🔑Summarization
- EDA Test 1 : 서울 인구데이터 분석
📗Contents
Data
- Source: 서울시 열린데이터
- 참고사항
- 외국인 세대수 제외
- 65세이상 고령자 수 : 외국인 포함
Step 1. Load Data & Preprocessing
행 제거 및 index 초기화
- DataLoad
f_path = 'datas/report.txt'
df = pd.read_table(f_path, encoding='utf-8')- 0, 1, 2번 인덱스(index) 행(row) 제거 및 초기화
df.drop([0, 1, 2], axis = 0, inplace = True)
df = df.reset_index(drop = True)
df.head()
현재의 컬럼명(current_columns) 변경
- 현재 컬럼명 변경
df.columns = ['기간', '자치구', '세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자', '등록외국인 계', '등록외국인 남자', '등록외국인 여자', '세대당인구', '65세이상고령자']
df.tail()
천단위 구분자 " , "를 제거 및 data의 type을 int 또는 float으로 변경
- 데이터 타입 변경
for idx, name in enumerate(df.columns):
if str(name) in ['세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자', '등록외국인 계', '등록외국인 남자', '등록외국인 여자', '65세이상고령자']:
df[name] = df[name].str.replace(',', '').astype(int)
elif name == '세대당인구':
df[name] = df[name].str.replace(',', '').astype(float)
df.tail()
- 변경 전과 변경 후 데이터 타입(type) 확인
df.info() # 변경 전, 변경 후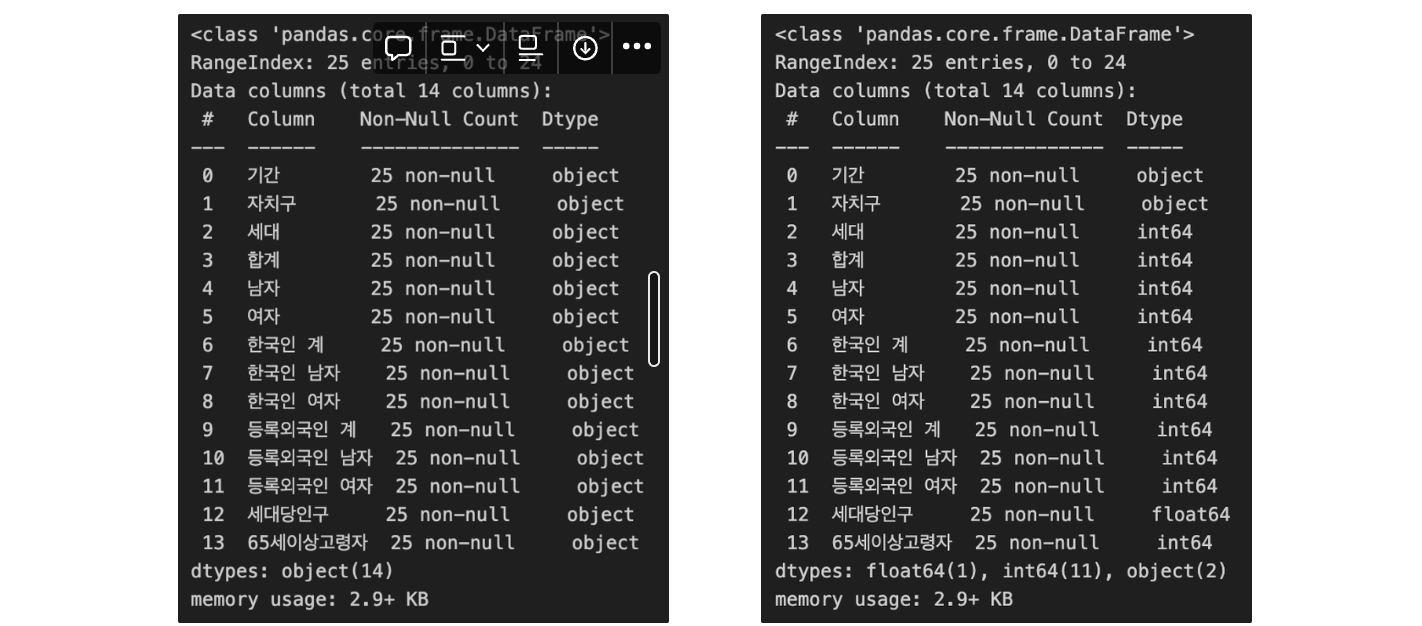
Step 2. Get Information
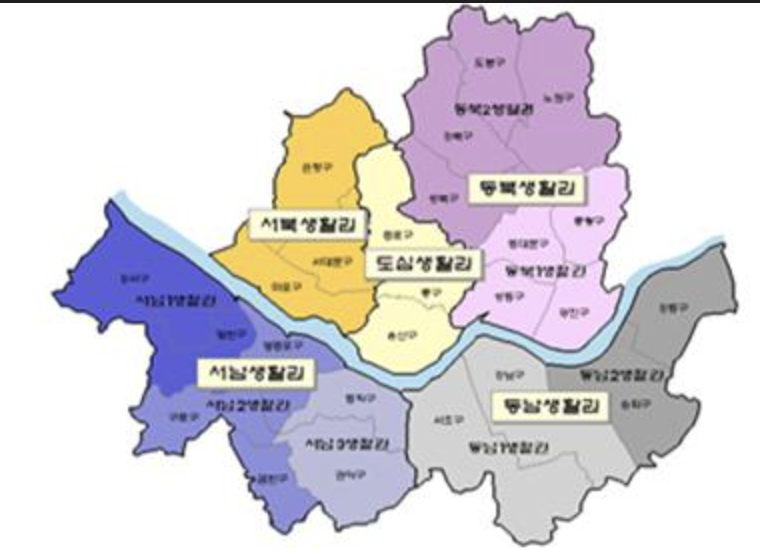
서울 권역별 분류
- 도심권: ['종로구', '중구', '용산구']
