Olympic
Data
- Target Data(CSV): 역대(1976-2008) 하계 올림픽 메달리스트에 대한 정보
- Source: [Kaggle]
- DownLoad: [archive.zip]
참고사항: 해당 데이터 분석시 한계점
-
해당 데이터는 공식 데이터와 차이가 있음.
-
대한민국 데이터 누락
- 예시: 2008년 베이징올림픽 역도 48kg 은메달 임정화 누락
-
복식/단체 종목의 경우 한 종목에서 여러명이 메달을 획득하지만, 국가 순위 집계시 1개로 집계됨
-
동일 종목인 경우 1개로 계산하는 것이 용이
-
단, 3,4위 모두에 동메달을 주는 경우 한 나라에서 동메달 2개 획득시 문제 발생
-
대한민국 사례: 1992년 바르셀로나 올림픽 실제 탁구 남성복식 2팀 준결승 진출로 및 패배로 동메달 2개 획득
-
당시 준결승 진출시 동메달 수여, 총 4명
➣ 이 자료에서는 누가 누구와 복식조를 이뤘는지 구분할 수 없으며 동일종목이므로 이 자료로 국가 순위 집계시 문제 발생
-
- 참고: 현재 올림픽 탁구 복식 4위에게는 동메달을 수여하지 않음
- 올림픽 메달 취소 등 반영 안되어있음
- 복식/단체 종목의 선수 수, 당시 메달 수여 룰, 메달 취소 및 승격/승계 등의 실제 메타데이터가 없이는 확인 어려움
이러한 이유로 해당 자료 자체만으로 Test 진행 할 예정이며, 국가별 메달 집계시 동일종목당 1개의 메달로 계산
Step 1. Load Data & Preprocessing
1-1. Target Data 가져오기
- ModuleLoad
import pandas as pd
import numpy as np-
DataLoad
