챌린지 개요
개인정보 비식별 자동화 기술 개발
1차 : 개인정보 비식별 기술을 적용하여 가명/익명처리를 수행하라!
2차 : 제공된 데이터셋을 분석하여 도전주제에 맞춘 비전기술을 개발하라!
7주차에 진행된 챌린지는 1차 미니 챌린지로, 개인정보 비식별 기술을 적용하여 가명/익명처리를 수행하는 것이다.
챌린지 운영
챌린지 배경
- 국내 대표 OTT 회사인 W사는 서비스를 이용하는 고객들의 만족도 개선을 위해 구독자 추천 서비스 개발을 전문업체에 의뢰하고자 합니다.
- 고객들의 영화 상영 및 만족도 정보를 포함하고 있는 데이터를 해당 업체에 제공하려 하는데, 개인정보 전문가에 의뢰한 결과 데이터 내 개인정보가 포함되어 가명/익명 처리가 필요한 상황입니다.
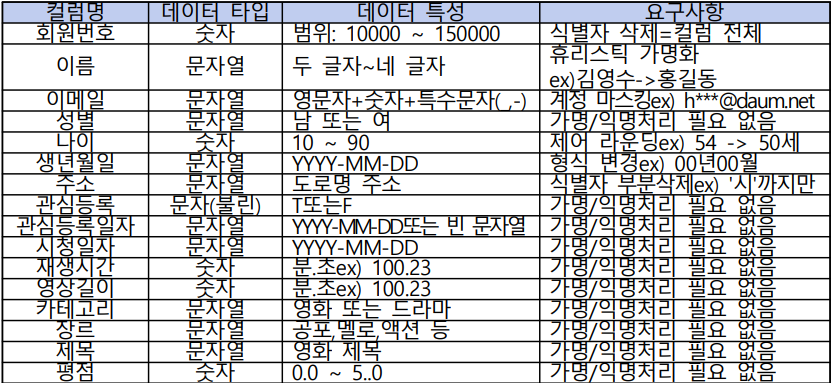
- 컬럼별 가명/익명 처리 요구사항을 확인한 후, 적절한 기술을 적용해 요구된 모든 컬럼에 대한 가명/익명 처리를 수행해 주시기 바랍니다.
데이터셋
- data.csv: 비식별 처리해야 하는 데이터 (실제 개인정보가 아닌, 무작위로 만든 개인정보이다.)
챌린지 진행
데이터 모양 확인
데이터의 인코딩 형식이 utf-8이 아닌 cp949형식이기 때문에, pandas로 데이터를 불러올 때, 인코딩 인자를 따로 주어야 한다.
import pandas as pd
data = pd.read_csv('data.csv', encoding='cp949')
data.head()| 회원번호 | 이름 | 이메일 | 성별 | 나이 | 생년월일 | 주소 | 관심등록 | 관심등록일자 | 시청일자 | 재생시간 | 영상길이 | 카테고리 | 장르 | 제목 | 평점 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 141111 | 김준혁 | 746u3@naver.com | 남 | 87 | 1935-03-06 | 충청북도 평창군 잠실거리 | T | 2018-09-22 | 2020-06-28 | 81.68 | 143.83 | 드라마 | 멜로/로맨스,드라마 | 수상한 종업원 | 5.0 |
| 1 | 122892 | 오은지 | l97ds8q5@daum.net | 여 | 70 | 1952-04-26 | 강원도 보령시 양재천935로 | T | 2018-10-11 | 2018-03-26 | 27.47 | 119.76 | 영화 | 코미디,드라마 | 굿모닝 프레지던트 | 1.2 |
| 2 | 141446 | 박성호 | iacfej@hotmail.com | 남 | 76 | 1946-07-15 | 충청북도 여주시 도산대080가 | T | 2017-08-30 | 2018-09-28 | 131.28 | 169.09 | 영화 | 미스터리,스릴러 | 비정한 도시 (미개봉) | 3.5 |
| 3 | 146551 | 박경수 | e2jfwg5lnnixop@gmail.com | 남 | 85 | 1937-01-14 | 전라북도 연천군 강남대길 | T | 2020-12-01 | 2020-03-11 | 167.79 | 168.47 | 드라마 | 범죄,액션 | 한길수 | 1.2 |
| 4 | 120589 | 김영식 | mq7vkyiyti@gmail.com | 남 | 69 | 1953-08-21 | 울산광역시 강북구 도산대3로 | T | 2020-02-04 | 2020-05-31 | 8.44 | 164.50 | 드라마 | 드라마 | 해무(海霧) | 2.5 |
요구사항에 따라 데이터 비식별 전략 세우기
- 회원번호: 컬럼 전체 삭제 - 삭제
- 이름: 휴리스틱 가명화 - 대체
- 이메일: 마스킹 - 삭제 and 대체
- 나이: 라운딩 - 요약
- 생년월일: 범주화 - 요약
- 주소: 범주화 - 요약
각각의 모듈 생성
- 대체 모듈
import math
import random
class Replacing:
def replacing_birthdate(self, data):
# 1996-01-01 -> 1990년 01월
year = math.floor(int(data.split('-')[0]) / 10) * 10
month = data.split('-')[1]
return str(year) + '년 ' + month + '월'
def heuristic_pseudonymization_name(self, data):
# 성별이 '남'이면 다음 중 하나로 변경
# 홍길동, 임꺽정, 장길산, 이몽룡, 한석봉
# 성별이 '여'이면 다음 중 하나로 변경
# 성춘향, 황진이, 장희빈, 신사임당, 허난설헌
male_names = ['홍길동', '임꺽정', '장길산', '이몽룡', '한석봉']
female_names = ['성춘향', '황진이', '장희빈', '신사임당', '허난설헌']
# 0~4 사이의 랜덤 정수 생성
random_index = random.randint(0, 4)
if data == '남':
return male_names[random_index]
else:
return female_names[random_index]생년월일을 연도와 월까지 표시하는 것으로 요약하였다. 범주는 대체에 들어가는데, 챌린지 당시 대체 모듈에 넣었었다...(이유는 잘 모르겠다.)