- 동북권: ['성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구', '도봉구', '노원구']
- 서북권: ['은평구', '서대문구', '마포구']
- 서남권: ['양천구', '강서구', '구로구', '금천구', '영등포구', '동작구', '관악구']
- 동남권: ['서초구', '강남구', '송파구', '강동구']
DataFrame에 '권역' column을 추가하여 해당 구에 맞는 권역을 입력
- 권역에 해당하는 구 설정
region_dict = {'도심권': ['종로구', '중구', '용산구'],
'동북권': ['성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구', '도봉구', '노원구'],
'서북권': ['은평구', '서대문구', '마포구'],
'서남권': ['양천구', '강서구', '구로구', '금천구', '영등포구', '동작구', '관악구'],
'동남권': ['서초구', '강남구', '송파구', '강동구']
}region_dict['도심권']Output : ['종로구', '중구', '용산구']
- 권역별 구 이름과 자치구에 기입되어있는 구 이름을 비교하여 해당하는 권역을
권역column에 추가
df['권역'] = np.nan
for idx, name in enumerate(df['자치구']):
if name in region_dict['도심권']:
df['권역'][idx] = '도심권'
elif name in region_dict['동북권']:
df['권역'][idx] = '동북권'
elif name in region_dict['서북권']:
df['권역'][idx] = '서북권'
elif name in region_dict['서남권']:
df['권역'][idx] = '서남권'
elif name in region_dict['동남권']:
df['권역'][idx] = '동남권'
df.tail()
DataFrame을 이용하여 Pandas의 pivot_table 메소드를 활용하여 각 권역별 아래 값의 합을 구하고, '합계'를 기준으로 내림차순 정렬
- 권역을 인덱스(Index) 설정 및 제시된 값의 합계를 구하는
np.sumoption 사용- 구할 값:
['합계', '세대', '여자', '한국인 계', '등록외국인 계', '65세이상고령자']
- 구할 값:
