유가 분석
Goal
- 서울시 주유소를 대상으로 셀프 주유소가 저렴한지 확인
Data
-
대한민국 주유 가격을 알아보는 사이트
-
목표 데이터
- 브랜드, 가격, 셀프 주유 여부, 위치
Step1. Analysis of Cite Structure
- [싼 주유소 찾기] - [지역별] 선택
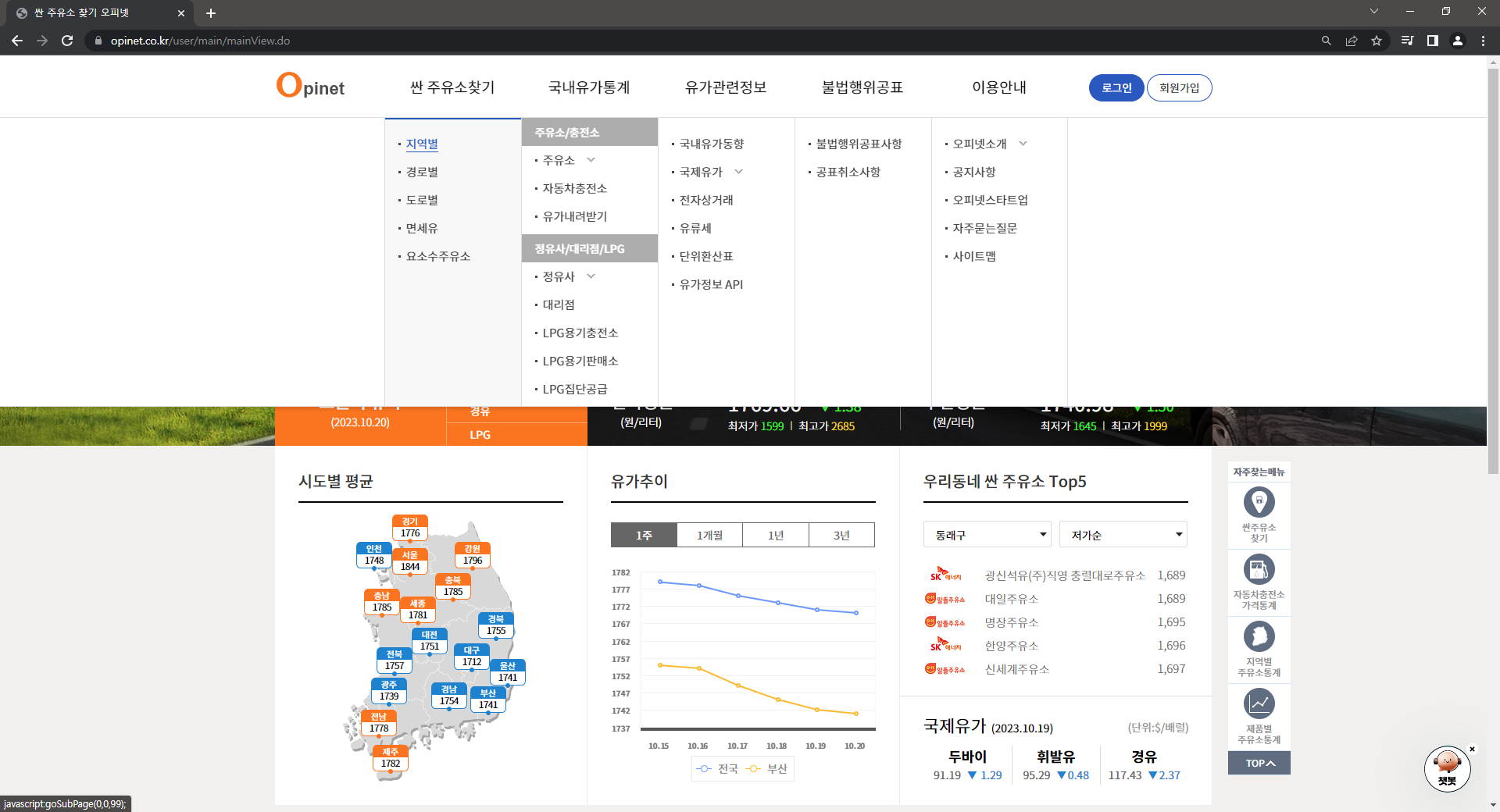
- [지역] : 광역시/도, 시, 구 정보 입력
- 지도가 바뀌고, 잠시 후 주유소 정보 로딩
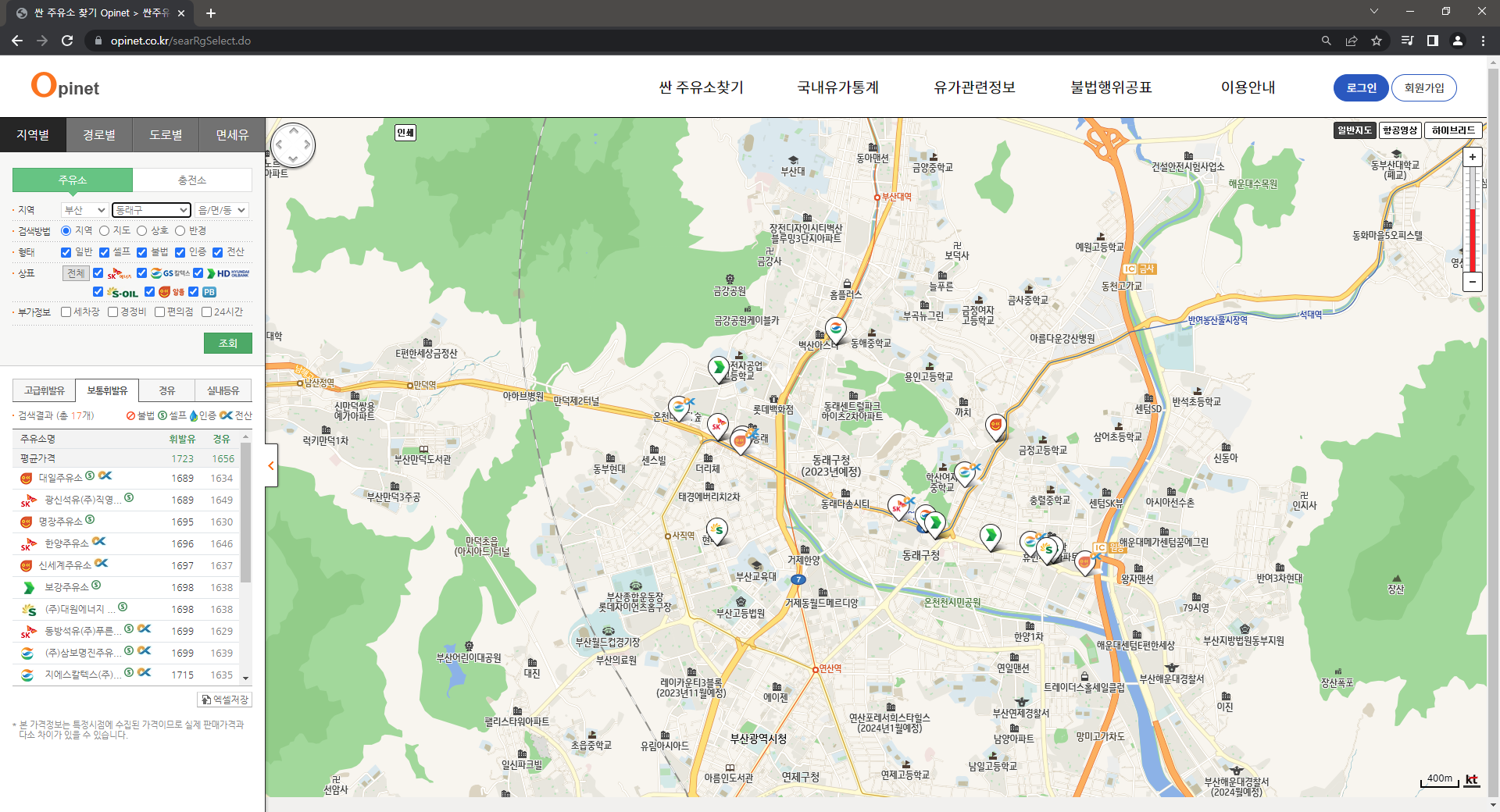
Step2. Access Using Selenium
2-1. 시/도
- 페이지 접근
import time
from selenium import webdriver
driver = webdriver.Chrome('driver/chromedriver.exe')
def main_page_access():
driver.get('https://www.opinet.co.kr')
time.sleep(1)
driver.get('https://www.opinet.co.kr/searRgSelect.do')main_page_access() # 페이지 이동- 시/도 element 추출
# 지역 시/도
sido_list_raw = driver.find_element_by_id('SIDO_NM0')
sido_list_raw.textOutput :
' 시/도\n \n \n \n 서울\n \n \n \n 부산\n \n \n \n \n \n 대구\n \n \n \n \n 인천\n \n \n \n \n 광주\n \n \n \n \n 대전\n \n \n \n \n 울산\n \n \n \n \n 세종\n \n \n \n \n 경기\n \n \n \n \n 충북\n \n \n \n \n 충남\n \n \n \n \n 전북\n \n \n \n \n 전남\n \n \n \n \n 경북\n \n \n \n \n 경남\n \n \n \n \n 제주\n \n \n \n \n 강원\n \n \n ‘
- Tag 길이 확인
sido_list = sido_list_raw.find_elements_by_tag_name('option') # Tag 길이 확인
len(sido_list), sido_list[17].textOutput : (18, '강원')
- Tag 값 내
value가져오기
sido_list[1].get_attribute('value') # 태그 값의 Value 가져오기Output : '서울특별시’
