머신러닝
머신러닝 = 기계학습
'학습'은 기계가 미래의 유사한 경험을 향상시키기 위해 과거의 경험을 활용하는 것이다. 기본적인 학습의 과정은 다음과 같다.
- 데이터 입력: 새로운 이미지, 텍스트, 영상, 센서 데이터 등
- 추상화: 데이터에 의미를 부여(Training 과정)
- 일반화: 추상적인 지식을 실행에 사용할 수 있는 형태로 조절하는 과정
머신러닝 프로세스
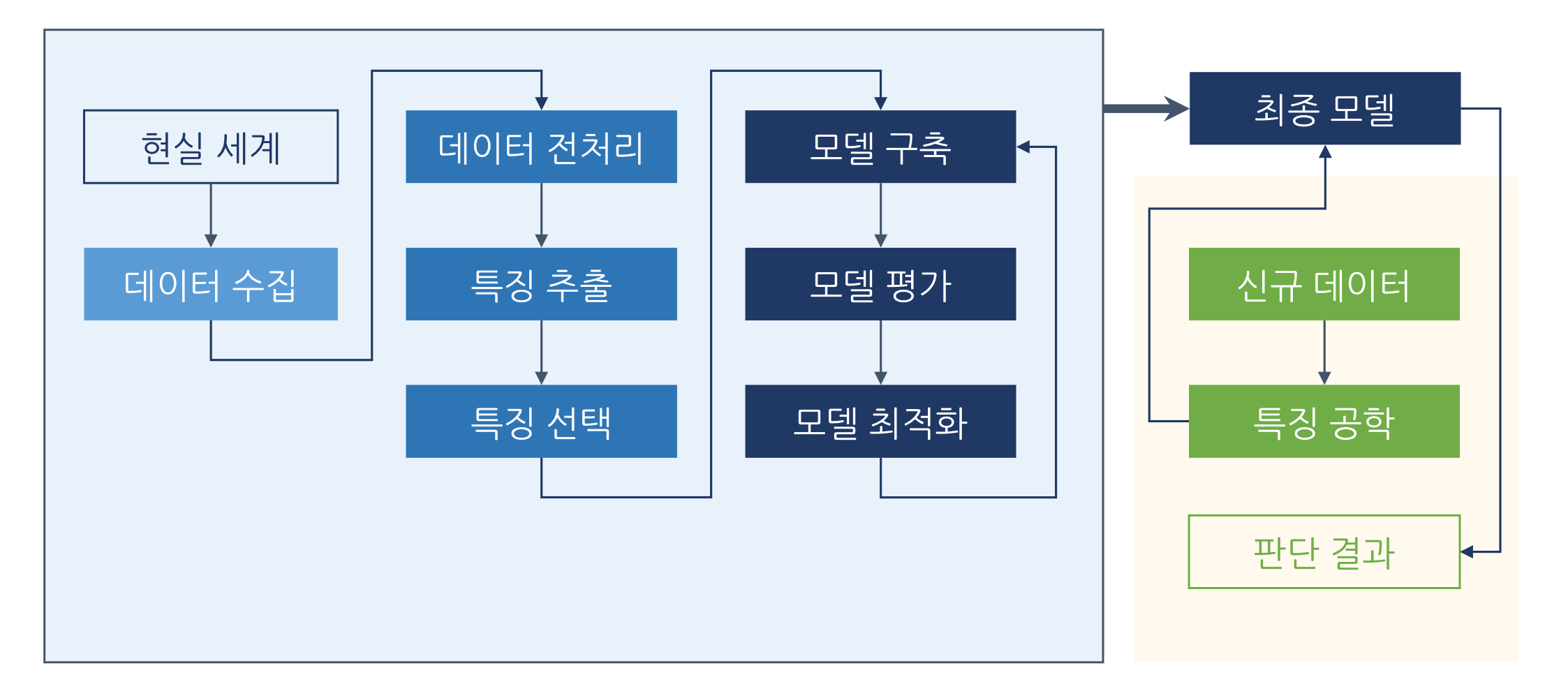
특징 공학(Feature Engineering)
특징, 즉 feature는 관찰 대상에서 발견한 개별적이고 측정 가능한 경험적 속성을 의미한다. 특징 공학은 Raw data를 예측 모델의 기저에 있는 문제들을 잘 표현해주는 특징들로 변환하는 것을 의미한다. 특징 공학 과정을 거치면서 처음 보는 데이터에 대한 모델의 정확도가 향상된다. 좋은 특징들은 모델에 유연성을 부여하고 모델을 단순화하며, 좋은 결과를 도출하는 데 도움을 준다.