df_pivot = pd.pivot_table(df,
index = '권역',
values= ['합계', '세대', '여자', '한국인 계', '등록외국인 계', '65세이상고령자'],
aggfunc = np.sum
)- 내림차순 정렬
df_pivot.sort_values('합계', ascending = False, inplace = True)
df_pivot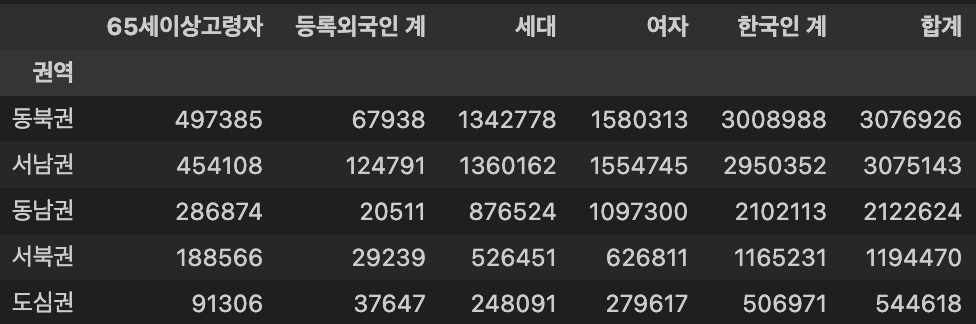
Pivot Table을 이용하여 각 권역별 컬럼을 만들어 아래와 같이 값을 입력하고 '외국인비율'을 기준으로 오름차순 정렬
입력내용
- 고령자비율: 65세이상고령자 / 합계 * 100
- 외국인비율: 등록외국인 계 / 합계 * 100
- 여성비율: 여자 / 합계 * 100
- 세대당인구: (합계 - 등록외국인 계) / 세대
- 입력내용에 해당하는 값을 각 column을 만들어 추가
df_pivot['고령자비율'] = df_pivot['65세이상고령자'] / df_pivot['합계'] * 100
df_pivot['외국인비율'] = df_pivot['등록외국인 계'] / df_pivot['합계'] * 100
df_pivot['여성비율'] = df_pivot['여자'] / df_pivot['합계'] * 100
df_pivot['세대당인구'] = (df_pivot['합계'] - df_pivot['등록외국인 계']) / df_pivot['세대']외국인비율기준 오름차순 정렬
df_pivot.sort_values('외국인비율', ascending = True, inplace = True)
df_pivot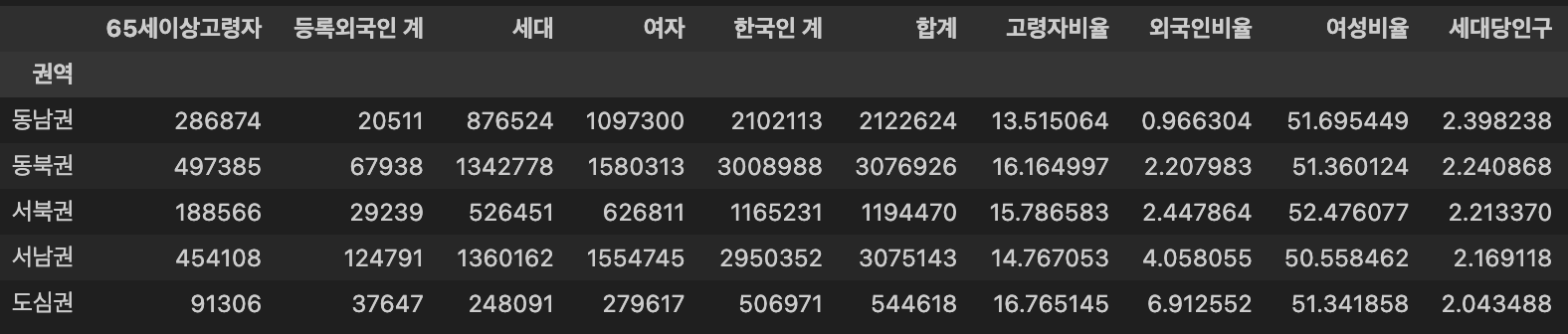
DataFrame을 이용하여 각 구별 컬럼을 만들어 아래와 같이 값을 입력하고 '세대당인구'을 기준으로 내림차순 정렬
입력내용
- 고령자비율: 65세이상고령자 / 합계 * 100
- 외국인비율: 등록외국인 계 / 합계 * 100
- 여성비율: 여자 / 합계 * 100
- 입력내용에 해당하는 값을 각 column을 만들어 추가
- 해당하는 값 : 각 구별
['고령자비율', '외국인비율', '여성비율']
- 해당하는 값 : 각 구별
df_target = df.copy()
df_target['고령자비율'] = df_target['65세이상고령자'] / df_target['합계'] * 100
