🔑 개요
목표
- 시카고 샌드위치 맛집 소개 페이지 분석
- 총 51개 페이지에서 각 가게의 정보를 가져온다
- 가게이름
- 대표메뉴
- 대표메뉴의 가격
- 가게주소
링크
- https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-Chicago/
- chicago magazine the 50 best sandwiches
📗 세부내용
Pre
- 메인 페이지
- 시카고 50개 맛집 샌드위치에 대해 메뉴와 가게 이름이 정리되어 있다.
- 세부페이지
- 각각을 소개한 50개의 페이지에 가게 주소와 대표 메뉴의 가격이 있다.
- 최종목표
- 총 51개 페이지에서 각 가게의 정보를 가져온다.
Step 1. DataAnalysis - 메인페이지
- header 에 웹 브라우저 정보를 입력
- UserAgent()를 통해 fake 정보를 입력
# !pip install fake-useragent
from urllib.request import Request, urlopen
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "Chicago-Magazine/November-2012/Best-Sandwiches-Chicago/"
url = url_base + url_sub
ua = UserAgent()
req = Request(url, headers={"user-agent": ua.ie})
html = urlopen(req)
soup = BeautifulSoup(html, "html.parser")
print(soup.prettify())- find / select 함수를 통해 tag = div, class = sammy 값 저장
len()을 이용하여 50개 가게 정보를 가져 온 것을 확인
soup.find_all("div", "sammy"), len(soup.find_all("div", "sammy"))
# soup.select(".sammy"), len(soup.select(".sammy"))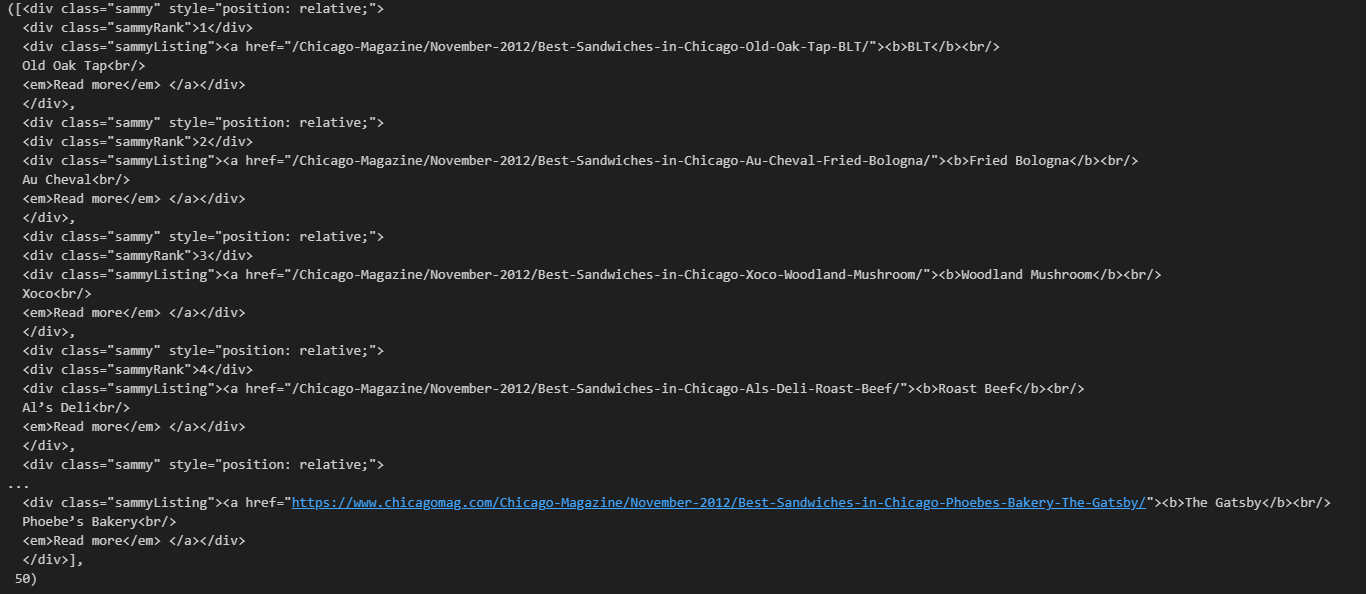
- 한 개의 정보를 통해 필요한 내용 선별
- 랭킹, 가게이름, 메뉴
<div class="sammy" style="position: relative;">
<div class="sammyRank">1</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/>
Old Oak Tap<br/>
<em>Read more</em> </a></div>
</div>type = bs4.element.Tag: find 명령을 사용할 수 있다는 뜻
tmp_one= soup.find_all("div", "sammy")[0]
type(tmp_one)- 가게 랭킹 추출
tmp_one.find(class_="sammyRank").get_text()
# tmp_one.select_one(".sammyRank").text- 메뉴 이름 추출
tmp_one.find("div", {"class":"sammyListing"}).get_text()
# tmp_one.select_one(".sammyListing").text- 가게 링크 추출
tmp_one.find("a")["href"]
# tmp_one.select_one("a").get("href")remodule의split()을 이용하여 가게 이름과 메뉴 이름 구분
import re
tmp_string = tmp_one.find(class_="sammyListing").get_text()
re.split(("\n|\r\n"), tmp_string)Output :['BLT', 'Old Oak Tap', 'Read more ']
print(re.split(("\n|\r\n"), tmp_string)[0]) # menu