모델 설계
- 단일 모델
- 데이터 특성에 맞는 모델
- 다중 모델
- 앙상블 모델
- 여러개의 모델을 연결해서 하나의 모델처럼 사용
- 모델 판단 결과를 새로운
feature로 사용
편향과 분산: Bias and Variance
편향은 데이터 내 숨겨진 모든 정보를 고려하지 않아 잘못 학습을 하는것을 의미한다(under fitting). 분산은 데이터 내의 에러와 노이즈까지 학습에 고려하는 것을 의미한다(over fitting). 기본적으로 머신러닝의 학습은 아래 수식에서 (가중치)와 (편향)을 찾아가는 과정을 의미한다.
과적합과 부적합
과적합(over fitting)은 학습한 모델이 학습 데이터에 과도하게 맞춰져 학습되었거나 지나치게 복잡한 모델을 사용한 경우에 발생할 수 있다.
부적합(under fitting)은 학습한 모델이 데이터의 흐름을 파악할 수 없을만큼 지나치게 단순한 경우에 발생할 수 있다.
모델 성능과 검증
머신러닝 모델의 정확도가 100%라면 과적합인지, 혹은 머신러닝을 적용할 필요가 있는 도메인인지 고려해본다. 머신러닝은 경험을 근간으로 하는 일반화의 싸움이기 때문에 기본적으로 99.9%를 지향한다. 따라서 좋은 모델이라고 이야기 하기 전에 다양한 모델에 실험을 해봤는지부터 확인해보아야 하며 정확도의 기준은 실험에 사용되는 도메인의 속성과 사용한 알고리즘에 따라 달라진다.
회귀 모델 평가(Regression)
회귀 모델은 원래 값과 예측한 값이 얼마나 차이 나는지 평가한다.
MAE(Mean Absolute Error)- 편차에 절댓값을 씌운 결과의 평균(작은 에러에 민감)
MSE(Mean Squared Error)- 편차 제곱의 평균(큰 에러를 최대한 ↓)
MAE(Median Absolute Error)- 중앙값에 절댓값을 씌운 결과에 평균(이상치에 영향 ↓)
R2 Score- 기존 생성 모델이 새로운 샘플에 얼마나 적합할지 판단해주는 지표(0~1)
군집 모델 평가(Clustering)
데이터를 잘 군집화 했는지 평가한다(같은 cluster 안에 있는 데이터들의 유사성 평가).
Adjusted Rand Index→ 악성코드에서는 사용 ↓- 원래 값과 예측된 값이 얼마나 유사도를 가지고 있는지 평가
Mutual Information Based Scores- ARI와 유사한 맥락, 유사도가 아닌 부합 정도
Homogeneity,completeness and V-measure- 원래 값을 이용 - 엔트로피 기반
Fowlkes-Mallows Scores- 원래 값을 이용 (Confusion Matrix 기반)
Silhouette Coefficient- 원래 값읆 모를 때 사용: 모델 자체만을 가지고 판단 (평균 거리)
분류 모델 평가(Classification)
정답은 정답으로, 오답은 오답으로 잘 분류했는지 평가한다.
Accuracy Score- 얼마나 잘 예측을 했는지 평가 (정답 / 전체)Confusion Matrix- 알고리즘 성능을 시각화해주는 에러 표
Precision, Recall and F-measure(정밀도, 재현율, F-Score)
- Precision(정밀도): 전체 Positive 개수 대비 정답의 비율 → 오탐
- Recall(재현율): 전체 True 개수 대비 정답의 비율 → 미탐
- F-measure: 정밀도와 검출율을 하나의 숫자로 표현하는 방법
특징 공학(Feature Engineering)
특징 공학(Feature Engineering)
-
통계학 VS 머신러닝
- 통계학은 수량적 비교를 기초로 많은 사실을 통계적으로 관찰, 처리하는 방법을 연구하는 학문이다.
- 머신러닝은 컴퓨터가 주어진 데이터에서 의미 있는 정보를 찾아낼 수 있도록 해 주는 모든 기술 영역을 의미한다.
