
🔑 Goal
- EDIYA Coffee는 실제로 Starbucks Coffee 매장 근처에 있는지 분석
📗 세부내용
Step 0. Module Load
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
plt.rcParams['font.family'] = 'Malgun Gothic'
from selenium import webdriver
import requests
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
from urllib.request import urlopen
from tqdm import tqdm_notebook
import folium
import platformStep 1. 스타벅스 매장 분석
import time
import tqdmChrome Driver 설정 및 웹 페이지
- 스타벅스 매장 찾기 홈페이지 접속하여 화면 최대화 설정
driver = webdriver.Chrome('driver/chromedriver.exe') # 구글드라이버 경로 입력
driver.get("https://www.starbucks.co.kr/store/store_map.do ") # 원하는 창 오픈
driver.maximize_window() # 화면 최대화
- 서울 매장검색을 위해 [지역] - [서울] - [전체] 클릭
driver.find_element(By.CSS_SELECTOR, "#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a").click() # 지역검색 클릭
time.sleep(1)
driver.find_element(By.CSS_SELECTOR, "#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a").click() # 서울 클릭
time.sleep(1)
driver.find_element(By.CSS_SELECTOR, '#mCSB_2_container > ul > li:nth-child(1) > a').click() # 전체 클릭
time.sleep(3)B
Beautifulsoup 통해 데이터 불러오기
from bs4 import BeautifulSoup
req = driver.page_source # 해당 페이지 저장
soup = BeautifulSoup(req, 'html.parser')
print(soup.prettify())
- 매장별 정보 가져오기
contents = soup.select('.quickResultLstCon') # 매장별 정보
contents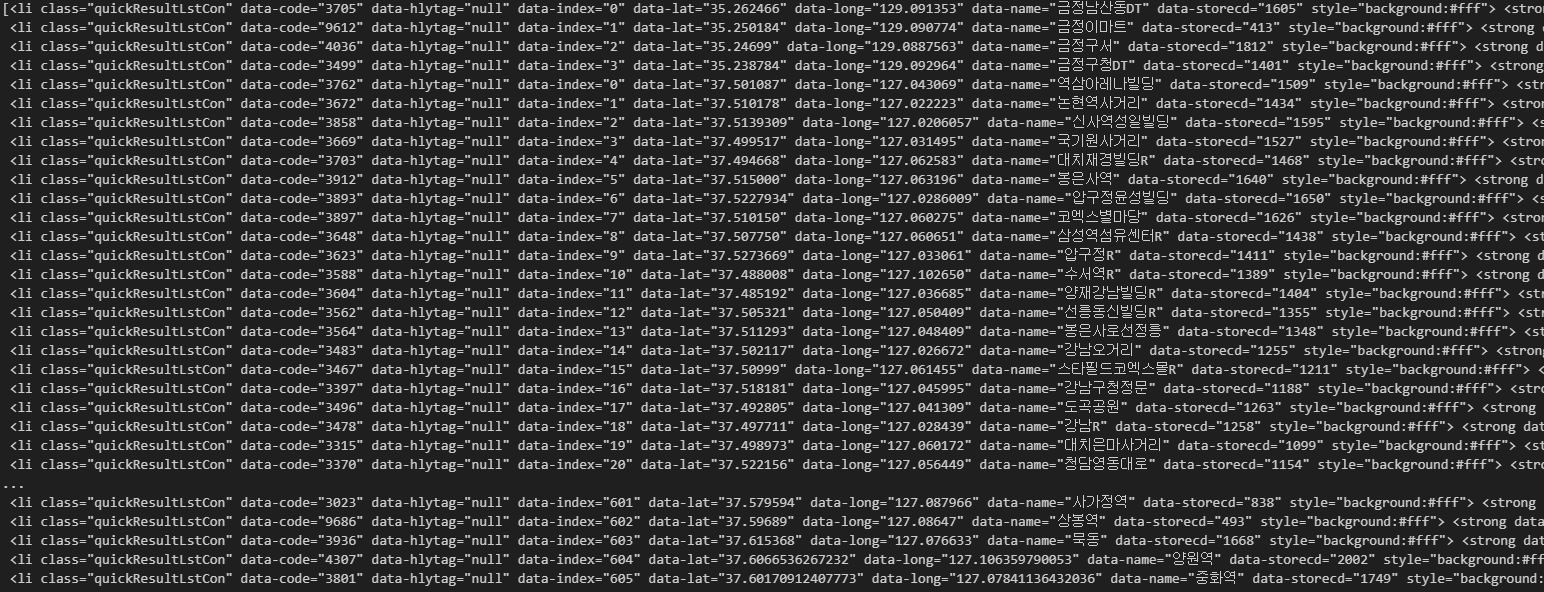
