개인정보 개념 이해
개인정보란?
개인정보보호법 제2조 1호
제2조(정의) 이 법에서 사용하는 용어의 뜻은 다음과 같다.
1. “개인정보”란 살아있는 개인에 관한 정보로서 다음 각 목의 어느 하나에 해당하는 정보를 말한다.
가. 성명, 주민등록번호 및 영상 등을 통하여 개인을 알아볼 수 있는 정보
나. 해당 정보만으로는 특정 개인을 알아볼 수 없더라도 다른 정보와 쉽게 결합하여 알아볼 수 있는 정보.
이 경우 쉽게 결합할 수 있는지 여부는 다른 정보의 입수 가능성 등 개인을 알아보는 데 소요되는 시간,
비용, 기술 등을 합리적으로 고려하여야 한다.
다. 가목 또는 나목을 제1호의2에 따라 가명처리함으로써 원래의 상태로 복원하기 위한 추가 정보의
사용ㆍ결합 없이는 특정 개인을 알아볼 수 없는 정보(이하 “가명정보”라 한다.)
-
살아 있는
사망한 자, 법인, 단체 또는 사물에 관한 정보는 개인정보가 아니다. -
개인에 관한
집단의 통계값 등은 개인정보가 아니다. -
정보
정보의 종류, 형태, 성격, 형식 등에 관하여는 특별한 제한이 없다. -
개인을 알아볼 수 있는 정보
이름, 전화번호, 주민번호, 이메일, 사진, 지문, 음성, 필체 등 -
다른 정보와 쉽게 결합하여 알아볼 수 있는 정보
주어진 정보의 재료들을 조합해 한 개인을 특정할 수 있으면 개인정보로 간주할 수 있다.
개인정보 이용 및 제공
개인정보는 수집 목적 범위에 해당하는지, 목적 외 이용/제공 근거에 해당하는지 판단하고 두 조건에 해당할 경우 가명처리 후 이용 및 제공이 가능하다.
가명정보
가명정보는 원래의 상태로 복원하기 위한 추가 정보의 사용 및 결합 없이는 특정 개인을 식별할 수 없는 정보를 말한다. 복원을 위한 추가 정보란 이름 혹은 주민등록번호 등의 개인정보를 임의의 다른 값으로 무작위 변경하는 것이 아니라 일정한 기준표 혹은 알고리즘을 통해 변경했을 때 기준표와 알고리즘이 추가 정보에 해당한다.
용어정리
개인정보
살아있는 개인에 관한 정보로서 다음의 정보를 포함한다.
- 성명, 주민등록번호 및 영상 등을 통하여 개인을 알아볼 수 있는 정보
- 해당 정보만으로는 특정 개인을 알아볼 수 없더라도 다른 정보와 쉽게 결합하여 알아볼 수 있는 정보
가명정보
개인정보를 가명처리 함으로써 원래의 상태로 복원하기 위한 추가정보의 사용 및 결합 없이는 특정 개인을 알아볼 수 없는 정보
익명정보
시간, 비용, 기술 등을 합리적으로 고려할 때 다른 정보를 사용하더라도 더 이상 개인을 알아볼 수 없는 정보
추가정보
개인정보의 전부 또는 일부를 대체하는 데 이용된 수단이나 방식(알고리즘 등),가명정보와의 비교ㆍ대조 등을 통해 삭제 또는 대체된 개인정보 부분을 복원할 수 있는 정보
개인정보 비식별
개인정보 개념과 활용 범위
안전하게 지키는 것만 생각하면 고려할 필요 없지만, 제공을 하는 관점에서 보면 개인정보를 기준에 맞게 구분해야 한다.

