
DNN 실습을 위해 MNIST 손글씨 데이터를 이용해보자. MNIST는 워낙 유명한 데이터셋이기 때문에 tensorflow에서 자체적으로 데이터를 제공하고 있다.
데이터 불러오기
import pandas as pd
from tensorflow.keras.datasets import mnist
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape, x_test.shape)
print(y_train.shape, y_test.shape)
MNIST데이터는 6만개의 학습용 이미지 데이터와 1만개의 테스트용 이미지 데이터로 구성되어있다. 숫자 하나당 28 by 28의 그레이 스케일(흑백) 이미지이다. 잘 불러왔는지 시각화를 통해 확인해보자.
import matplotlib.pyplot as plt
import random
for i in range(1,4,1):
for j in range(1,4,1):
plt.subplot(i,4,j)
plt.imshow(x_train[random.randint(0,60000)],cmap="gray")
plt.show()
데이터가 잘 불러와졌음을 확인할 수 있다.
데이터 전처리
MNIST 이미지 데이터의 shape이 28 by 28이기 때문에 학습을 위해서는 1 by 784로 변환해주어야 한다.
그레이 스케일 데이터의 특성상 데이터들의 최솟값이 0, 최댓값이 255이기 때문에 모든 값들을 255로 나누는 방법을 통해 스케일링을 진행해준다.
x_train_new = x_train.reshape(-1, 784)
x_test_new = x_test.reshape(-1, 784)
x_train_ = x_train_new / 255.0
x_test_ = x_test_new / 255.0MNIST 데이터셋은 해당 데이터가 0부터 9까지의 숫자 중 어떤 숫자인지 분류하는 다중 분류 목적의 데이터셋이다. DNN의 다중분류를 위해서는 원-핫 인코딩을 진행하는 것이 효과적이다.
원-핫 인코딩은 답어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식을 의미한다.
tensorflow의 keras에서는 원-핫 인코딩을 쉽게 할 수 있도록 도와주는 to_categorical함수를 제공하고 있다.
from keras.utils import to_categorical
y_train_new = to_categorical(y_train)
y_test_new = to_categorical(y_test)
y_train_new
모델 설계
DNN모델 구축을 위해 tensorflow의 keras라이브러리를 이용했다.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Dropout
from sklearn.metrics import accuracy_score
model = Sequential([
Dense(512, input_dim=784, activation='relu'),
Dense(256, activation='relu'),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dense(32, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])입력층에서의 input_dim은 28 by 28의 데이터이기 때문에 784로 지정했고, 출력층에서의 활성함수는 softmax로 지정하였다. 중간 은닉층의 활성함수는 모두 relu로 지정하였다. 보통 중간 은닉층에서의 활성함수는 relu를 사용하는데, 그 이유는 여러가지가 있지만 기본적으로 relu함수의 계산 효율성이 다른 함수들보다 좋다고 알려져있다.
출력층에서의 활성함수는 이진분류일 경우와 다중분류일 경우로 나뉘게 되는데, 보통 이진분류의 경우는 sigmoid함수를 사용하고 다중분류인 경우에는 softmax를 사용한다.
설계한 모델 구성을 살펴보자.
model.summary()
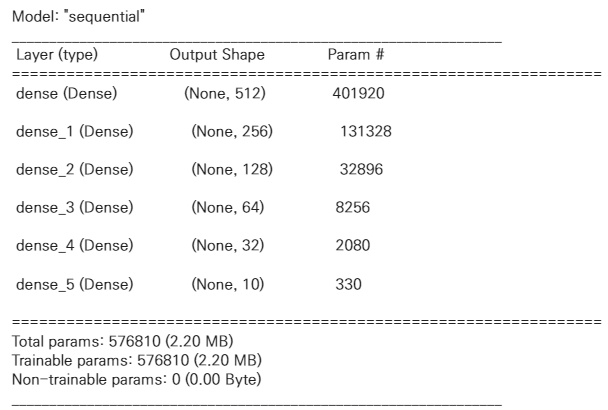
각 layer들이 잘 쌓아진 것을 볼 수 있다.
모델 학습
model.fit(x_train_, y_train_new, validation_data=(x_test_, y_test_new), epochs=15)

데이터의 양이 많은 관계로 epochs는 15만 지정하고 학습을 진행했다.
모델 예측 결과
y_pred = model.predict(x_test_)
y_pred
위의 형식으로 분류값이 나오는 이유는 활성함수를 거쳐서 나오기 때문이다. 즉, 해당 인덱스의 해당하는 값일 확률을 나타내는 것이다.
numpy에서 제공하는 np.argmax()함수를 이용하면 가장 큰 인덱스를 리턴할 수 있다.
import numpy as np
t = []
for i in range(len(y_pred)):
t.append(np.argmax(y_pred[i]))
accuracy_score(y_test, t)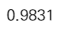
약 98.31%의 정확도를 가진 모델을 생성하였다.