- 시/도 리스트 내 빈 칸 확인 및 제거
sido_names = []
for option in sido_list:
sido_names.append(option.get_attribute('value'))
sido_names[:5]Output : ['', '서울특별시', '부산광역시', '대구광역시', '인천광역시']
sido_names = sido_names[1:] # 빈 칸 제거
sido_names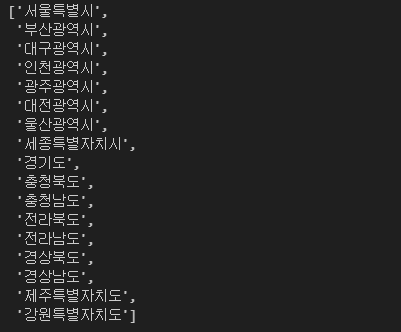
- 지역 변경
sido_list_raw.send_keys(sido_names[16]) # 지역 변경2-2. 구
- 구 정보 추출
# 구
gu_list_raw = driver.find_element_by_id('SIGUNGU_NM0')
gu_list = gu_list_raw.find_elements_by_tag_name('option') # Tag 길이 확인
len(gu_list), gu_list
gu_names = []
for option in gu_list:
gu_names.append(option.get_attribute('value'))
gu_names[:5]
gu_names = gu_names[1:] # 빈 칸 제거
gu_names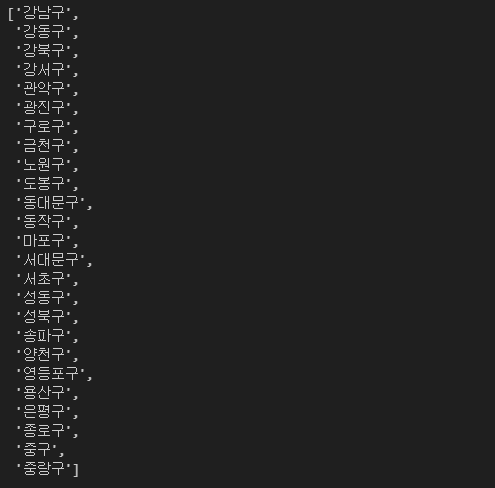
- 지역 변경
gu_list_raw.send_keys(gu_names[16]) # 지역 변경엑셀 저장
# 엑셀 저장
driver.find_element_by_css_selector('#glopopd_excel').click()- 엑셀 저장
import time
from tqdm import tqdm_notebook
for gu in tqdm_notebook(gu_names):
element = driver.find_element_by_id('SIGUNGU_NM0')
element.send_keys(gu)
time.sleep(3)
element_get_excel = driver.find_element_by_css_selector('#glopopd_excel').click()
time.sleep(3)- 끝내기
driver.close() # 끝내기Step 3. Merge DataFrame
- Module Load
import pandas as pd
from glob import glob- 파일 목록 호출
- 저장한 엑셀 파일 목록 호출
glob('EDA_practice_data\지역_*.xls') # 파일 목록 호출