print(re.split(("\n|\r\n"), tmp_string)[1]) # cafeOutput :
BLT
Old Oak Tap
1-1. 50개 가게 데이터 정리
- 필요한 내용을 담을 빈 리스트 생성
- 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정
from urllib.parse import urljoin
url_base = "http://www.chicagomag.com"
rank = [] # 순위
main_menu = [] # 메인메뉴
cafe_name = [] # 가게이름
url_add = [] # 주소- 랭킹, 메뉴, 가게정보, url 값을 불러와 각각 할당
list_soup = soup.find_all("div", "sammy") # soup.select(".sammy")
for item in list_soup:
rank.append(item.find(class_="sammyRank").get_text())
tmp_string = item.find(class_="sammyListing").get_text()
main_menu.append(re.split(("\n|\r\n"), tmp_string)[0])
cafe_name.append(re.split(("\n|\r\n"), tmp_string)[1])
url_add.append(urljoin(url_base, item.find("a")["href"]))- 데이터가 잘 들어왔는지 확인
len(rank), len(main_menu), len(cafe_name), len(url_add)- 가져온 데이터들을 이용하여 데이터프레임(DataFrame) 형태로 변환
import pandas as pd
data = {
"Rank": rank,
"Menu": main_menu,
"Cafe": cafe_name,
"URL": url_add,
}
df = pd.DataFrame(data)
df.tail()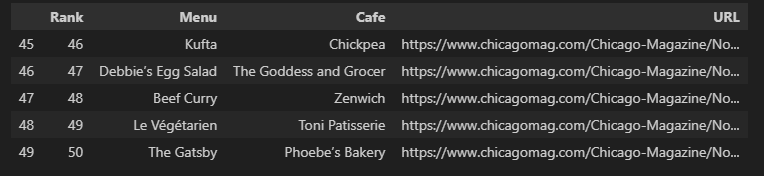
- 컬럼 순서 변경 및 데이터 저장
# 컬럼 순서 변경
df = pd.DataFrame(data, columns=["Rank", "Cafe", "Menu", "URL"])
df.tail()
# 데이터 저장
df.to_csv(
"../data/03. best_sandwiches_list_chicago.csv", sep=",", encoding="utf-8"
)Step 2. DataAnalysis - 하위 페이지
- ModuleLoad
# requirements
import pandas as pd
from urllib.request import urlopen, Request
from fake_useragent import UserAgent
from bs4 import BeautifulSoup- DataLoad
df = pd.read_csv("../data/03. best_sandwiches_list_chicago.csv", index_col=0)
df.tail()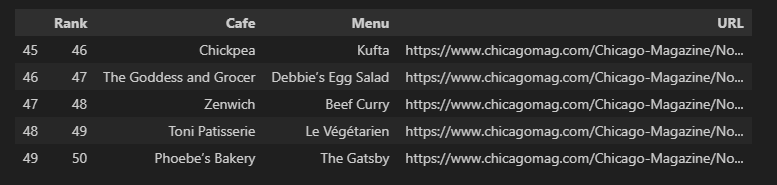
- 각 가게의 주소(URL)에 들어가서 정보 가져오기
- p 태그 addy class에 정보가 존재
req = Request(df["URL"][0], headers={"user-agent":ua.ie})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
soup_tmp.find("p", "addy") # soup_find.select_one(".addy")- 각 정보가 한 문장으로 존재
가격,주소
# regular expression
price_tmp = soup_tmp.find("p", "addy").text
price_tmpOutput : '\n$10. 2109 W. Chicago Ave., 773-772-0406, [theoldoaktap.com](http://theoldoaktap.com/)'