-
통계학: 데이터에서 의미를 찾아내는 학문
-
머신러닝: 데이터에서 찾은 의미를 활용하기 위한 학문
-
확률: 일정한 조건 아래에서 어떤 사건이나 사상이 일어날 가능성의 정도 또는 수치
- 조건부 확률: 어떤 사건 B가 일어났을 때 사건 A가 발생할 확률
- 베이즈 정리(Bayes Theorem)
- 두 확률 변수의 사전 확률과 사후 확률 사이의 관계를 나타내는 정리
- 변화를 계산 - A의 확률 P(A)는 B가 관측된 후 P(A|B)로 변화
-
확률 분포
- 이산확률분포: 특정 값을 얻는 확률
- 연속확률분포: 특정 범위를 얻는 확률
-
정규 분포(Normal Distribution) = (Gaussain Distribution)
- 연속 데이터를 위한 모델, 평균과 분산으로 표현한 분포 그래프
- 어떤 변수 X가 특정한 두 값(a, b) 사이에 있을 확률 = 면적
-
feature engineering 프로세스
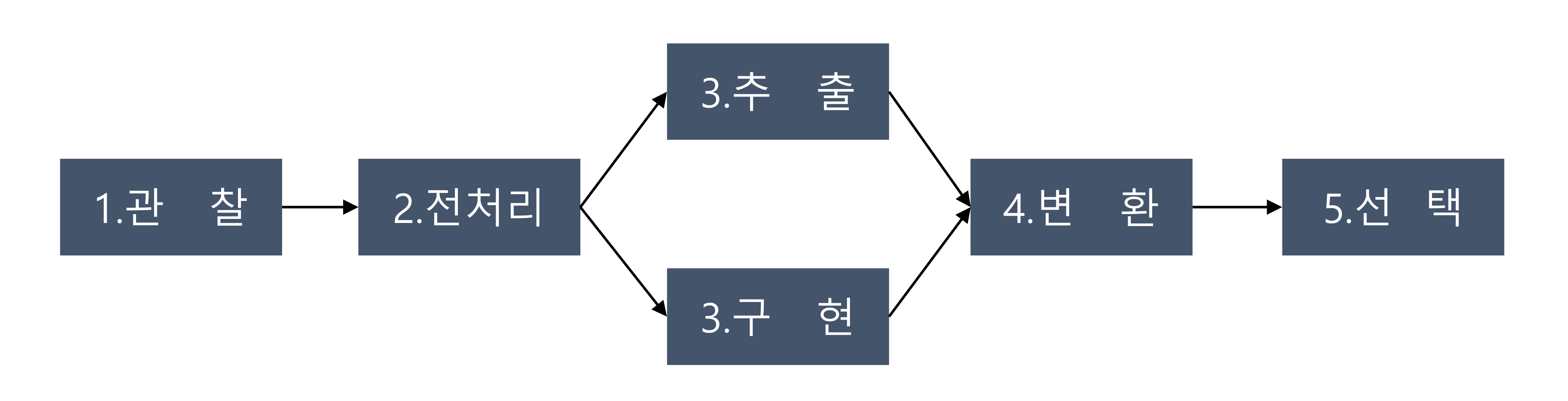
-
데이터 관찰: 데이터의 형식은 무엇인가? 에러는 없는가? 데이터 단위는?
-
데이터 전처리
- 형식화: 분석 목적에 맞는 적절한 파일 형식으로 변환 또는 DB에 저장
- 정제: 문제 해결에 도움이 되지 않는 데이터는 제거, 누락된 데이터 처리
- 샘플링: 초기 실험에는 일부 데이터만 선택해서 모델링을 할 필요 有 (학습 시간↑)
-
특징 추출(Parsing): 데이터가 알고리즘이 처리하기에 너무 많은 정보를 담고 있는 경우, 특징만 추출
- ex) 파형 데이터 → 주파수, 이미지 → 경계선 정보
특징 구현(Processing): 직접 특징을 추출하는 방법 → 데이터 구조와 기저 정보에 대한 깊은 이해 必
-
데이터 변환
- 스케일링: 전처리 후 데이터의 단위는 제각각, 범위를 [0, 1]로 치환해주는 것이 학습에 유리
-
min/max 스케일링
-