- 매장 정보를 추출하기 위해 임의의 행을 선택하여 확인
contents[30].select_one('p').text # 주소 정보 확인Output : '서울특별시 강남구 삼성로 402 (대치동)1522-3232’
contents[30].select_one('strong').text # 지점 확인Output : '대치사거리 ‘
contents[30].select_one('p').text.split(' ')[1] # 구 정보 확인Output : '강남구’
- 수집한 정보를 가져와
이름,주소,구이름에 해당하는 데이터 리스트 생성
# 데이터 프레임 만들기
name_list = []
gu_name_list = []
address_list = []
for data in tqdm_notebook(contents):
name = data.select_one("strong").text[:-2] # 이름
address = data.select_one("p").text # 주소
gu_name = data.select_one("p").text.split(" ")[1] # 구 이름
name_list.append(name)
address_list.append(address)
gu_name_list.append(gu_name)
time.sleep(0.5)
driver.quit()- 데이터 프레임 생성
df = pd.DataFrame(
{'name':name_list,
'address':address_list,
'gu_name': gu_name_list})
df
- 부산 지역 4개 지점이 같이 수집되어, 부산 지역 매장 삭제
df.iloc[0:4]
df.drop([0, 1, 2, 3], axis = 0, inplace = True) # 부산지역 4개 가 같이 따라와서 삭제
df.reset_index(drop = True)
데이터 저장 (스타벅스)
df.to_csv('starbucks_store.csv', encoding = 'utf-8', index = False) # 데이터 저장Step 2. EDIYA 매장
- 이디야 매장 찾기 홈페이지 접속하여 화면 최대화 설정
E_driver = webdriver.Chrome('driver/chromedriver.exe') # 구글드라이버 경로 입력
E_driver.get("https://ediya.com/contents/find_store.html ") # 원하는 창 오픈
E_driver.maximize_window() # 화면 최대화
- 스타벅스 매장 위치가 있는 ‘구’ 호출
gu_List = df['gu_name'].unique() # 스타벅스 매장 위치 있는 '구' 호출