encoding = utf-8로 Load 시 문제 발생
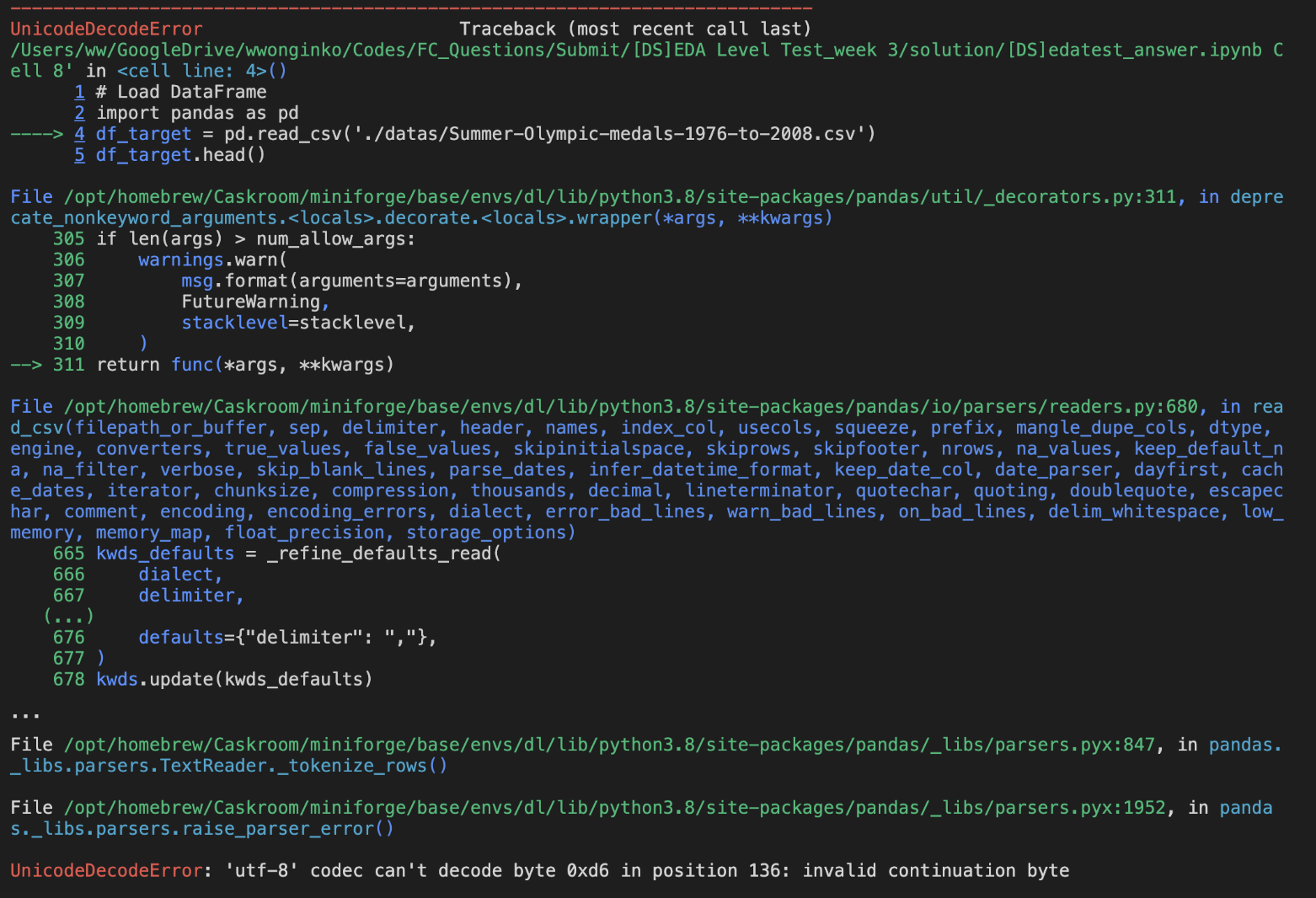
- 데이터가 영어로 이루어져 있으므로 encoding = latin-1 로 진행
df_target = pd.read_csv('datas/Summer-Olympic-medals-1976-to-2008.csv', encoding = 'latin-1')
df_target
1-2. Preprocessing: missing data 처리
- NaN값 여부 확인
- 전체 15,443개 행 중, 15,316개 행만 값이 존재
- 127개의 NaN값이 있는 행 존재
# condition 1
df_target.info() # NaN 여부 확인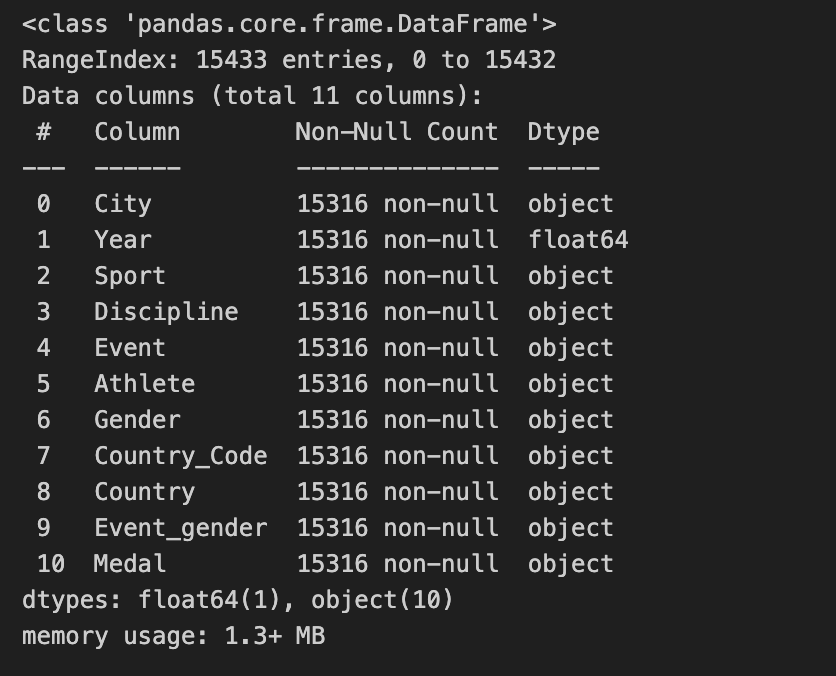
- NaN값 제거
df_target.dropna(axis = 0, inplace = True)
df_target.info()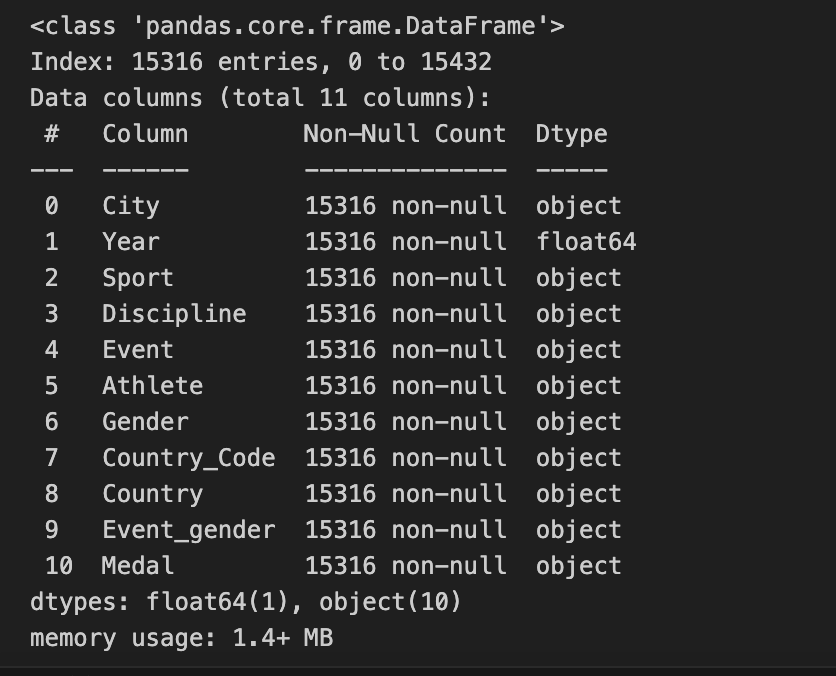
- Index reset 및 기존 Index행 삭제
# Condition 2
df_target = df_target.reset_index() # 인덱스 초기화
df_target.drop('index', axis = 1, inplace = True) # 기존 index column 삭제
df_target
1-3. Preprocessing: Data Type 정리
- 기존 데이터 정보 확인
df_target.info()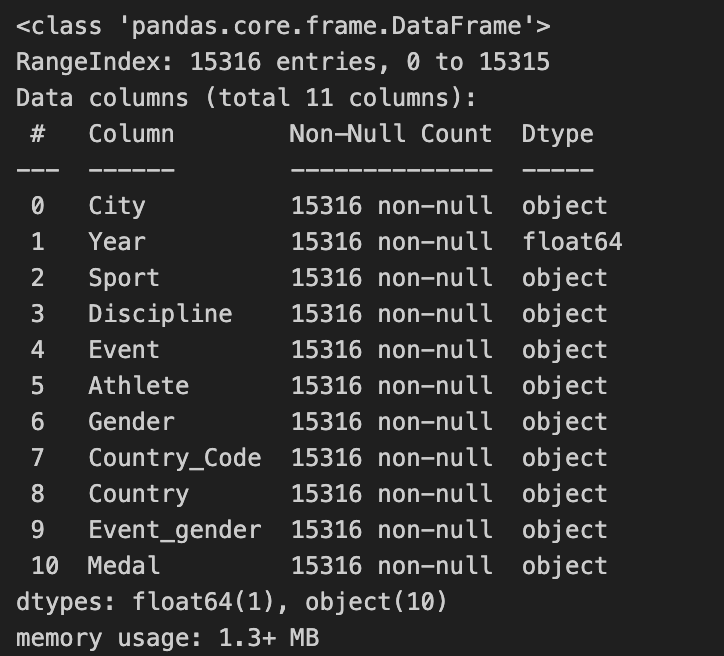
Yearcolunm 데이터 타입을 int로 변경- 나머지 Dtype의 경우
