
🔑Summarization
- Package - BeautifulSoup Basic
📗Contents
BeautifulSoup Basic
- conda install -c anaconda beautifulsoup4
- pip install beautifulsoup4
- data 확인
# import
from bs4 import BeautifulSouppage = open("../data/03. zerobase.html", "r").read()
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())- HTML : 웹 페이지 표현
- Head : 문서에 필요한 헤더 정보 보관
- Body : 눈에 보이는 정보 보관

- 실제 HTML Code
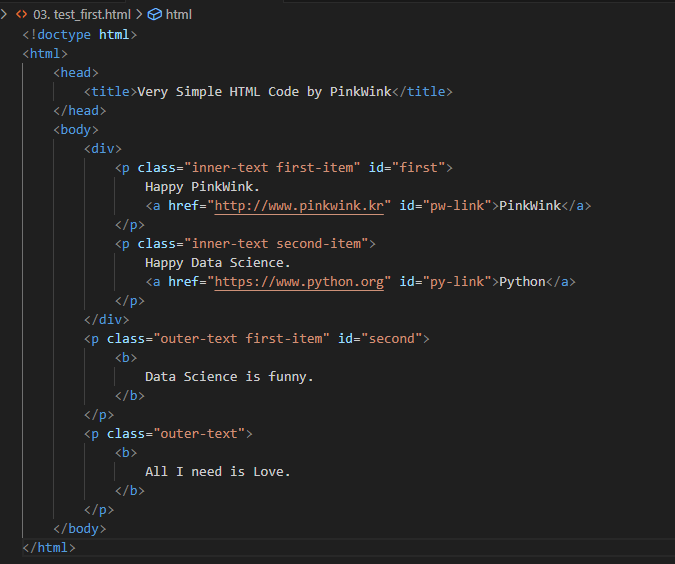
태그(Tag) 확인
- head 태그 확인
# head 태그 확인
soup.head- body 태그 확인
# body 태그 확인
soup.body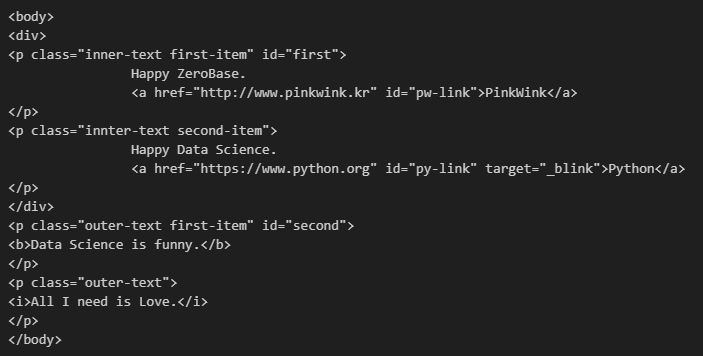
- p 태그 확인
- 처음 발견한 p 태그만 출력
- find(“p”)
# p 태그 확인
# find()
soup.p
find()
soup.find("p")
class_: class를 쓸 경우 파이썬 예약어와 겹치는 경우가 생기기 때문에 구분하기 위해 언더바(underbar, ‘_’ )를 사용
# 파이썬 예약어
# class, id, def, list, str, int, tuple...soup.find("p", class_="innter-text second-item")
soup.find("p", {"class":"outer-text first-item"}).text.strip()'Data Science is funny.’
- 다중 조건
# 다중 조건
soup.find("p", {"class":"inner-text first-item", "id":"first"})
find_all(): 여러 개의 태그(Tag)를 리스트(list) 형태로 반환
soup.find_all("p")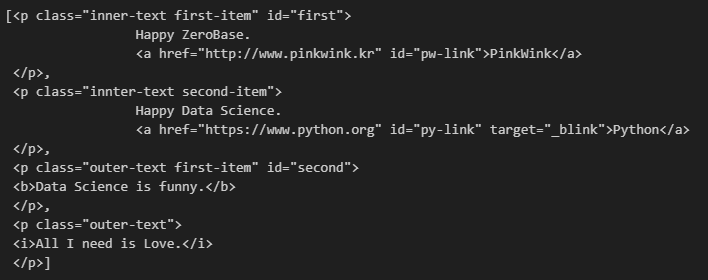
- 특정 태그(Tag) 확인
# 특정 태그 확인
soup.find_all(id="pw-link")[0].textsoup.find_all("p", class_="innter-text second-item")
- 길이
len(soup.find_all("p"))- 텍스트 속성만 출력하기
# p 태그 리스트에서 텍스트 속성만 출력
for each_tag in soup.find_all("p"):
print("=" * 50)
print(each_tag.text)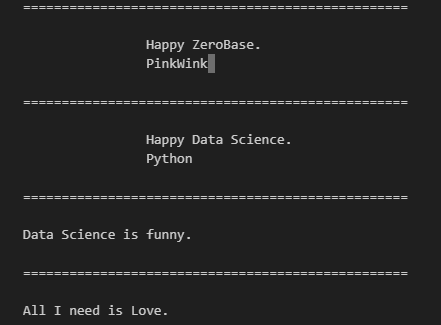
- 속성값에 있는 값(Value) 추출
# a 태그에서 href 속성값에 있는 값 추출
links = soup.find_all("a")
links[0].get("href"), links[1]["href"]('[http://www.pinkwink.kr](http://www.pinkwink.kr/)', '[https://www.python.org](https://www.python.org/)')
for each in links:
href = each.get("href") # each["href"]
text = each.get_text()
print(text + "=>" + href)PinkWink=>[http://www.pinkwink.kr](http://www.pinkwink.kr/)
Python=> [https://www.python.org](https://www.python.org/)

Start