가명처리 절차
- 1단계 사전 준비: 목적의 적합성 확인 및 사전계획 수립
- 2단계 가명처리: 가명처리 수준정의 및 기술적 처리
- 3단계 적정성 검토: 검토 후 추가 가명처리가 필요한 경우 이전 단계로 회귀
- 4단계 활용 및 사후관리

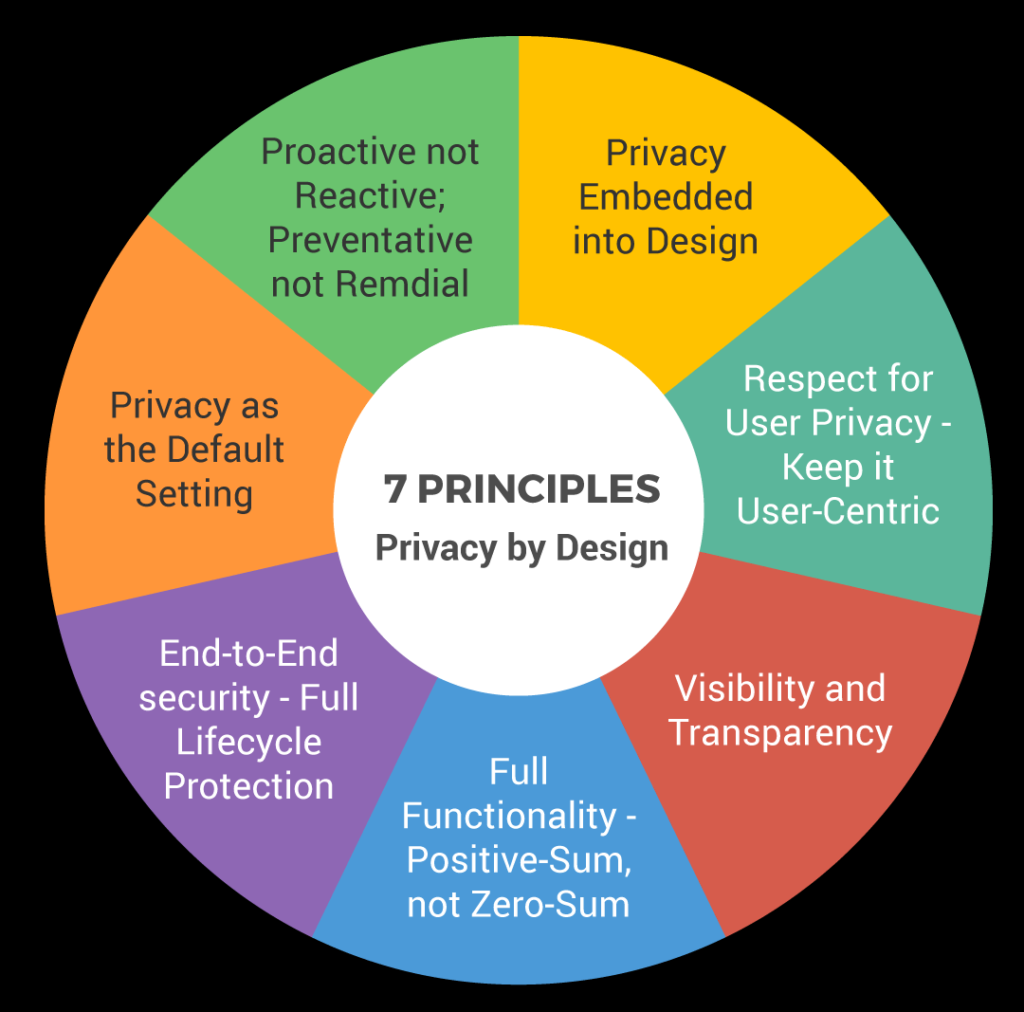
Privacy by Design
- 프라이버시를 고려한 설계
- 프라이버시 관련 침해가 발생한 이후에 조치를 취하는 것이 아닌 프라이버시 위협을 예측· 예상하거나 가능성을 대비하여 서비스 기획·설계 단계 등 사전에 예방하는 개념
비식별 조치 기준
비식별 조치란 개인 식별 요소를 일부 삭제하거나 대체하는 것을 의미한다.
-
식별자 조치 기준
정보 집합물에 포함된 식별자는 원칙적으로 삭제한다. 단, 데이터 이용 목적상 반드시 필요한 식별자는 비식별 조치 이후 활용한다. -
속성자 조치 기준
정보 집합물에 포함된 속성자도 데이터 이용 목적과 관련이 없다면 원칙적으로 삭제한다. 데이터 이용 목적의 속성자 중 식별 요소가 있는 경우에는 가명처리, 총계처리 등의 기법을 활용하여 비식별 조치한다.