object이기 때문에 처음부터string형을 띄움
- 나머지 Dtype의 경우
df_target['Year'] = df_target['Year'].astype(int)
df_target.info()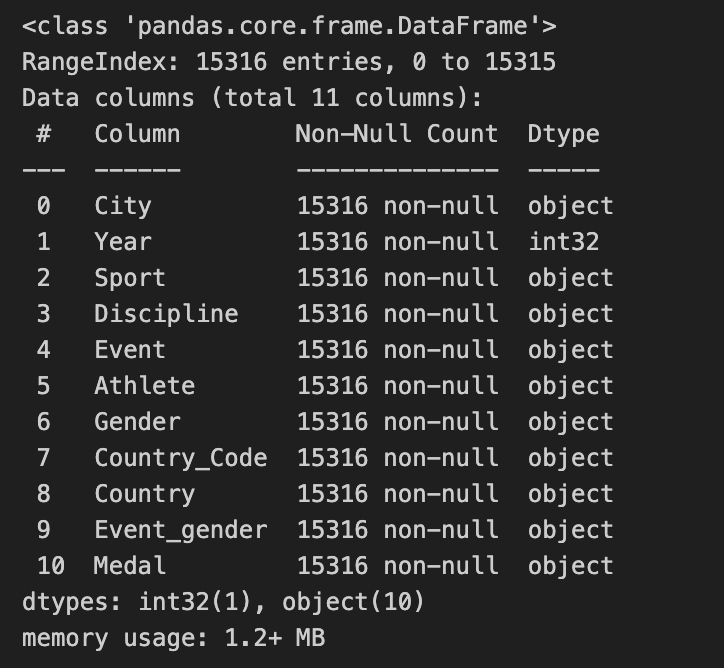
Step 2. 원하는 데이터로 가공하기
2-1. 2008년 대한민국 메달리스트 찾기
- Deep Copy를 진행 후 데이터 프레임 생성
- 2008년 양궁 종목의 금메달리스트 DataFrame 생성
import copy
df = df_target.copy()
df_archery = df[(df['Year'] == 2008) & (df['Sport'] == 'Archery') & (df['Medal'] == 'Gold') & (df['Country_Code'] == 'KOR')]
df_archery
2-2. 대한민국 역대(1976-2008) 하계 올림픽 메달 획득 내역 확인
- 대한민국 올림픽 메달 획등 내역 중, 해당 조건에 해당하는 중복 데이터 제거
- 조건 : 선수명(Athlete)과 성별(Gender)를 제외한 내용이 일치할 경우 같은 경기에서 획득한 메달로 간주
df_kor = df_target.copy()
df_kor = df_target[df_target['Country_Code'] == 'KOR']
df_kor = df_kor.drop_duplicates(subset = ['City', 'Year', 'Discipline', 'Event', 'Country_Code', 'Country', 'Event_gender','Medal'])
df_kor