gu_List
- 홈페이지에서 구를 입력 후 검색
E_driver.find_element(By.CSS_SELECTOR, '#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a').click() # 주소란에 구를 입력
E_driver.find_element(By.CSS_SELECTOR, '#keyword').send_keys(gu_List[0])
E_driver.find_element(By.CSS_SELECTOR ,'#keyword_div > form > button').click() # 돋보기를 클릭함
- 현재 창 주소를 저장
E_req = E_driver.page_source # 현재 창 주소 저장
E_soup = BeautifulSoup(E_req, "html.parser")
print(E_soup.prettify())
- 매장별 정보를 추출하기 위한 부모 태그
E_contents = E_soup.select('.item') # 매장별 정보 추출하기 위한 부모 태그
E_contents[2]Output :
<li class="item"><a href="#c"><div class="store_thum"><img src="../images/customer/store_thum.gif"/></div><dl><dt>강남논현학동점</dt> <dd>서울 강남구 논현로131길 28 (논현동)</dd></dl></a></li>
- 필요 정보 추출을 위해 임의 행 지정하여 구, 매장이름, 주소 확인
E_contents[2].select_one('dd').text.split(' ')[1] # 구 이름Output : '강남구’
E_contents[2].select_one('dt').text # 매장이름Output : '강남논현학동점’
E_contents[2].select_one('dd').text # 주소Output : '서울 강남구 논현로131길 28 (논현동)’
- 해장 지역(구)에 대한 정보 수집 후, 검색창 지우기
E_driver.find_element_by_css_selector("#keyword").clear() # 검색창 지우기Error
- 실행코드를 작성하여 돌렸으나, 오류가 발생
- 원인 : 중구의 경우, 매장 수가 많아 검색 결과 오류 발생
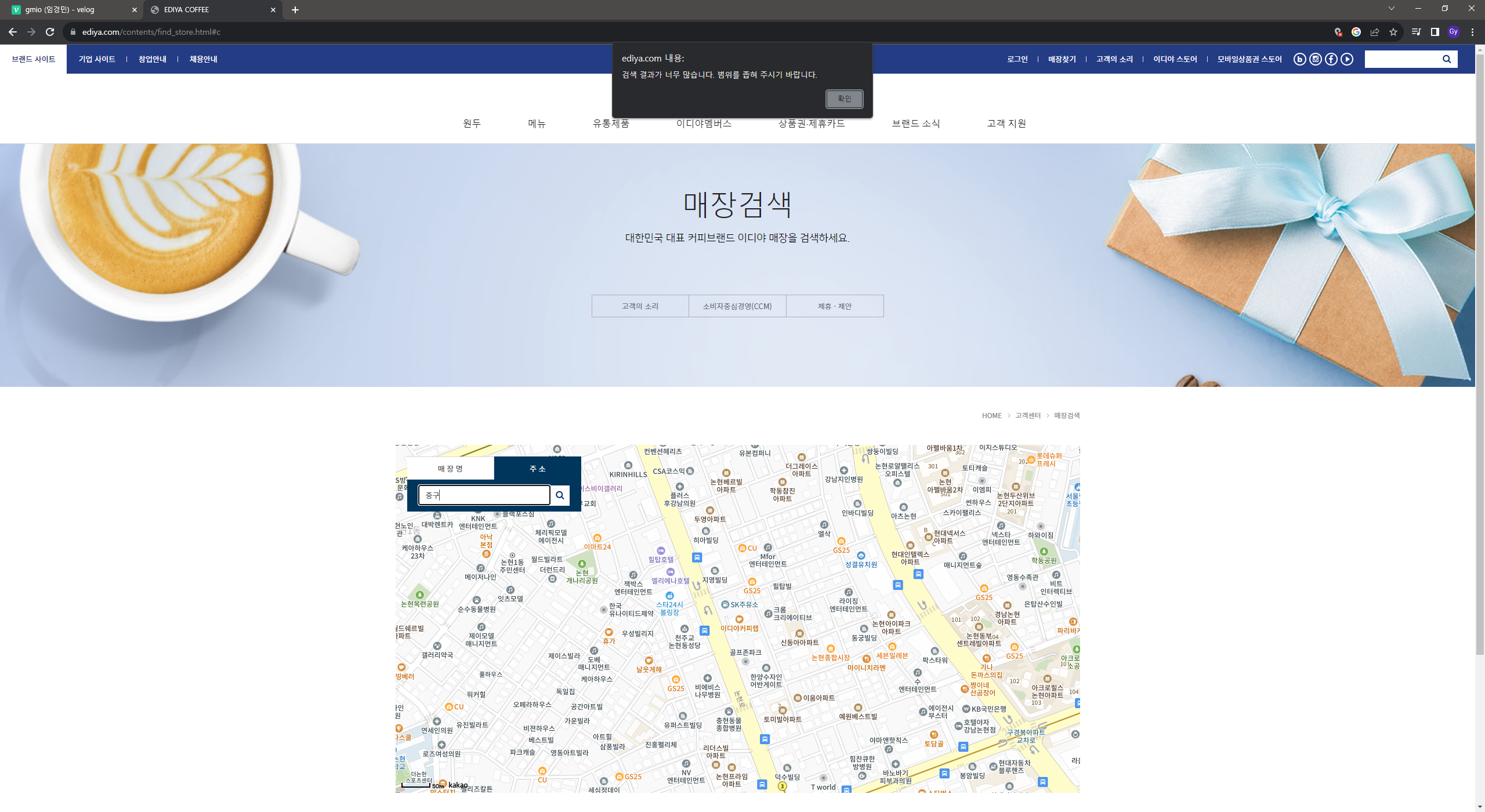
- 따라서 ‘중구’ column명을 ‘서울 중구’로 변경
gu_List[-7] = '서울 중구'
gu_List- 정보 수집 및 각 정보(구 이름, 매장이름, 주소)를 리스트에 저장
E_data = []