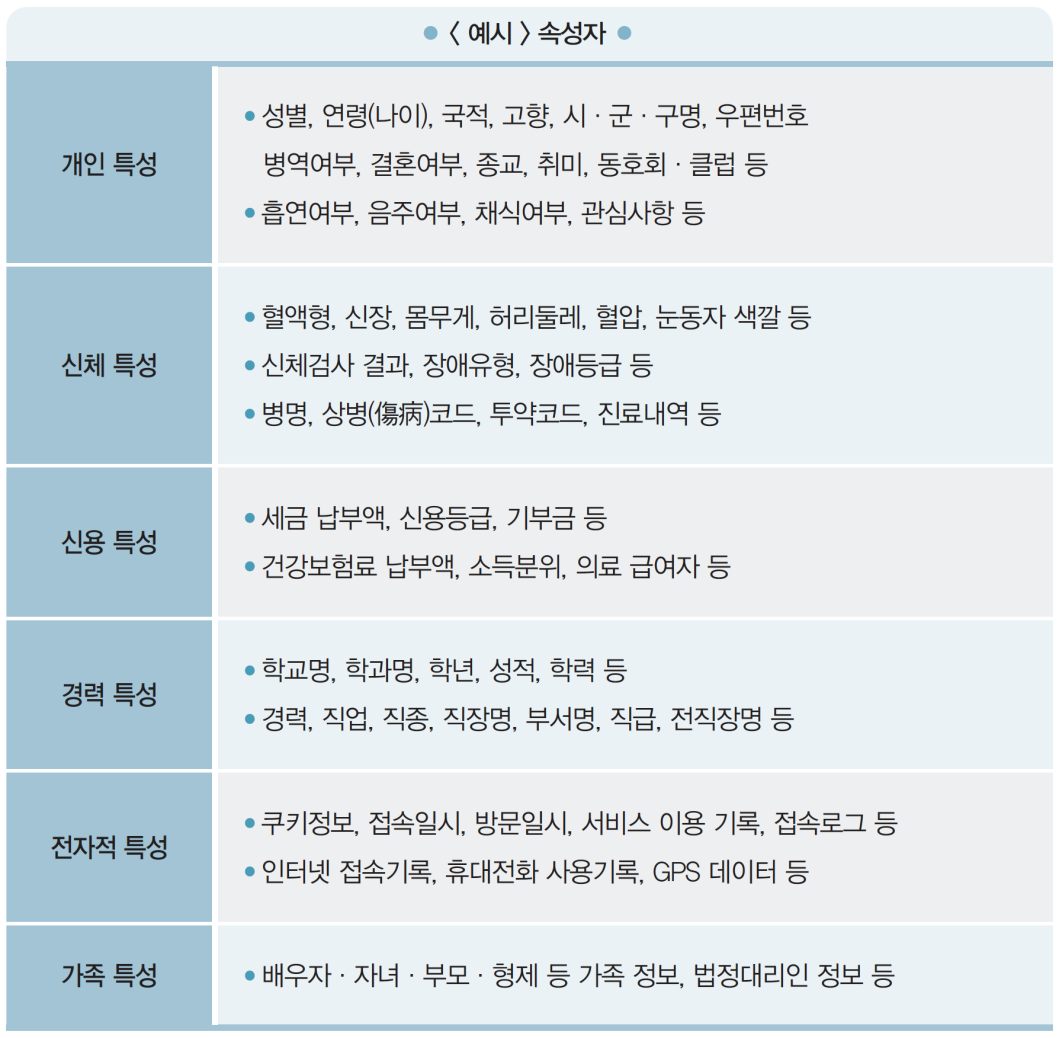
식별자 예시
• 고유식별정보(주민등록번호, 여권번호, 외국인등록번호, 운전면허번호)
• 성명(한자·영문 성명, 필명 등 포함)
• 상세 주소(구 단위 미만까지 포함된 주소)
• 날짜정보 : 생일(양/음력), 기념일(결혼, 돌, 환갑 등), 자격증 취득일 등
• 전화번호(휴대전화번호, 집전화, 회사전화, 팩스번호)
• 의료기록번호, 건강보험번호, 복지 수급자 번호
• 통장계좌번호, 신용카드번호
• 각종 자격증 및 면허 번호
• 자동차 번호, 각종 기기의 등록번호 & 일련번호
• 사진(정지사진, 동영상, CCTV 영상 등)
• 신체 식별정보(지문, 음성, 홍채 등)
• 이메일 주소, IP 주소, Mac 주소, 홈페이지 URL 등
• 식별코드(아이디, 사원번호, 고객번호 등)
• 기타 유일 식별번호 : 군번, 개인사업자의 사업자 등록번호 등속성자 예시
비식별 조치 방법
- 가명, 익명 처리 기술
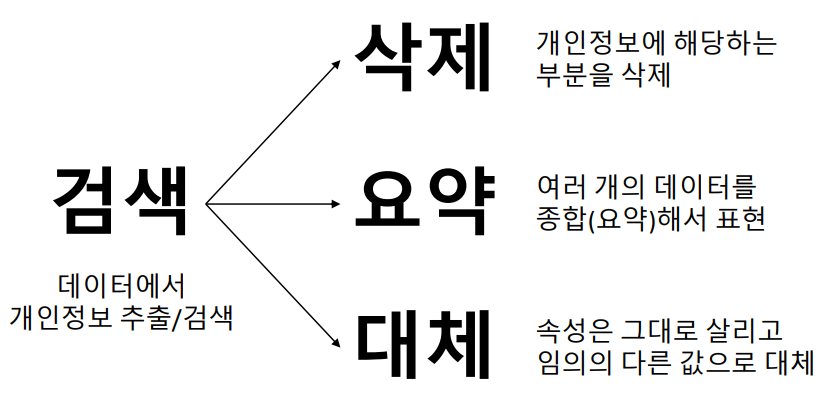