이름 정보를 휴리스틱 가명화 진행하였다. 남성과 여성을 구분해서 잘 알려진 이름들 5개중 랜덤으로 배정하였다. 처음에는 Faker모듈을 이용해 랜덤으로 변환했었다가, 휴리스틱 가명화가 아닌 것 같아서 다시 구현하였다. (본 코드에 주석처리 되어있다.)
- 범주화 모듈
class Categorization:
# 주소 범주화 (시/도 + 시/군/구)
def categorization_address(self, data):
return data.split(' ')[0] + ' ' + data.split(' ')[1]'충청북도 여주시 도산대080가 → 충청북도 여주시'의 형태로 범주화하였다.
- 마스킹 모듈
class Masking:
def masking_email(self, data):
id = data.split('@')[0]
# id의 첫 번째 문자를 제외한 나머지 문자를 '*'로 치환
id = id[0] + '*' * (len(id) - 1)
# id와 도메인을 '@'로 연결
return id + '@' + data.split('@')[1]이메일의 계정부분 첫 글자만 제외하고 *로 마스킹처리 하였다.
- 라운딩 모듈
import math
class Rounding:
def rounding_age(self, data):
# round down and concatenate string
data = int(math.floor(int(data) / 10.0)) * 10
data = str(data) + '세'
return data나이를 라운딩한 후 뒤에 '세'를 붙여 범주화하였다.
메인 코드
import pandas as pd
from privacy.masking import Masking
from privacy.replacing import Replacing
from privacy.rounding import Rounding
from privacy.categorization import Categorization
from faker import Faker
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
masking = Masking()
replacing = Replacing()
rounding = Rounding()
categorization = Categorization()
faker = Faker("ko_KR")
data = pd.read_csv('data.csv', encoding='cp949')
# 회원번호 삭제
data.drop('회원번호', axis=1, inplace=True)
# 이름 무작위 변경
# for i in tqdm(range(len(data))):
# original_name = data['이름'][i]
# if data['성별'][i] == '남':
# data['이름'][i] = faker.name_male()
# else:
# data['이름'][i] = faker.name_female()
# 이름 휴리스틱 가명화
data['이름'] = data['성별'].apply(replacing.heuristic_pseudonymization_name)
# 이메일 마스킹 (abcdefg@naver.com → ****@naver.com)
data['이메일'] = data['이메일'].apply(masking.masking_email)
# 나이 제어 라운딩 (나이 15 → 10대)
data['나이'] = data['나이'].apply(rounding.rounding_age)
# 생년월일 형식 변경 (yyyy-mm-dd → yyy0년 mm월)
data['생년월일'] = data['생년월일'].apply(replacing.replacing_birthdate)
# 주소 범주화 (충청북도 여주시 도산대080가 → 충청북도 여주시)
data['주소'] = data['주소'].apply(categorization.categorization_address)
# 결과 확인
print(data.head(10))
# 결과 저장
data.to_csv('[KDT_AISEC_1기] 개인정보 비식별 1차 미니 챌린지_[이름]_v0.1_cp949.csv', encoding='cp949', index=False)
data.to_csv('[KDT_AISEC_1기] 개인정보 비식별 1차 미니 챌린지_[이름]_v0.1_utf-8-sig.csv', encoding='utf-8-sig', index=False)
비식별 처리 이후 결과물의 일부이다.

𝙋𝙤𝙨𝙨𝙤 𝙁𝙖𝙧𝙚!