for guIdx in tqdm_notebook(range(len(gu_List))):
E_driver.find_element(By.CSS_SELECTOR, '#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a').click() # 주소란에 구를 입력
E_driver.find_element(By.CSS_SELECTOR, '#keyword').send_keys(gu_List[guIdx])
E_driver.find_element(By.CSS_SELECTOR ,'#keyword_div > form > button').click() # 돋보기를 클릭함
time.sleep(0.5)
print(gu_List[guIdx]) # 오류가 발생, 검색정보가 많은 구 확인
E_req = E_driver.page_source # 현재 창 주소 저장
E_soup = BeautifulSoup(E_req, "html.parser")
time.sleep(0.5)
E_contents = E_soup.select('.item') # 매장별 정보 추출하기 위한 부모 태그
time.sleep(0.5)
for data in E_contents:
name = data.select_one('dd').text.split(' ')[1] # 구 이름
address = data.select_one('dt').text # 매장이름
gu = data.select_one('dd').text # 주소
E_data.append({
"이름" : name,
"주소" : address,
"구" : gu
})
E_driver.find_element_by_css_selector("#keyword").clear() # 검색창 지우기
time.sleep(0.5)
driver.quit()데이터 프레임 생성 및 저장
ediya = pd.DataFrame(E_data) # 데이터프레임 만들어 저장
ediya.to_csv('ediya_store.csv', encoding = 'utf-8', index = False)Step 3. EDIYA/스타벅스 매장 간 관계 분석
- 데이터 불러오기
df_starbucks = pd.read_csv('starbucks_store.csv', encoding = 'utf-8')
df_ediya = pd.read_csv('ediya_store.csv', encoding = 'utf-8')- 스타벅스, 이디야 구분을 위해
brandcolumn 추가
# brand 추가
df_starbucks['브랜드'] = '스타벅스' ; df_ediya['브랜드'] = '이디야'
df_starbucks.columns = ['이름', '주소', '구', '브랜드'] # 두 데이터 프레임 column명 일치