Year,Medal을 기준으로pivot_tableYear를 내림차순,Medal을 Gold-Silver-Bronze 순으로 정렬하려하였으나,Medal정렬이 되지 않음
df_gold = pd.pivot_table(
df_kor,
index = ['Year','Medal'],
values= ['City'],
aggfunc = 'count'
)
df_gold- numpy의 vectorize를 활용하여
sort_index
custom_key = np.vectorize(lambda x: {"Gold": 0, "Silver": 1, "Bronze": 2}[x] if type(x) == str else x)
df_gold.sort_index(axis = 0, level = [0, 1], key=custom_key, inplace=True)
df_gold| Before | After |
|---|---|
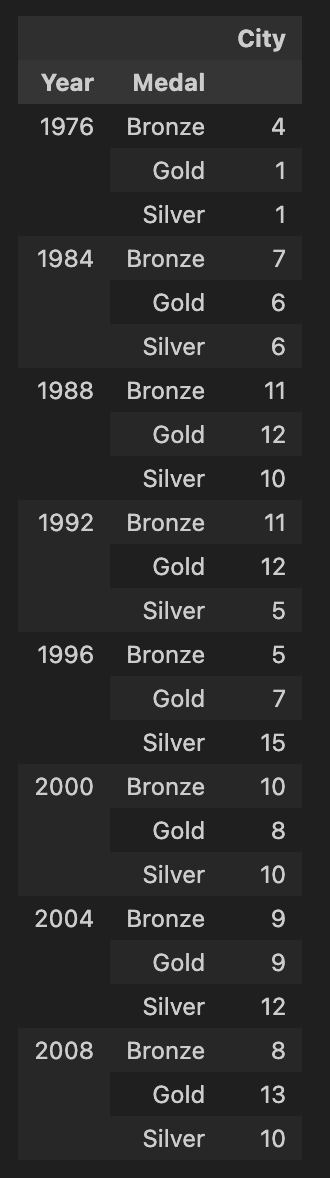 | 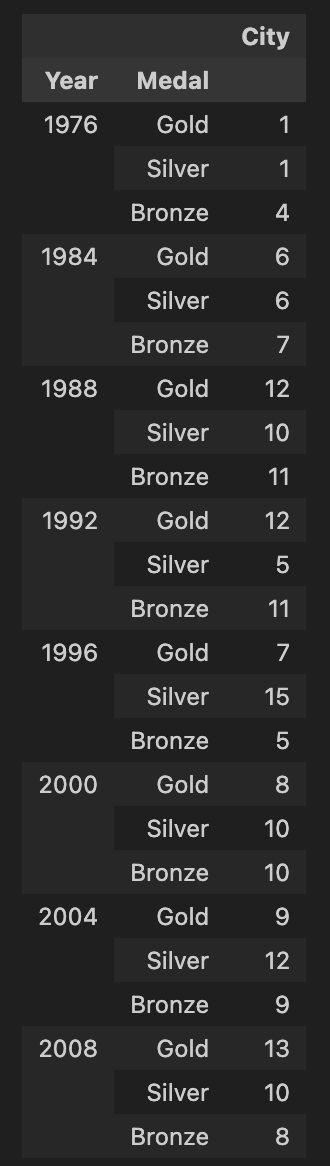 |
2-3. 1996년 애틀란타 올림픽 총 메달 개수 기준 상위 10개 국가 확인하기
- 1996년 애틀란타 올림픽 총 메달 갯수 및 상위 10개 국가 선정
- 2-2와 마찬가지로 중복값 제거 후 진행
df_rank = df_target.copy()
df_rank = df_rank[df['Year'] == 1996]
df_rank = df_rank.drop_duplicates(subset = ['City','Year', 'Discipline', 'Event', 'Country_Code', 'Country', 'Event_gender','Medal'])