- 분해: 하나의 특징이 복잡한 여러 개념을 포함하는 경우, 여러 개의 특징으로 분리 or 선택적 추출 →
PCA(Principal Component Analysis): 주성분 분석 (대표적인 차원 축소 알고리즘)
- 결합: 두 가지를 동시에 고려했을 때, 더 큰 의미를 가지는 특징들은 하나의 특징으로 결합
- 변환 - 특정 변수를 모델에 사용할 수 있는 데이터 형식으로 변환
One Hot Encoding- 범주형 데이터를 one-of-K 형태로 변환하는 방법
- 스케일링: 전처리 후 데이터의 단위는 제각각, 범위를 [0, 1]로 치환해주는 것이 학습에 유리
-
특징 선택
- 필터링: 탐색 과정을 통해 모델링에 사용할 특징을 선별, 그 결과를 학습 모델에 전달하는 방법
- 직관적이고 속도가 빠르지만 결과에 대한 피드백을 받을 수 없다는 것이 단점
- 래핑: 탐색 과정과 학습 과정을 반복적으로 실행하면서 최적의 특징 조합을 찾는 방법
- 필터링과 정반대의 단점
- 필터링: 탐색 과정을 통해 모델링에 사용할 특징을 선별, 그 결과를 학습 모델에 전달하는 방법
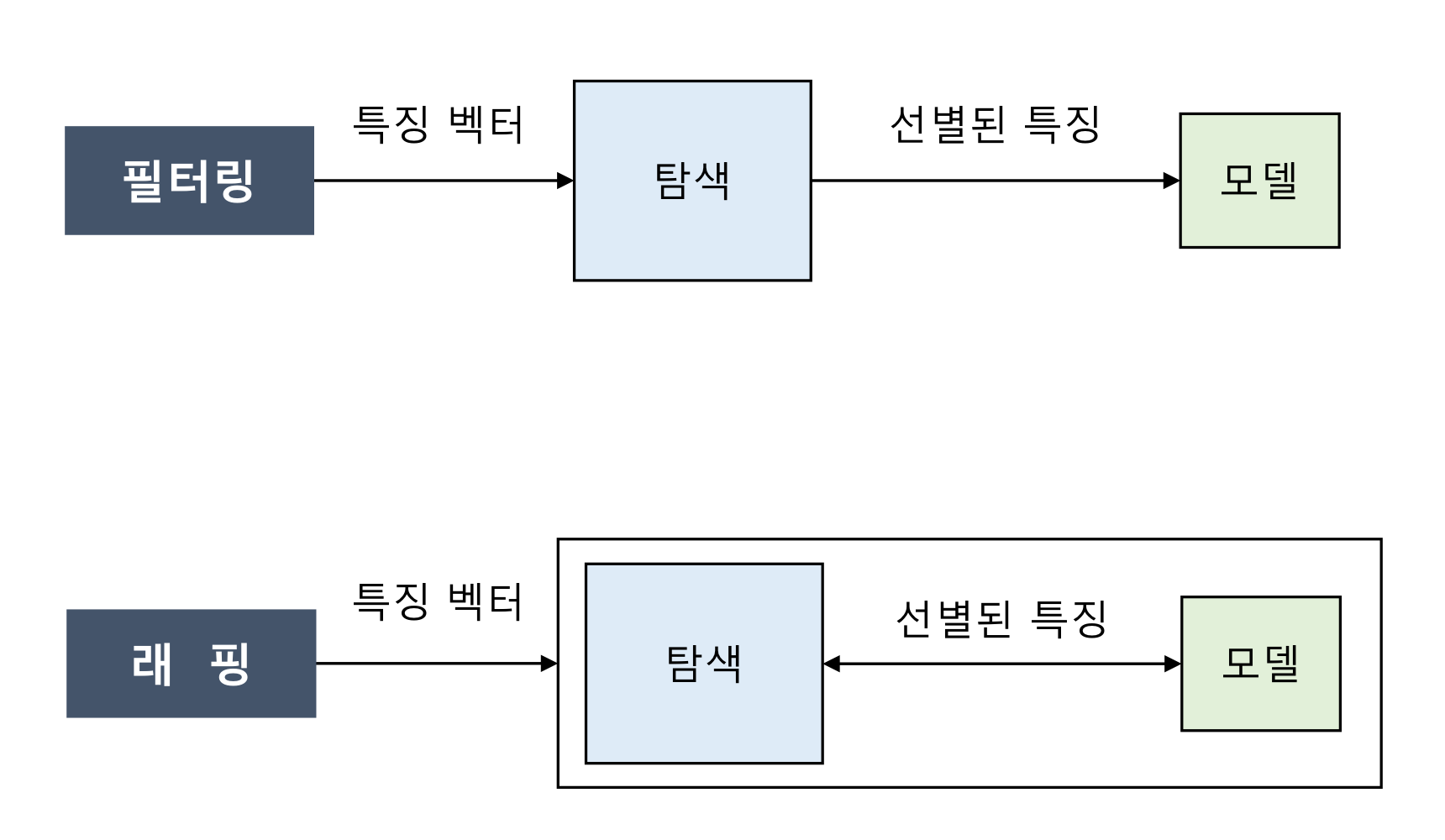
- 관련성
- 특징이 모델의 성능에 영향을 미치는 정도를 판단하기 위한 수치
- 모델 학습에 반드시 필요한 특징 → 높은 관련성
- 추가할 경우 모델 성능 향상에 도움이 되는 특징 → 낮은 관련성
- 유용성
- 주어진 모델에서 에러를 최소화하는 것과 관련된 수치
- 신경망의 ‘Bias’가 높은 유용성을 가진 특징의 대표적인 예
선형 회귀(Linear Regression)
선형 회귀(Linear Regression)
-
기계가 학습하는 방법
- 아무렇게나 그리기
- 정답 비교하기
- 선 조정하기
- 2, 3 반복
- 가장 잘 맞추었다면, 학습 완료
-
선형 회귀(Linear Regression)
- 종속 변수 와 한 개 이상의 독립 변수 와의 선형 상관 관계를 모델링 하는 기법