df_ediya.columns = ['구', '이름', '주소', '브랜드'] # 두 데이터 프레임 column명 일치- 하나의 데이터 프레임으로 변환
df_brand = pd.concat([df_starbucks, df_ediya]) # 데이터 병합
df_brand
전체 매장 갯수
brandCnt = df_brand[['구','브랜드']].groupby(['브랜드']).count()
brandCnt = brandCnt.reset_index()
brandCnt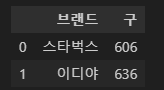
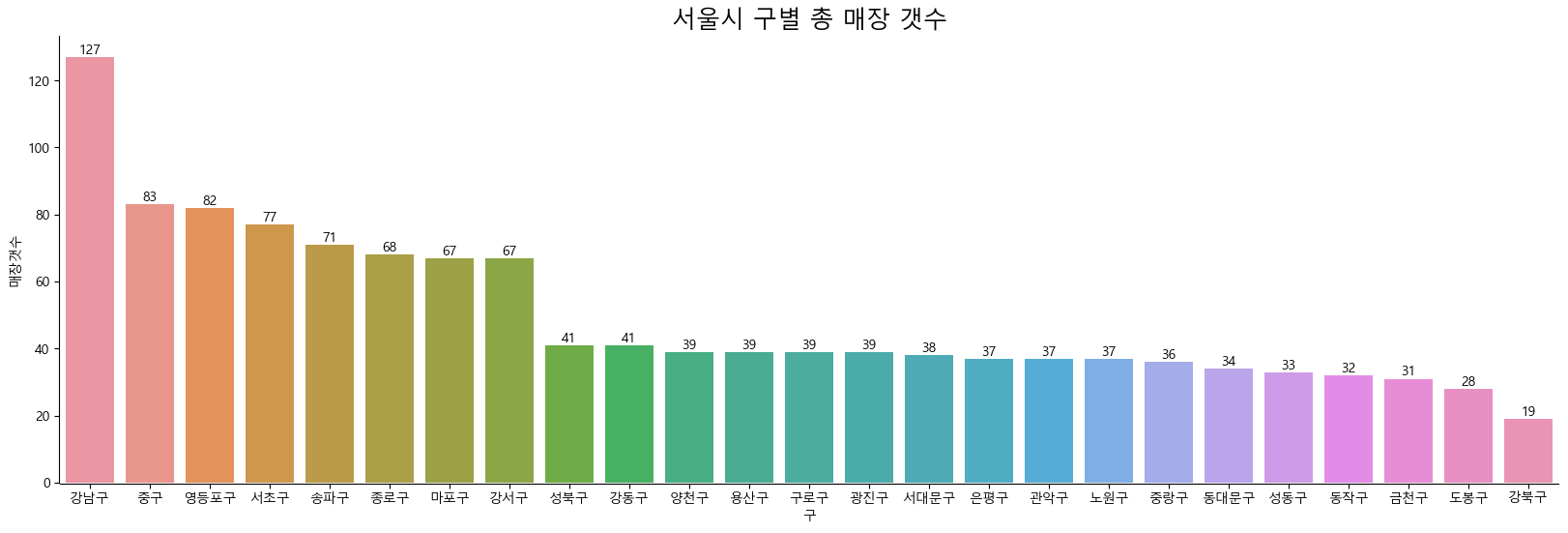
서울시 구별 총 매장 갯수
brandCnt = df_brand[['구','브랜드']].groupby(['구']).count()
brandCnt.columns = ['매장갯수']
brandCnt = brandCnt.reset_index()
brandCnt = brandCnt.sort_values(by = '매장갯수', ascending = False)
plt.figure(figsize=(20, 6))
fig_1 = sns.barplot(x = '구', y = '매장갯수', data = brandCnt)
plt.title('서울시 구별 총 매장 갯수', size = 18)
sns.despine(offset = 0.5)
for p in fig_1.patches:
cntVal = int(p.get_height())
fig_1.text(
x = p.get_x() + p.get_width() / 2,
y = p.get_height() + p.get_y() + 1,
s = cntVal,
ha = 'center'
)
- 서울시 구별 각 브랜드 매장 갯수
brandCnt2 = df_brand[['구','브랜드','주소']].groupby(['구','브랜드']).count()
brandCnt2.columns = ['매장갯수']
brandCnt2 = brandCnt2.sort_values(by = '매장갯수', ascending = False)
brandCnt2 = brandCnt2.reset_index()
plt.figure(figsize=(20, 6))
fig_2 = sns.barplot(x = '구', y = '매장갯수', hue = '브랜드', data = brandCnt2, palette= 'Set1')
plt.title('서울시 구별 각 브랜드 매장 갯수', size = 18)
sns.despine(offset = 0.5)
for p in fig_2.patches:
cntVal = int(p.get_height())
fig_2.text(
x = p.get_x() + p.get_width() / 2,
y = p.get_height() + p.get_y() + 1,
s = cntVal,
ha = 'center',
)
# print(f'x = {p.get_x()}, y={p.get_y()} wide={p.get_width()} height={p.get_height()} ')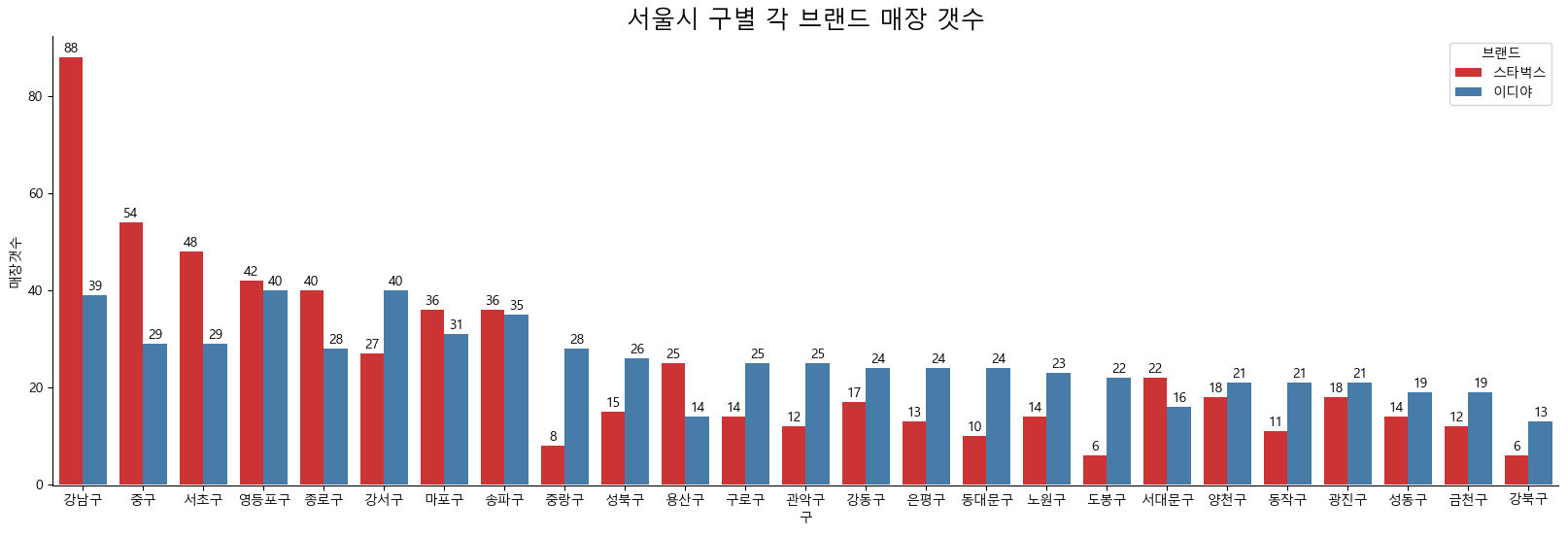
매장 위치 지도 시각화
- Googlemaps를 활용하여 각 매장의 위경도 정보 가져오기
import googlemaps
gmaps_key = '***********************' # Google Key
gmaps = googlemaps.Client(key = gmaps_key)
gmaps.geocode('이디야 서울 강남YMCA점', language='ko')[0].get('geometry') # Test
- Googlemaps를 활용하여 각 매장의 위경도 정보 가져오기
tmp1 = df_brand[df_brand['브랜드']=='스타벅스']
tmp2 = df_brand[df_brand['브랜드']=='이디야']
## 좌표 불러오기
tmp1['lat'] = np.nan ; tmp1['lon'] = np.nan
tmp2['lat'] = np.nan ; tmp2['lon'] = np.nan
import googlemaps
gmaps_key = 'AIzaSyAyS0HZsy46gyFUhDlIwYQbHdXXCWHNpc8' # 키 복사 후 입력
gmaps = googlemaps.Client(key = gmaps_key)
for idx, rows in tmp1.iterrows():
try:
staion_name = str(rows['브랜드']) + " " + "서울" + " " + str(rows["이름"])
geo_location = gmaps.geocode(staion_name)[0].get('geometry')
lat = geo_location['location']['lat']
lon = geo_location['location']['lng']
tmp1.loc[idx, 'lat'] = lat
tmp1.loc[idx, 'lon'] = lon
except:
print(f'{idx} address not find')
continue
for idx, rows in tmp2.iterrows():
try:
staion_name = str(rows['브랜드']) + " " + "서울" + " " + str(rows["이름"])