가명, 익명 처리 기술은 크게 세 가지로 분류할 수 있다. 첫 번째는 개인정보에 해당하는 부분을 삭제하는 삭제, 두 번째는 여러 개의 데이터를 종합해서 표현하는 요약, 마지막 세 번째는 속성은 그대로 살리고 임의의 다른 값으로 대체하는 대체가 있다.
삭제
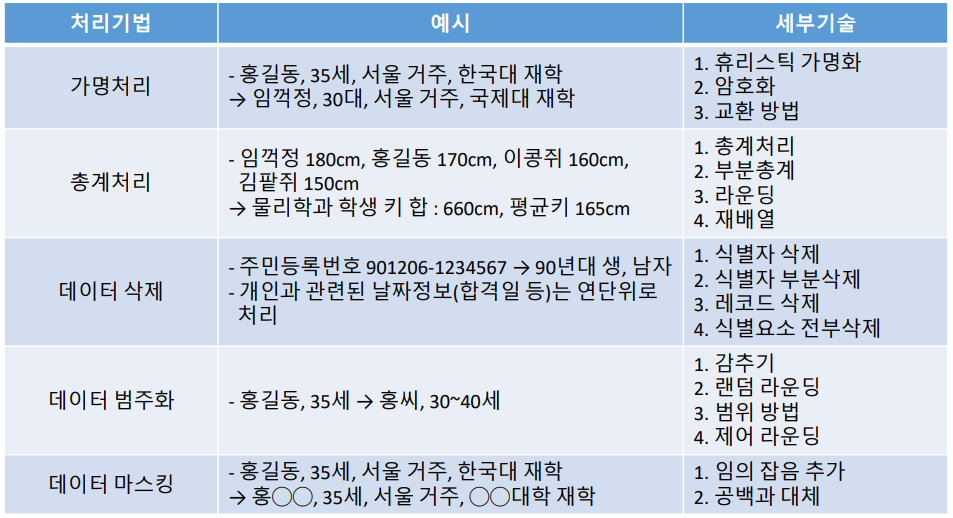
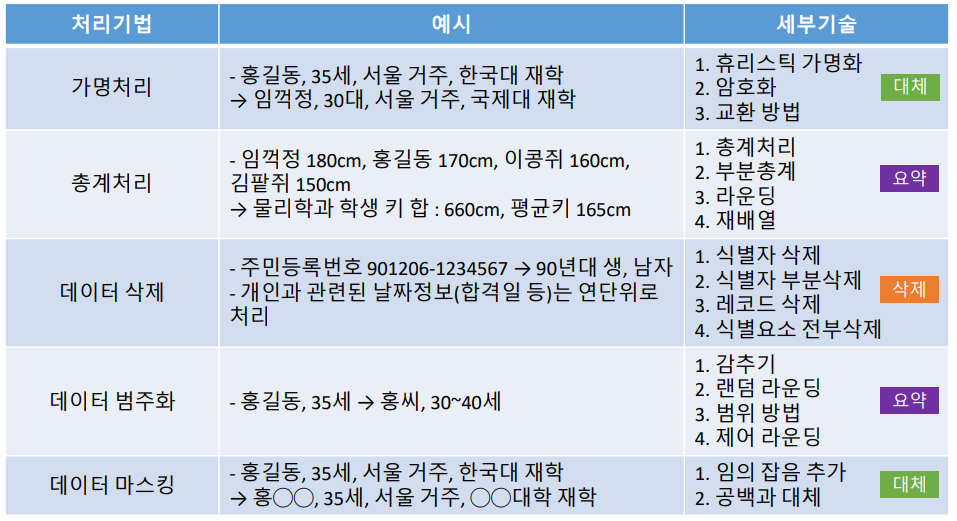
개인정보 삭제는 개인 식별이 가능한 데이터를 삭제 처리 하는 것이다. 보통 삭제 대상은 식별자라고 하는, 하나의 정보만 있어도 개인을 특정할 수 있는 정보들이다. 삭제 기법의 장점은 개인을 식별할 수 있는 요소 자체를 삭제해버린다는 것이고, 단점은 분석의 다양성과 분석 결과의 유효성 및 신뢰성을 저하시키는 것이다. 삭제 기술에는 식별자 삭제, 식별자 부분삭제, 레코드 삭제, 식별요소 전부삭제 등이 있다.
- 식별자 삭제: 원본 데이터에서 식별자를 단순 삭제하는 방법이다.
- 식별자 삭제 예시
- 식별자 부분 삭제: 식별자 전체를 삭제하는 것이 아니라, 해당 식별자의 일부를 삭제
- 식별자 부분 삭제 예시: (서울특별시 송파구 가락본동 78번지 → 서울시 송파구)
- 레코드 삭제: 다른 정보와 뚜렷하게 구별되는 레코드 전체를 삭제하는 방법