df_target['외국인비율'] = df_target['등록외국인 계'] / df_target['합계'] * 100
df_target['여성비율']= df_target['여자'] / df_target['합계'] * 100세대당인구기준 내림차순 정렬
df_target.sort_values('세대당인구', ascending = False, inplace = True)
df_target.tail()
DataFrame을 이용하여 column간의 피어슨 상관계수 행렬(Correlation matrix)를 구하기
참고내용
-
상관계수(correlation coefficient): 두 변수가 함께 변하는 정도를 -1 ~ +1 범위의 수로 나타낸 것
-
피어슨 상관계수: 칼 피어슨(Karl Pearson)이 개발한 상관계수로, 일반적으로 상관계수라고 하면 피어슨 상관계수를 말함
- Standard Correlation Coefficient
- (상관계수) = 와 가 함께 변하는 정도 / 와 가 각각 변하는 정도
-
상관계수 행렬(Correlation Matrix): 변수간 상관계수를 보여주는 행렬
-
피어슨 상관계수를 구할 column 선정 및 계산
- 해당 column :
['고령자비율', '외국인비율', '여성비율', '세대당인구']
- 해당 column :
pivot_corr = df_pivot[['고령자비율', '외국인비율', '여성비율', '세대당인구']].corr(method = 'pearson')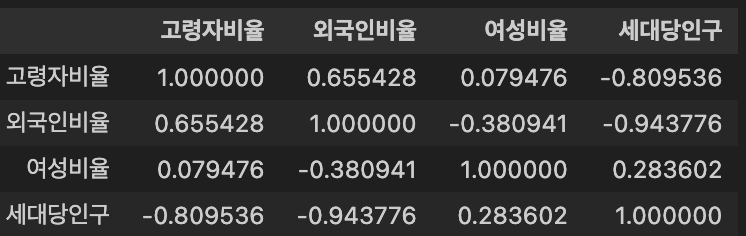
Step 3. Visualization
- ModuleLoad & Font Setting
# 한글 설정
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
get_ipython().run_line_magic("matplotlib", "inline")
# %matplotlib inline
path = "C:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
rc("font", family="Arial Unicode MS")
elif platform.system == "Windows":
font_name = font_manager.Fontproperties(fname=path).get_name()