df_rank = pd.pivot_table(
df_rank,
index = 'Country',
values= ['Medal'],
aggfunc = 'count'
)
df_rank = df_rank.reset_index()
df_rank.sort_values('Medal', ascending = False, inplace = True)
df_rank_10 = df_rank.head(10)
df_rank_10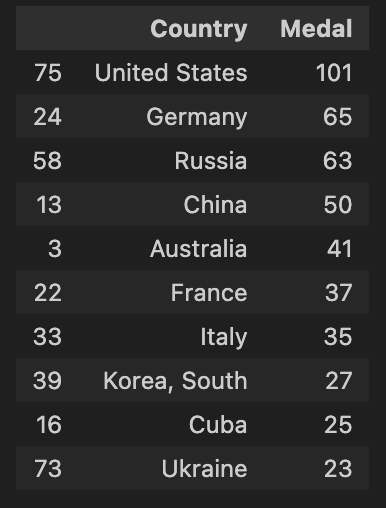
2-4. 1996년 애틀란타 올림픽 금매달 개수 기준 상위 10개 국가 확인하기
gold.silver.bronzecolumn 생성 후,Medalcolumn의 입력 내용에 따라 0과 1 입력- 2-2, 2-3과 마찬가지로 중복 값 제거 및 인덱스 초기화
df_gold_rank = df_target.copy()
df_gold_rank[['Gold','Silver','Bronze']] = 0
df_gold_rank = df_gold_rank[df_gold_rank['Year'] == 1996]
df_gold_rank = df_gold_rank.drop_duplicates(subset = ['City', 'Year', 'Discipline', 'Event', 'Country_Code', 'Country', 'Event_gender', 'Medal'])
df_gold_rank = df_gold_rank.reset_index()
df_gold_rank.drop('index', axis = 1, inplace = True)
for idx in range(0, len(df_gold_rank)):