stations_files = glob('EDA_practice_data\지역_*.xls')
stations_files[:5]
- 데이터 확인 위해 하나 읽어오기
# 하나만 읽어오기
tmp = pd.read_excel(stations_files[0], header = 2) # header부터 column을 가져와라.
tmp.tail()
tmp_raw = []
for file_name in stations_files:
tmp = pd.read_excel(file_name, header = 2)
tmp_raw.append(tmp)- 형식이 동일하고 연달아 붙이기만 할 경우 concat 사용
stations_raw = pd.concat(tmp_raw)
stations_raw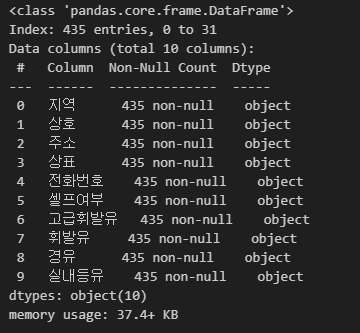
- 전체 데이터 확인
# 전체 데이터 확인
stations_raw.info()
- column명 확인
stations_raw.columns
- DataFrame 생성
stations = pd.DataFrame({
'상호' : stations_raw['상호'],
'주소' : stations_raw['주소'],
'가격' : stations_raw['휘발유'],
'셀프' : stations_raw['셀프여부'],
'상표' : stations_raw['상표']
})
stations.tail()
- 구별 주소만 꺼내기
# 구별 주소만 꺼내기
stations['구'] = [eachAddress.split()[1] for eachAddress in stations['주소']]
stations.tail()
- 가격 데이터형 변환
- 가격 정보가 있는 주유소만 사용
# 변환 전, 가격정보 없는 데이터 확인
stations[stations['가격'] == '-']
# 가격 정보 있는 주유소만 사용
stations = stations[stations['가격'] != '-']
stations
- 가격 Data type을
float로 변경
stations['가격'] = stations['가격'].astype(float)
stations
- 인덱스(Index) 재정렬
- 삭제된 데이터로 인해 인덱스가 흐트러졌기 때문에 재생성
# 인덱스 재정렬
stations.reset_index(inplace = True)
stations.head()
del stations['index']
stations.head()

Start