rc("font", family=font_name)
else:
print("Unkown system. sorry~~")자치구별 고령자비율을 내림차순에 따라 barh 그래프로 시각화
# 3-1: barh
dfPlot1 = df_target.sort_values('고령자비율', ascending = False)
plt.figure(figsize = (10,6))
sns.barplot(x = dfPlot1['고령자비율'], y = dfPlot1['자치구'], orient = 'h')
plt.title('자치구별 고령자 비율', size = 15)
sns.despine(offset = 5)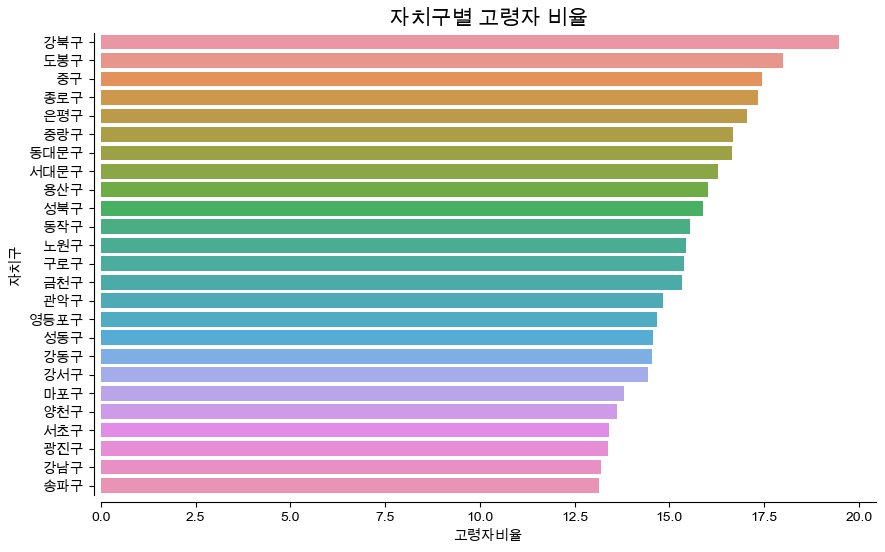
권역별 등록외국인 계를 PIE chart로 시각화
# 3-2: Pie
df_pivot
plt.figure(figsize = (6,6))
plt.pie(
df_pivot['등록외국인 계'],
labels = df_pivot.index
)
plt.legend(title = '권역')
plt.title('권역별 등록외국인 계', size = 12)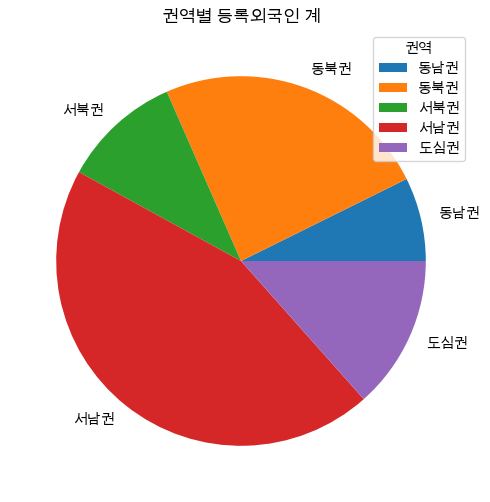
권역별 외국인비율을 Box plot으로 시각화
# 3-3: Boxplot
dfPlot2 = df_target[['외국인비율','권역']]
plt.figure(figsize = (6,6))
sns.boxplot(x = '권역', y = '외국인비율', data = dfPlot2, palette = 'Set3')
plt.title('권역별 외국인 비율', size = 12)
sns.despine(offset = 5)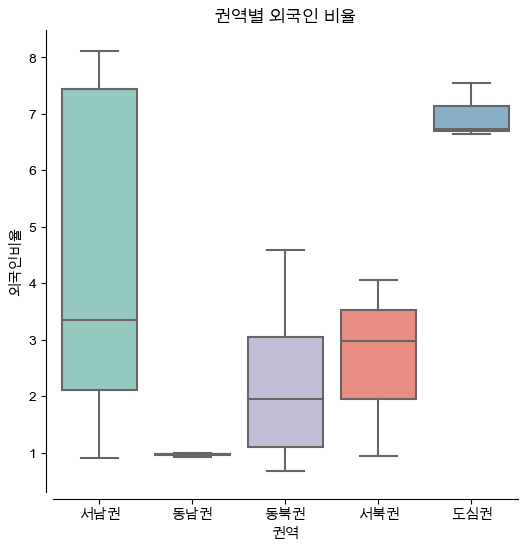
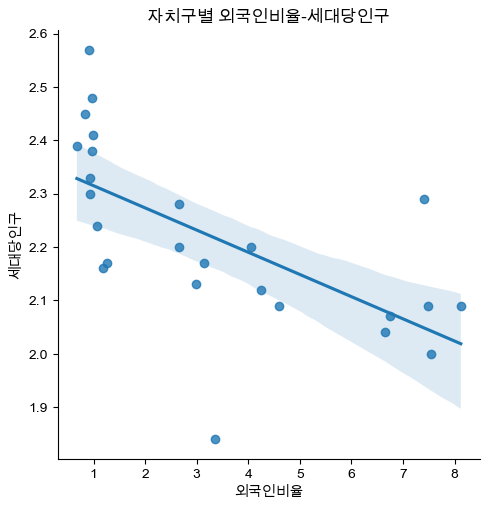
자치구별 외국인비율-세대당인구를 Scatter plot에 나타내고, 상관관계에 따른 Regression Line을 시각화
# 3-4: scatterplot + regression
plt.figure(figsize = (8, 8))
sns.lmplot(data = df_target, x = '외국인비율', y = '세대당인구')
plt.title('자치구별 외국인비율-세대당인구')