
JPA란 무엇일까?
기존의 DB를 직접 다루었을 때
만약 이러한 객체 데이터를 DB에 저장해서 관리해야한다면 어떻게 해야할까?
public class Memo {
private Long id;
private String username;
private String contents;
}해당 객체 데이터를 DB에 저장하고 관리하기 위해서는 해야 할 작업들이 있다.
1. DB 테이블 만들기
create table memo(
id bigint not null auto_increment,
contents varchar(500) not null,
username varchar(255) not null,
primary key (id)
)id 값을 PK로 지정하고, 값이 들어갈 때마다 자동으로 증가하게 설정하고 DB에 대한 테이블을 만들어야한다.
이렇게 직접 DB로 접속하여 SQL을 호출해야한다.
2. 애플리케이션에서 SQL을 작성하기
String sql = "INSERT INTO memo (username, contents) VALUES (?,?)";
String sql = "SELECT * FROM memo";프로그래머가 직접 SQL에 대한 문자열을 만들어야한다.
3. SQL을 JDBC를 사용해서 직접 실행하기
jdbcTemplate.update(sql, "내용1", "내용2");
jdbcTemplate.query(sql, ...);프로그래머가 직접 작성한 SQL 쿼리문을 JDBC를 사용하여 실행해줘야한다.
4. SQL 결과를 객체로 직접 만들어주기
@Override
public MemoResponseDto mapRow(ResultSet rs, int rowNum) throws SQLException {
// SQL의 결과를 rs에 받아와서 MemoResponseDto 객체를 생성해서 반환하기
Long id = rs.getLong("id");
String username = rs.getString("username");
String contents = rs.getString("contents");
return new MemoResponseDto(id,username,contents);
}프로그래머가 직접 DB에 보낸 결과에 대해 객체를 생성해서 반환해줘야한다.
이러한 번거로운 작업들을 직접 DB를 다루었을 때 해야한다.
그렇다면 만약, 객체 데이터에 필드값이 추가될 경우? -> password라는 데이터가 추가된다면?
우리는 해당 클래스에 필드값을 추가해야하며, SQL 작성을 다시 해줘야하고, 결과값 또한 수정을 해줘야한다.
직접 DB를 다루었을 경우, SQL에 너무 의존적이라 변경해야하는 것들이 많이 발생한다.
이러한 반복적이고 번거로운 작업을 줄이기 위한 ORM (객체 관계 매핑) 기술이 등장한다.
ORM (Object-Relational Mapping)
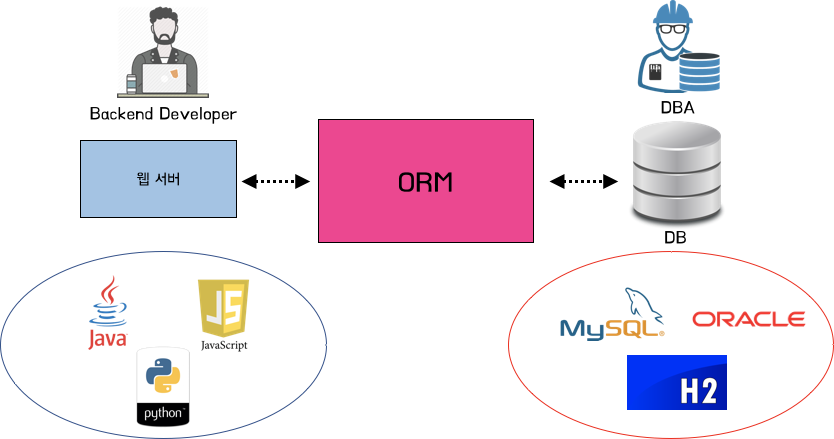
Object : "객체" 지향 언어, Relational : "관계형" 데이터베이스
-
이름 그대로 객체 클래스와 DB와의 관계를 매핑해준다.
-
객체는 객체대로 설계하고, 관계형 데이터베이스는 관계형 데이터베이스대로 설계한다.
-
즉, 프로그래머가 직접 데이터를 다루지 않는다.
-
이러한 ORM 의 대표적인 예시가 JPA이다.
JPA (Java Persistence API)
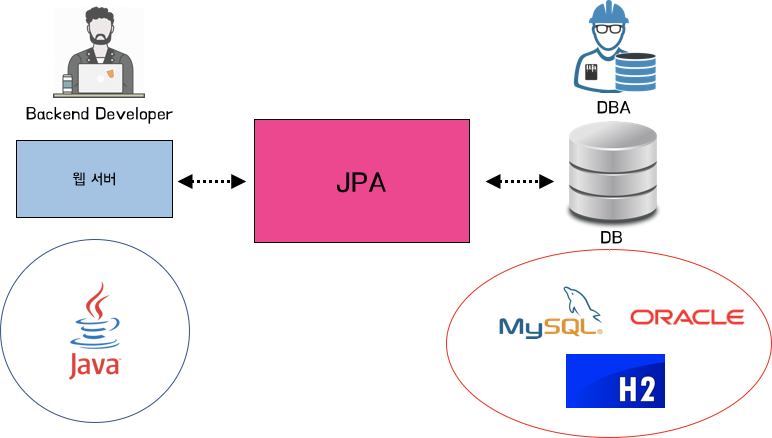
자바 ORM 기술에 대한 대표적인 표준 명세
따라서 JPA 자체는 인터페이스 라서 구현체를 통해 구현을 해야한다.