- 레코드 삭제 예시 - 행 삭제
- 레코드 삭제 예시 - 로컬 삭제
- 마스킹 예시
- 식별요소 전부 삭제: 식별자뿐만 아니라 잠재적으로 개인을 식별할 수 있는 속성자까지 전부 삭제하여 프라이버시 침해 위험을 줄이는 방법
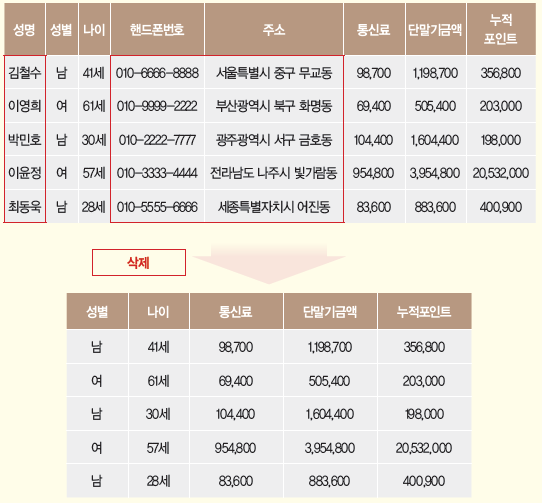
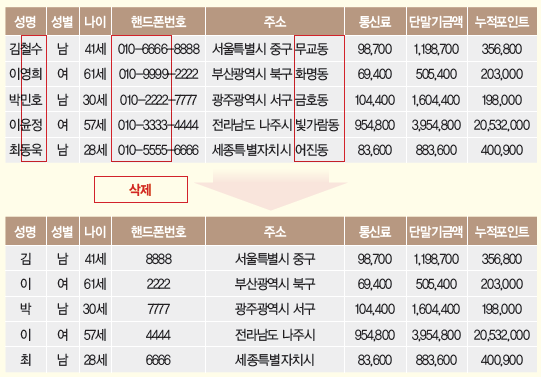
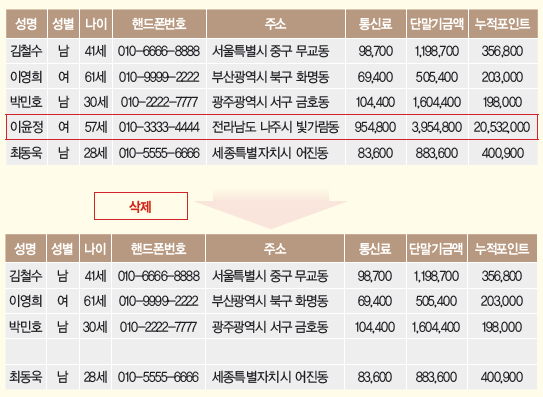
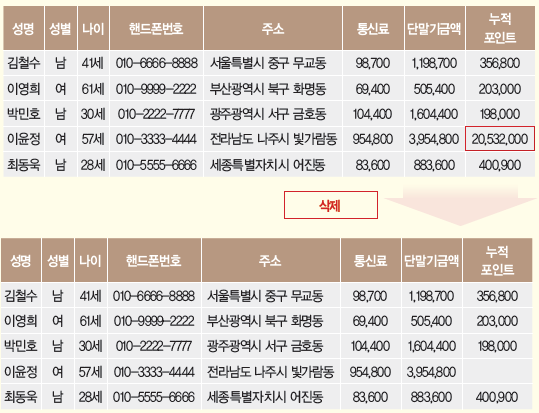

요약
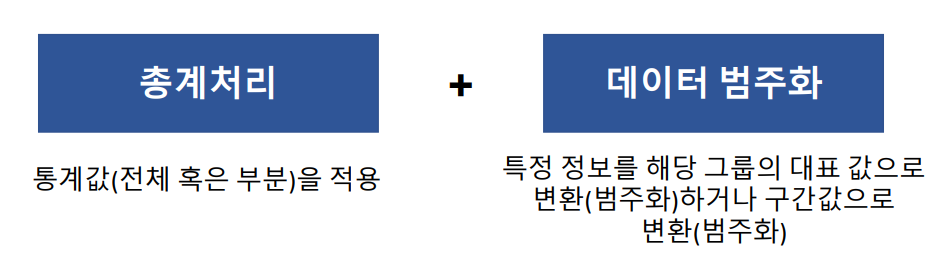
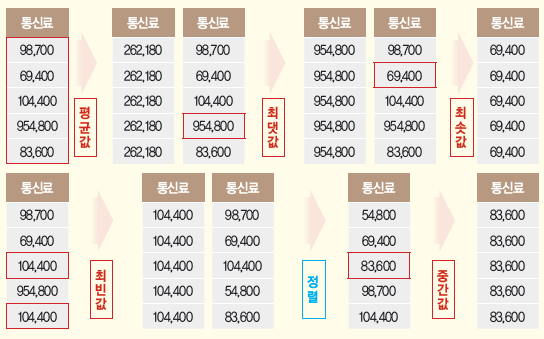
- 총계처리: 데이터 전체 또는 부분을 집계(총합, 평균 등) 단, 데이터 전체가 유사한 특징을 가진 개인으로 구성되어 있을 경우 그 데이터의 대푯값이 특정 개인의 정보를 그대로 노출시킬 수도 있으므로 주의
- 총계처리 예시
- 부분총계: 데이터 셋 내 일정부분 레코드만 총계 처리함. 즉, 다른 데이터 값에 비하여 오차 범위가 큰 항목을 통계값(평균 등)으로 변환