if df_gold_rank['Medal'].loc[idx] == 'Gold':
df_gold_rank['Gold'].loc[idx] = 1
elif df_gold_rank['Medal'].loc[idx] == 'Silver':
df_gold_rank['Silver'].loc[idx] = 1
elif df_gold_rank['Medal'].loc[idx] == 'Bronze':
df_gold_rank['Bronze'].loc[idx] = 1
df_gold_rank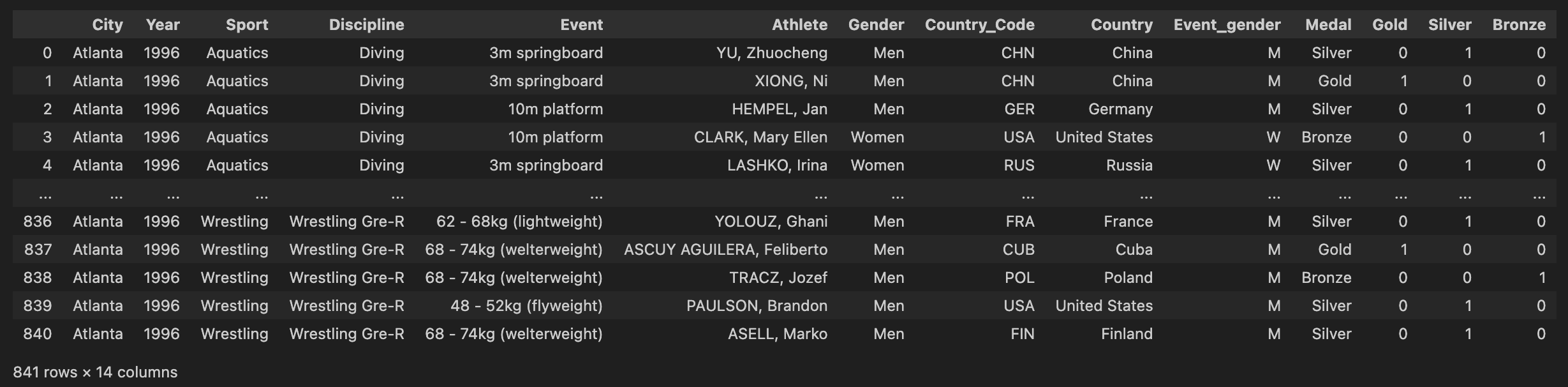
- pivot_table을 통해 각 나라별 Gold, Silver, Bronze 메달 갯수 카운팅 및 정렬
- 상위 10개 국가를 나타내는 DataFrame 생성
df_gold_rank_10 = pd.pivot_table(
df_gold_rank,
index = 'Country',
values= ['Gold', 'Silver', 'Bronze'],
aggfunc = 'sum'
)
df_gold_rank_10 = df_gold_rank_10.reset_index()
df_gold_rank_10.sort_values(['Gold', 'Silver', 'Bronze'], ascending = False, inplace = True)
df_rank10 = df_gold_rank_10[['Country', 'Gold', 'Silver', 'Bronze']]
df_rank10 = df_rank10.head(10)
df_rank10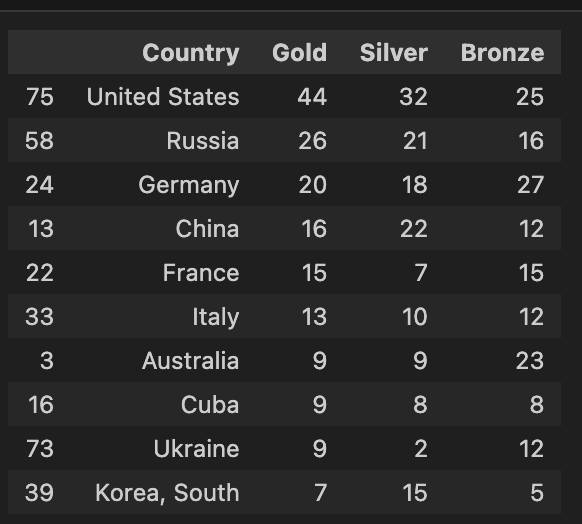

Start