이러한 구현체의 대표적인 것이 바로 Hibernate(하이버네이트) 이다.
스프링 부트에서는 하이버네이트 구현체를 사용하고 있다.
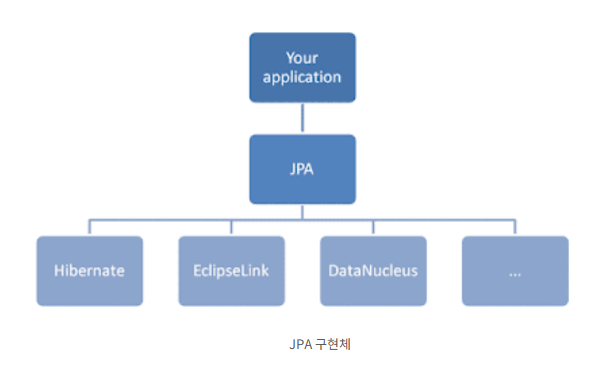
그 외에도 다른 구현체들이 있긴 하다.
JPA 동작 과정
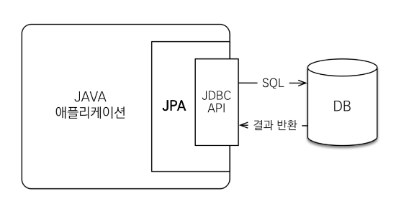
-
JPA는 애플리케이션과 JDBC 사이에서 동작을 하게 된다.
-
개발자가 JPA를 사용하면, JPA 내부에서 JDBC API를 사용해서 SQL을 호출하고 DB와 통신을 한다.
-
즉, 개발자가 직접 JDBC API를 쓰는 것이 아니다.
-
-
JPA를 사용하면 DB 연결 과정을 직접 개발하지 않아도 자동으로 처리해준다.
-
객체(자바의 클래스)를 통해 간접적으로 DB 데이터를 다룰 수 있기 때문에 쉽게 DB 작업을 처리할 수 있다.
예시)
1. 저장 과정
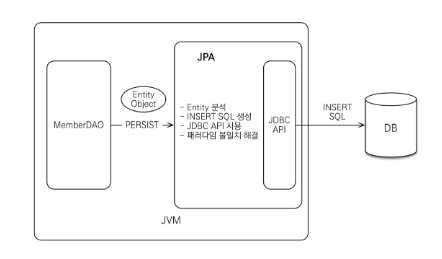
만약 객체를 저장하고 싶다면?
개발자는 JPA에게 해당 객체만 넘기면 된다.
그렇게 하면 JPA가 하는 동작은
-
해당 객체 엔티티를 분석
-
INSERT SQL을 생성
-
JDBC API를 사용해서 SQL을 DB에 날린다.
2. 조회 과정
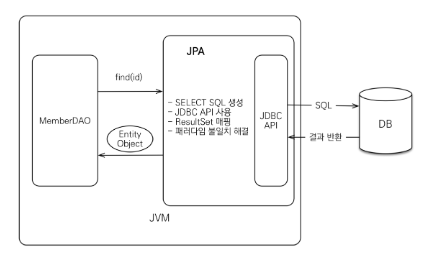
만약 객체를 조회하고 싶다면?
개발자는 해당 객체의 PK의 값을 JPA에게 넘기면 된다.
그렇게 하면 JPA가 하는 동작은
-
엔티티의 매핑 정보를 바탕으로 적절한 SELECT SQL을 생성
-
JDBC API를 사용하여 SQL을 DB에 전달
-
DB로부터 결과의 값을 받음
-
결과를 객체에 모두 매핑해준다.
JPA의 장점
-
JPA를 사용하기만 하면 직접 DB에 접근하여 사용했을 때와는 다르게 SQL 중심 문제에 대해 객체 중심적인 개발로 바뀌게 된다.
- 즉, 객체 지향적인 코드 작성이 가능하다.
-
생산성이 증가하게 된다.
-
즉, JPA 내부에서 알아서 DDL 문을 자동으로 생성해주며, 간단한 메서드를 통해 CRUD가 가능해지고 반복적인 일을 대신 처리해준다.
-
저장 : jpa.persist( )
-
조회 : jpa.find( )
-
삭제 : jpa.remove( )
-
수정 : member.setName( )
-
-
유지보수 및 리팩토링에 유리하다.
-
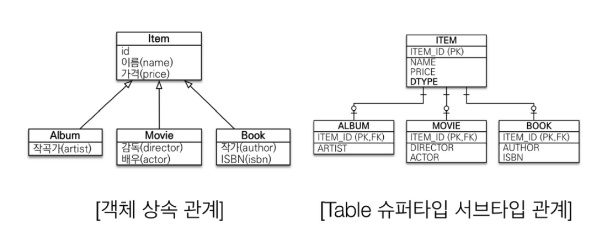
Object와 RDB간의 패러다임 불일치를 해결해준다.
- 즉, Java에 존재하는 상속관계를 객체간의 상속관계를 지원하지 않은 데이터 베이스에서 JPA는 아래와 같은 방식으로 해결해준다.
JPA의 단점
-
설계가 잘못되거나 커질 경우, 속도 저하 및 일관성 문제가 발생한다.
-
복잡하고 무거운 Query 문은 속도에 대한 별도의 튜닝이 필요하기에 JPA보단 SQL문을 직접 쓰는게 좋을 상황이 발생하게 된다.
-
학습 비용이 비싸다.
참고
