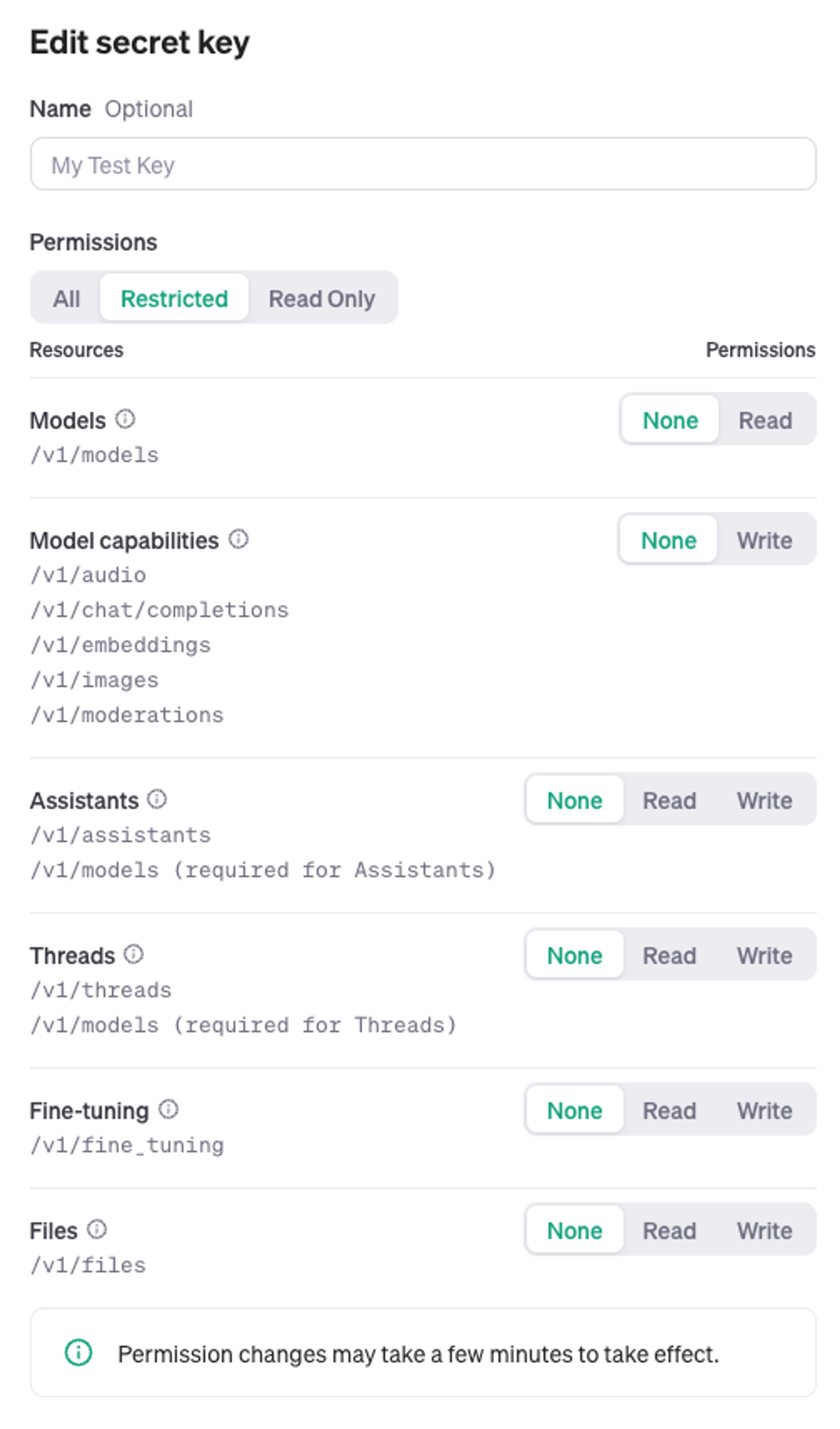
5. ERROR:root:Error during transcription or OpenAI API call: You have insufficient permissions for this operation. Missing scopes: model.request. Check that you have the correct role in your organization (Reader, Writer, Owner) and project (Member, Owner), and if you're using a restricted API key, that it has the necessary scopes.
- 해당 API키가 권한이 없다는 형태로 초기 생성된 API는 기본적으로 권한이 다 잠겨있다.
- Project → API keys → edit key 에서 변경해주면 됨.
6. TypeError: Object of type ChatCompletion is not JSON serializable
- 응답 값의 형태가 변경되어, 나타나는 에러로 최신버전으로 변경해주면 된다.
response_message = response.choices[0].message['content'].strip()response_message = response.choices[0].message.content마치며
- 연동작업을 하다보니, 알게된 부분보다 모르는 영역이 점점 더 늘어났다.
- model들은 어떤차이가 있는지?, system은 어떻게 사용하는지, assistant의 기능이 정확히 무엇인지?등들이 있으며
- 또 어떤 기능들을 사용할 수 있는지 알아보고 싶은 것들 투성이다..🫢
