개요
이 글은 ML 분야에서 혁신을 불러온 Transformer에 대하여 소개하기에 앞서, Transformer을 이해하기 위한 Background에 대하여 서술한 글이다. Seq2Seq 모델을 주로 다룬다.
Transformer에 대하여 공부할 때, 단순히 transformer의 구조를 공부하는 것보다 그 이전 모델인 Seq2Seq 모델과 비교하면서 이해하는 방식이 훨씬 직관적이고 깊게 이해할 수 있기에 이를 적게 되었다.
NMT
Transformer은 NMT(Neural Machine Translation) 분야에서 처음으로 등장하였다. Neural Machine Translation은 Neural net을 이용하여 번역을 시도하는 분야이다. 기존의 베이지안을 이용한 통계적 방식(SMT)에 비하여 훨씬 좋은 성능을 보여주었다.
Seq2Seq 모델
Transformer 이전에 NMT 분야를 이끌던 model은 2014년에 등장한 Seq2Seq 모델이다. Seq2Seq 모델은 2014년 구글에서 발표한 Sequence to Sequence Learning with Neural Networks 논문에서 소개된 모델이다. 여기서 말하는 Sequence는 일련의 단어열을 의미한다. 즉, Seq2Seq 모델은 일련의 단어열을 입력받고, 입력을 기반으로 다시 일련의 단어열을 출력하는 특징을 따서 이러한 이름을 가지게 되었다.
Seq2Seq 모델의 Preprocessing (Embedding)
Seq2Seq 모델의 입출력은 일련의 단어열로 구성된다. 그러나, 컴퓨터는 문자열을 이해하는 것이 크게 난해하다. 따라서 각 단어는 영문자의 조합으로 들어가는 것 대신 벡터로 변환하여 들어간다. 이를 Embedding 과정이라 한다.
Seq2Seq 모델의 구조
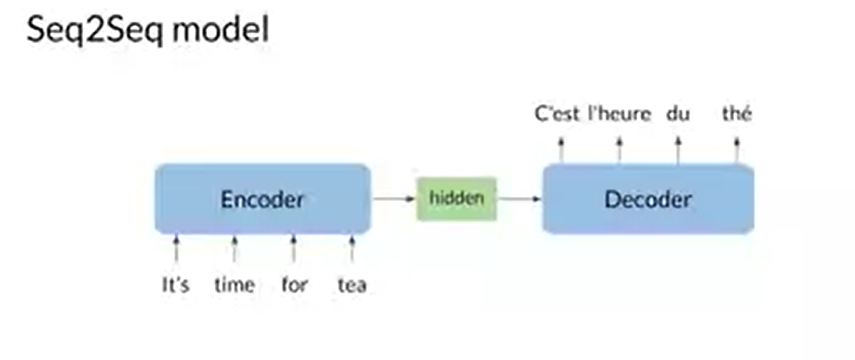
Seq2Seq 모델의 큰 구조는 위 그림과 같다. Encoder가 input으로 단어열을 받고, hidden state라 부르는 RNN의 matrix를 통해 input의 정보들을 Decoder으로 전달한다. 그러면 이제 전달된 정보에 기반하여 Decoder에서 순차적으로 번역된 문장의 벡터 형태를 출력하고, 이는 Embedding 표를 통하여 번역된 문장으로 변환된다.
Encoder의 구조
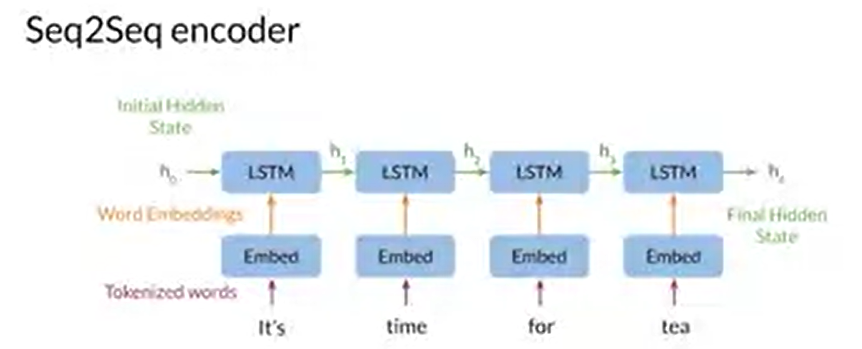
Encoder의 목적은 현재 문장의 정보를 연산하여, decoder가 output을 출력하기 위한 정보를 생성하는 것이다. encoder의 구조는 위와 같이 RNN(혹은 LSTM)의 구조로 되어 있다. 각 단계에서, RNN은 이전의 정보와 자신의 정보를 압축하여 hidden state로 전달한다. input의 모든 단어가 입력된 뒤에는 입력 종료 단어 <sos>가 입력되며, <sos>가 입력되기 전까지의 단계가 encoder이다. encoder 종료 시점에서 입력 문장의 모든 정보는 RNN의 hidden state에 압축되어 있다.
위의 사진에서 보면, h1은 It's에 대한 정보를, h2는 It's와 time에 대한 정보를 각각 포함하고 있다. 이 과정이 반복되어, h4에서는 It's time for tea 문장에 대한 정보가 압축되어 저장된 상태가 된다.