geo_location = gmaps.geocode(staion_name)[0].get('geometry')
lat = geo_location['location']['lat']
lon = geo_location['location']['lng']
tmp2.loc[idx, 'lat'] = lat
tmp2.loc[idx, 'lon'] = lon
except:
print(f'{idx} address not find')
continue- 위경도 정보를 병합
- 주소를 가져오지 못하는 매장의 경우, drop 처리 진행
tmpMerge = pd.concat([tmp1, tmp2]) # 데이터 병합
tmpMerge = tmpMerge.dropna()
myMap = folium.Map(
location=[37.541, 126.986], #서울시 좌표
zoom_start = 15,
tiles = 'CartoDB positron')
for idx, rows in tmpMerge.iterrows():
if rows['브랜드'] == '스타벅스':
circle = folium.CircleMarker(
location = [rows['lat'], rows['lon']],
radius = 10,
fill = True,
color = 'red',
fill_color = 'red',
tooltip = rows['이름']
).add_to(myMap)
elif rows['브랜드'] == '이디야':
circle = folium.CircleMarker(
location = [rows['lat'], rows['lon']],
radius = 10,
fill = True,
color = 'blue',
fill_color = 'blue',
tooltip = rows['이름']
).add_to(myMap)
myMap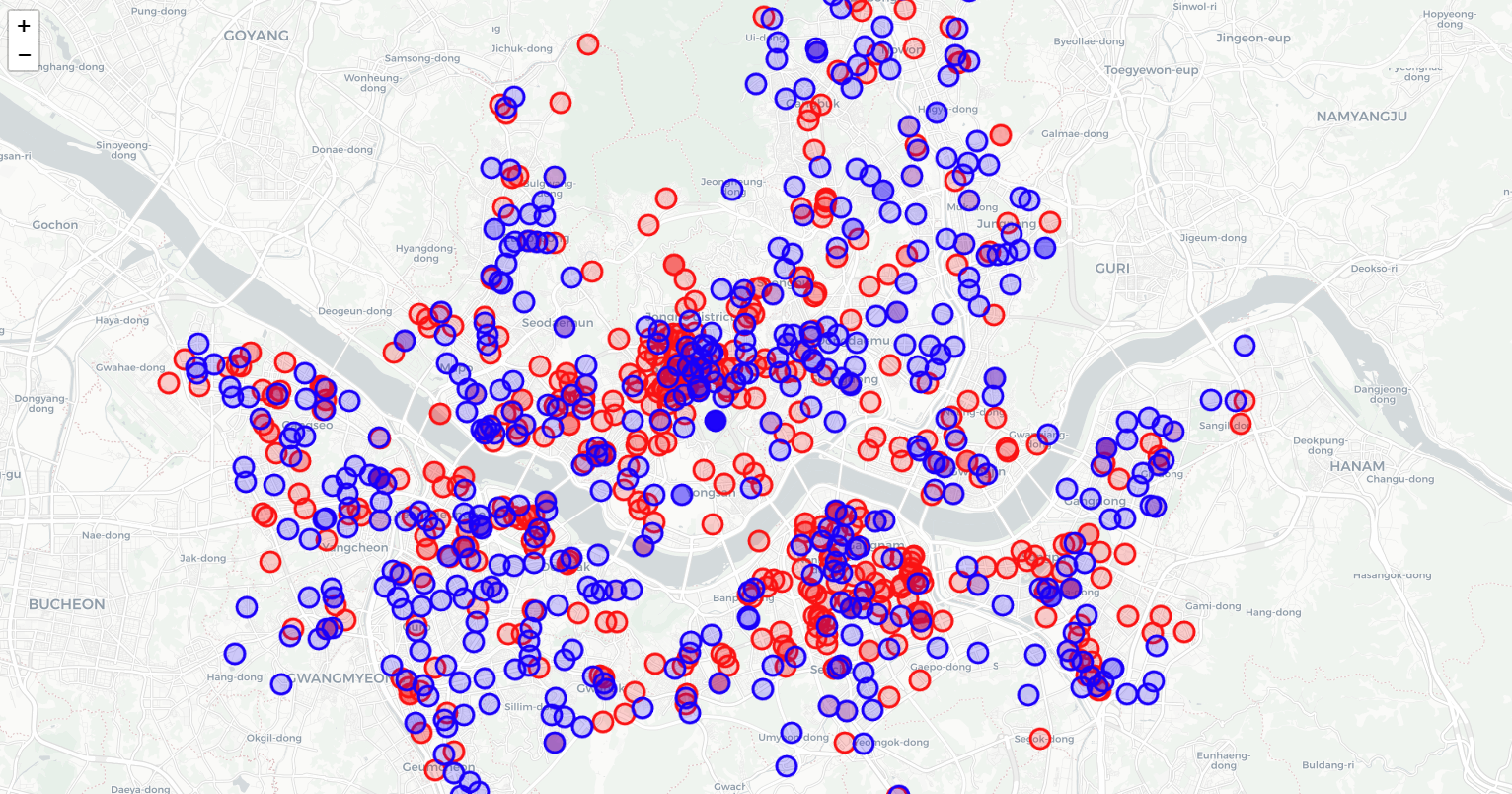
결과
- 서울 내 스타벅스의 매장은 606개, 이디야는 636개로, 비슷한 양상을 보임
- 구별로 보았을 때, 강남구가 가장 많았으며, 중구, 영등포구, 서초구 순으로 매장 갯수가 많음을 보임
- 스타벅스와 이디야 매장을 비교하였을 때, 대체적으로 유사한 경우는 영등포구, 마포구, 송파구, 양천구, 광진구로 보여짐
- 그 외 구에서는 특이점을 찾지 못함
- 스타벅스 비중이 많은 구 : 강남구, 중구, 서초구, 종로구, 용산구
- 이디야 비중이 많은 구 : 중랑구, 성북구, 구로구, 관악구, 은평구, 동대문구, 도봉구, 동작구, 강북구 등
- 스타벅스(Red)와 이디야(Blue) 매장을 지도에 표시하였을 때, '이디야 커피는 스타벅스 매장 근처에 있다' 라고 할 수는 없다고 보여짐

Start