- 부분총계 예시
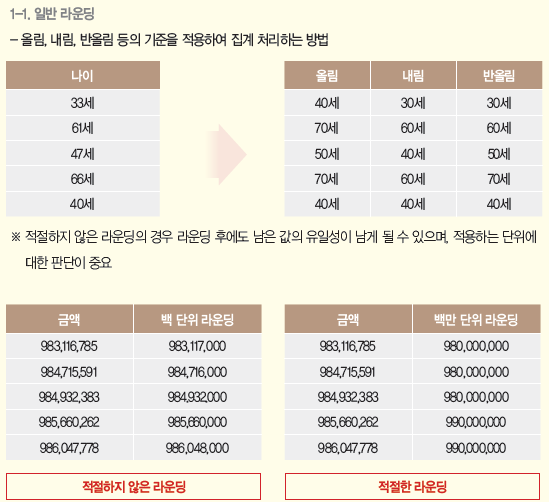
- 라운딩: 집계 처리된 값에 대하여 라운딩(올림, 내림, 사사오입) 기준을 적용하여 최종 집계 처리하는 방법으로, 일반적으로 세세한 정보보다는 전체 통계정보가 필요한 경우 많이 사용
- 라운딩 예시 - 일반 라운딩
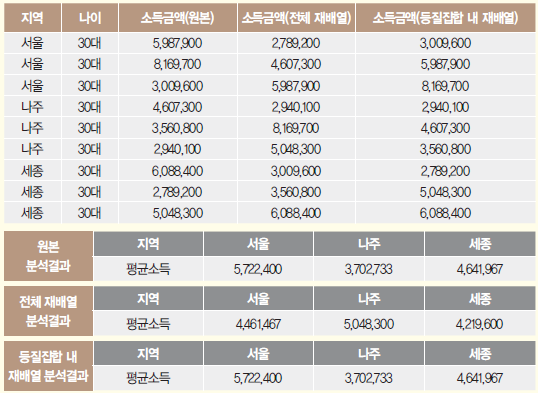
- 재배열: 기존 정보값은 유지하면서 개인이 식별되지 않도록 데이터를 재배열하는 방법으로, 개인의 정보를 타인의 정 보와 뒤섞어서 전체 정보에 대한 손상 없이 특정 정보가 해당 개인과 연결되지 않도록 하는 방법
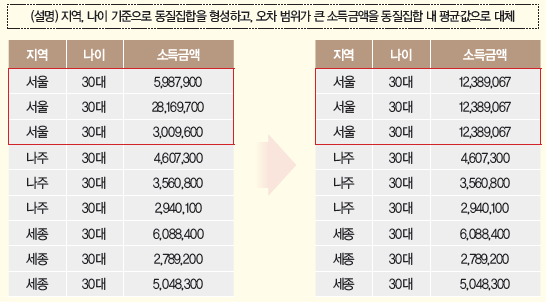
- 데이터 범주화: 특정 정보를 해당 그룹의 대푯값으로 변환(범주화)하거나 구간 값으로 변환(범주화)하여 개인 식별을 방지
- 감추기: 명확한 값을 숨기기 위하여 데이터의 평균 또는 범주값으로 변환. 단, 특수한 성질을 지닌 개인으로 구성된 단체 데이터의 평균이나 범주값은 그 집단에 속한 개인의 정보를 쉽게 추론할 수 있음