Decoder의 구조
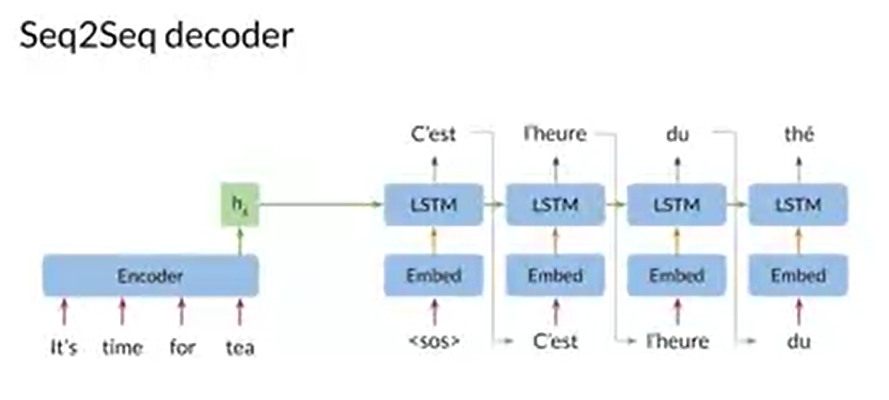
Decoder의 목적은 output의 문장을 첫 단어부터 마지막 단어까지 순차적으로 예측하는 것이다.
input에서 <sos>가 전달되어 입력 단어가 종료되면 Decoder이 시작된다. 첫 번째 단계에서, Encoder에서 전달된 hidden state와 input <sos> 를 기반으로 output의 첫 번째 단어를 예측한다. 예측한 단어와 Decoder의 첫 번째 단계에서 나온 hidden state를 기반으로 output의 두 번째 단어를 예측한다. decoder은 이러한 과정을 반복하여 output sequence를 예측할 수 있다.
Attention
Seq2Seq 모델의 한계
hidden state에는 용량의 한계가 있으며, RNN의 특징상 오랫동안 사용하면 앞의 정보가 손실되는 특징도 있다. 이 때문에 input 문장이 길어질 경우 충분한 정보가 hidden state에 저장되지 못해 번역 성능의 저하가 심각하였다.
Attention의 등장
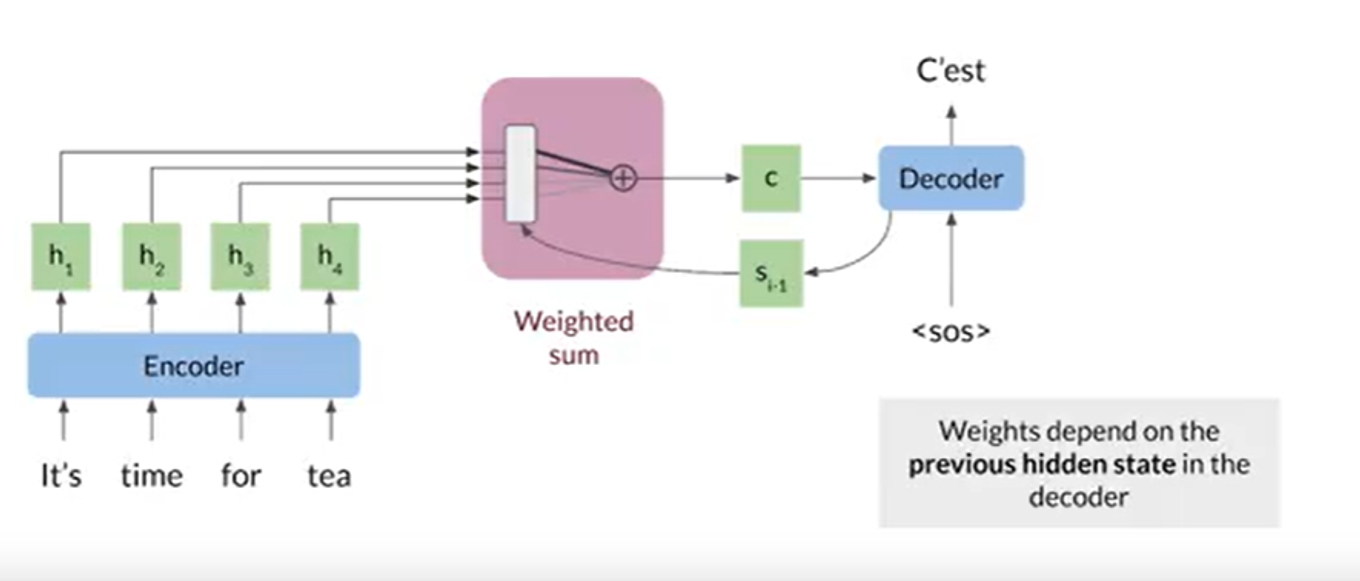
Hidden state의 용량에 제한이 있고, 단계를 거칠수록 앞 단계의 정보가 손실된다. 그러면 이전 단계의 hidden state들을 저장했다 이후 추론에 사용하면 되는 것 아닌가? Attention의 기본 발상은 이와 같다. encoder에서 출력된 각각의 hidden state를 저장하고, 이를 기존의 decoder의 hidden state 입력값 대신 사용한다.
그러나, 모든 hidden state를 한 번에 사용하기에는 연산량이 과하게 많았다. 이 때문에, hidden state들을 하나의 hidden state의 크기로 압축하는 방식이 필요했고, 이를 weighted sum으로 해결하였다. 해당 단계에서 중요도가 높은 hidden state에 높은 weight를 주고자 한 것이다. 이 때의 weight를 중요한 것에 집중한다고 하여 Attention이라 명명되었다.