regular expression(정규식)을 통해 원하는 정보를 가져옴
import re # regular expression 정규 표현식
re.split(".,", price_tmp)
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price_tmp[len(tmp) + 2:]Output : '2109 W. Chicago Ave’
- 전체 과정(50개) 진행
tqdm을 통해 진행율 표시
from tqdm import tqdm
price = []
address = []
for idx, row in tqdm(df.iterrows()):
req = Request(row["URL"], headers={"user-agent":ua.ie})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp)+2:])
print(idx)- 데이터프레임에 가격과 주소 정보 추가
df["Price"] = price
df["Address"] = address
df = df.loc[:, ["Rank", "Cafe", "Menu", "Price", "Address"]]
df.set_index("Rank", inplace=True)
df.head()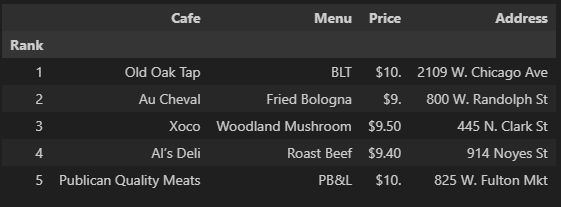
데이터 저장
df.to_csv(
"../data/03. best_sandwiches_list_chicago2.csv", sep=",", encoding="UTF-8"
)Step 3. Visualization
# requirements
import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdmdf = pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv", index_col=0)
df.tail()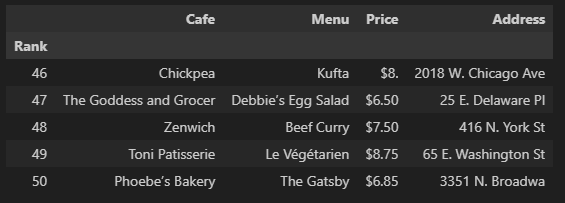
- Google Map API 이용
gmaps_key = "************"
gmaps = googlemaps.Client(key=gmaps_key)- 전체 과정 합쳐줌 - 여러 지점이 있을 경우, Multiple location 값을 가져오기 떄문에 Multiple location은 제외
lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
# print(target_name)
gmaps_output = gmaps.geocode(target_name)
location_ouput = gmaps_output[0].get("geometry")
lat.append(location_ouput["location"]["lat"])
lng.append(location_ouput["location"]["lng"])
# location_output = gmaps_output[0]
else:
lat.append(np.nan)
lng.append(np.nan)
- 가게 좌표(latitude, longitude) 추가
df["lat"] = lat
df["lng"] = lng
df.tail()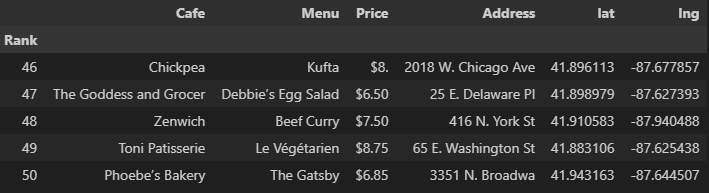
- 지도에 맵핑(Mapping)
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"], row["lng"]],
popup=row["Cafe"],
tooltip=row["Menu"],
icon=folium.Icon(
icon="coffee",
prefix="fa"
)
).add_to(mapping)
mapping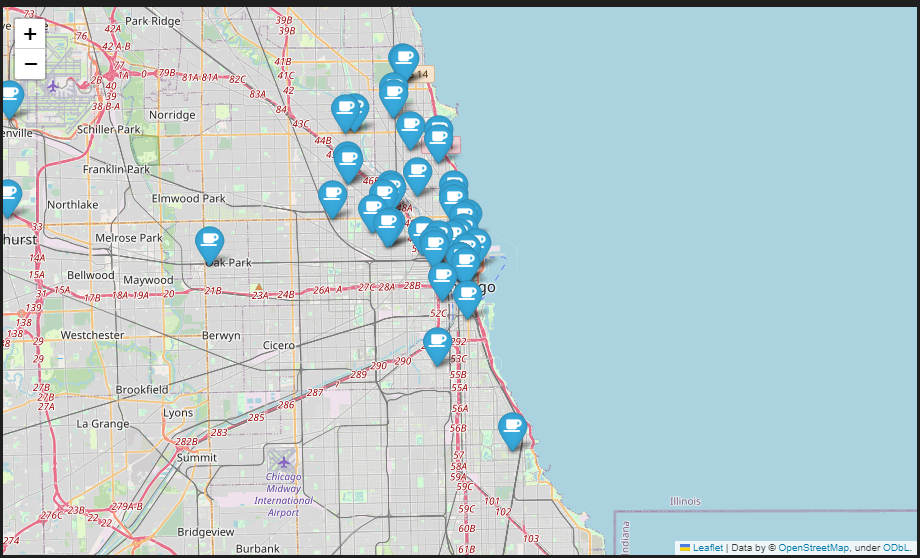

Start