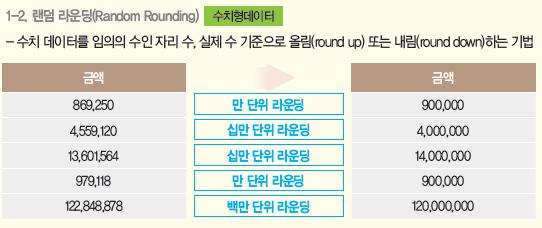
- 랜덤 라운딩: 수치 데이터를 임의의 수 기준으로 올림(round up) 또는 내림(round down)하는 기법
- 랜덤 라운딩 예시
- 범위 방법: 수치데이터를 임의의 수 기준의 범위(range)로 설정하는 기법으로, 해당 값의 범위(range) 또는 구간(interval)으로 표현
- 범위 방법 예시: 소득 3,300만원을 소득 3,000만원∼4,000만원으로 대체 표기
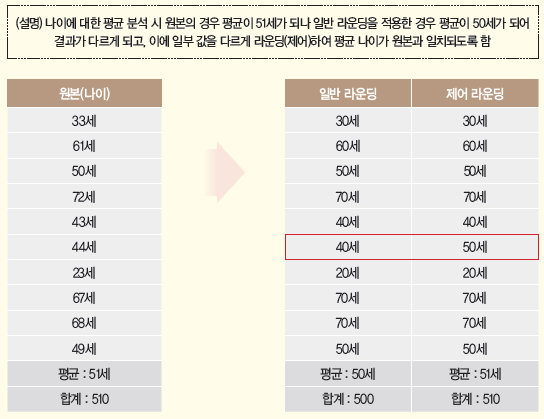
- 제어 라운딩: ‘랜덤 라운딩’ 방법에서 어떠한 특정값을 변경할 경우 행과 열의 합이 일치하지 않는 단점 해결을 위해 행과 열이 맞지 않는 것을 제어하여 일치시키는 기법, 하지만 컴퓨터 프로그램으로 구현하기 어렵고 복잡한 통계표에는 적용하기 어려우며, 해결할 수 있는 방법이 존재하지 않을 수 있어 아직 현장에서는 잘 사용하지 않음
- 제어 라운딩 예시
대체
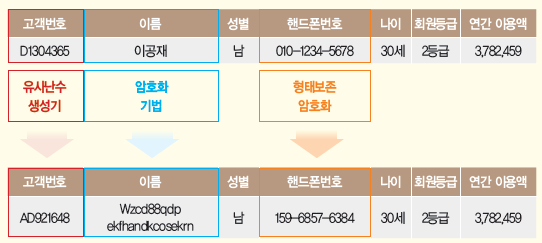
- 가명처리: 개인 식별이 가능한 데이터를 직접적으로 식별할 수 없는 다른 값으로 대체하는 기법