- 오차가 가장 적은 함수를 찾는 문제
-
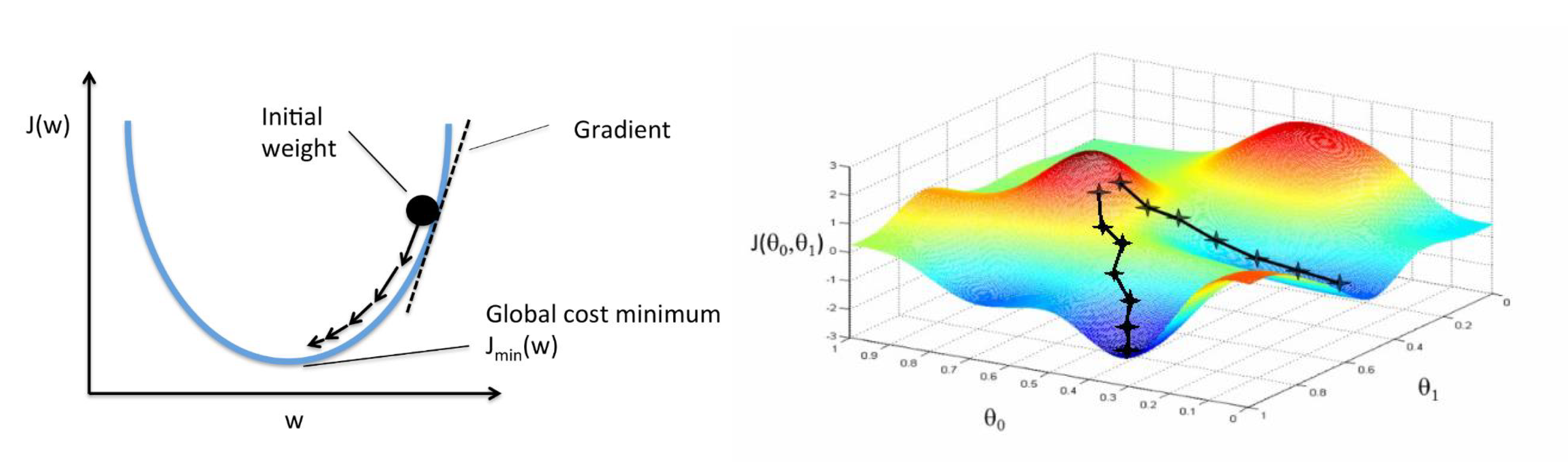
경사 하강법(Gradient Descent)
- 최적의 Cost Function값을 찾아 나가는 과정 → 가장 낮은 곳을 찾아라
- 초기값 w를 시작으로 w값을 계속 변경해가며 비용을 계산
- 비용이 가장 낮은 지점을 찾으면 stop → 최적의 해
Drop-out과 머신러닝 팁
Drop-out
서로 연결된 연결망에서 0부터 1사이의 확률로 뉴런을 제거하는 기법이며 주로 과적합을 방지하기 위해 사용한다.
Feature 자동 선택
feature가 너무 경우, 어떤 것이 중요한 feature가 될 수 있는지 파악하는 시간을 단축하기 위한 목적이다.
import sklearn.ensemble as ske
from sklearn.feature_selection import SelectFromModel
fsel = ske.ExtraTreesClassifier().fit(x, y)
model = SelectFromModel(fsel, prefit=True)
X_new = model.transform()
nb_features = X_new.shape[1]LazyPredict
- 자동으로 Best Model을 찾아주는 패키지
- 코드 한 줄로 여러 ML모델을 불러와 학습시키고, 추론 결과도 확인 가능
- 여러 모델들의 성능 지표도 비교 가능
- 더 좋은 모델을 가려낼 수도 있음
- 다만, 파라미터를 조정하는 기능은 따로 제공되지 않음
from lazypredict.Supervised import LazyClassifier
clf = LazyClassifier(verbose=0, predictions=True)
models, predictions = clf.fit(x_train, x_test, y_train, y_test)