- 휴리스틱 가명화: • 식별자에 해당하는 값들을 몇 가지 정해진 규칙으로 대체하거나 사람의 판단에 따라 가공하여 자세한 개인정보를 숨기는 방법
- 휴리스틱 가명화 예시: 성명을 홍길동, 임꺽정 등 몇몇 일반화된 이름으로 대체하여 표기하거나 소속기관명을 화성, 금성 등으로 대체하는 등 사전에 규칙을 정하여 수행
- 암호화: 정보 가공시 일정한 규칙의 알고리즘을 적용하여 암호화함으로써 개인정보를 대체하는 방법, 통상적으로 다시 복호가 가능하도록 복호화 키(key)를 가지고 있어서 이에 대한 보안방안도 필요(키 관리/분배 문제)
- 양방향 암호화: 대칭키, 공개키 암호화
- 일방향 암호화: 암호학적 해시함수
- 무작위화 기술: 속성의 값을 원래의 값과 다르게 변경
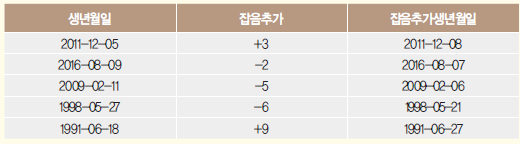
- 잡음 추가
- 순열(치환): 기존 값은 유지하면서 개인이 식별되지 않도록 데이터를 재배열하는 방법
- 토큰화: 개인을 식별할 수 있는 정보를 토큰으로 변환 후 대체함으로써 개인정보를 직접 사용하여 발생하는 개인에 대한 식별 위험을 제거하여 개인정보를 보호하는 기술