개요
Transformer은 2017년 Attention is all you need 논문에서 소개된 모델로, 원래 분야인 NMT에서 최고 성능을 기록한 모델이다. 나아가 최근에는 ML 분야 전반적으로 기본 구조로써 사용되고 있는 모델이다.
이전 글에서 Transformer의 Background에 대하여 설명하였기에, 이 글에서는 Transformer의 구조를 중심으로 소개한다.
모델 구조
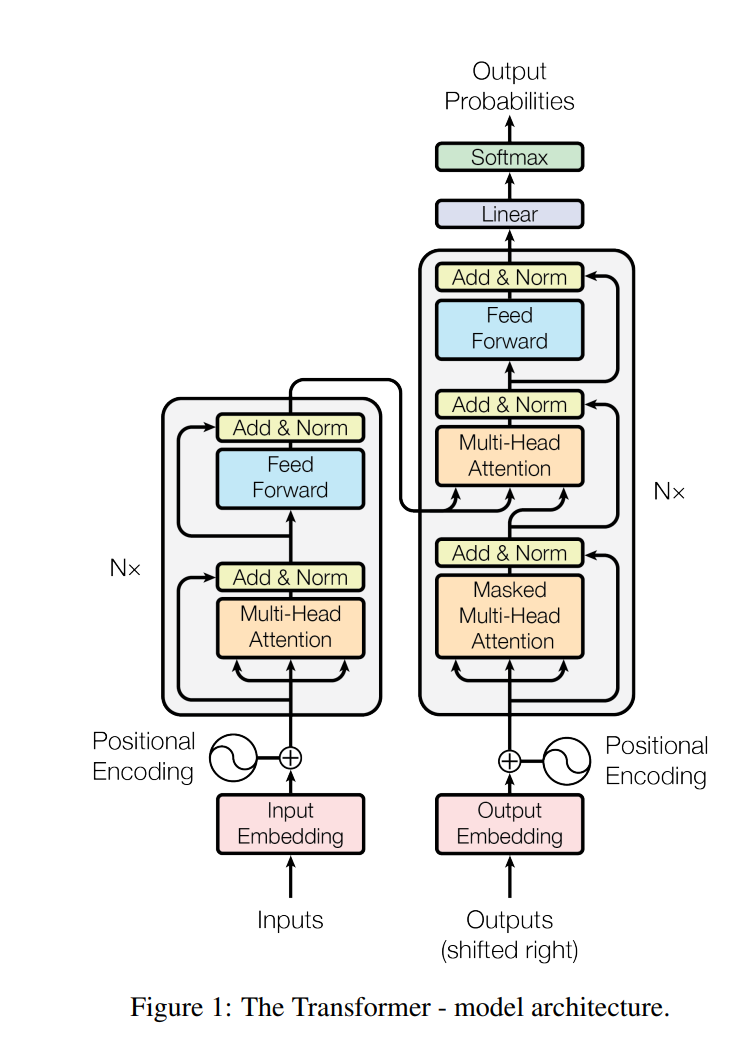
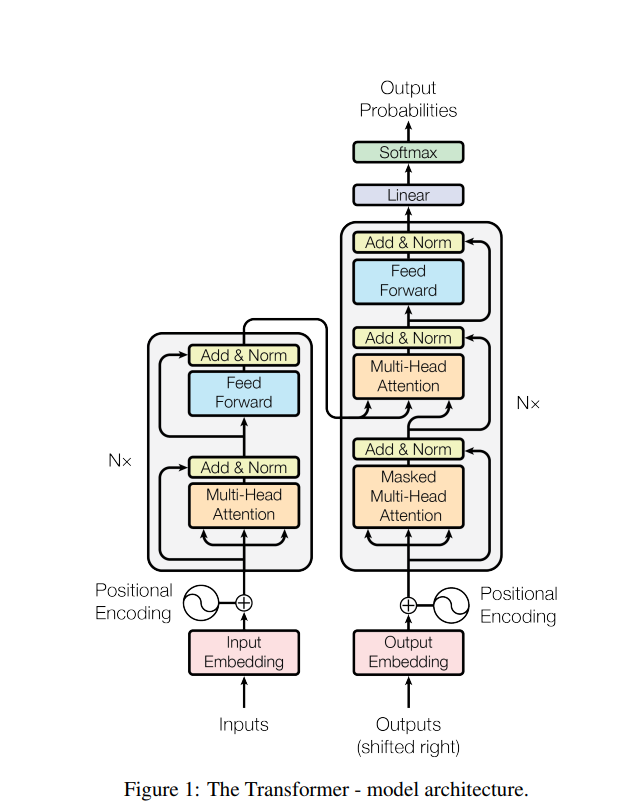 논문에 게시된 Transformer의 전체 구조는 위와 같다. Seq2Seq의 핵심 구조였던 RNN 없이, Encoder과 Decoder부가 전부 Attention만으로 전부 구성되어 있다. 이것이 Transformer 모델의 가장 큰 특징이며, 논문 제목 역시 "Attention is all you need"이다.
가장 작은 부분인 Attention에서부터 전체 모델 구조까지, 차근차근 이해해 보도록 하자.
논문에 게시된 Transformer의 전체 구조는 위와 같다. Seq2Seq의 핵심 구조였던 RNN 없이, Encoder과 Decoder부가 전부 Attention만으로 전부 구성되어 있다. 이것이 Transformer 모델의 가장 큰 특징이며, 논문 제목 역시 "Attention is all you need"이다.
가장 작은 부분인 Attention에서부터 전체 모델 구조까지, 차근차근 이해해 보도록 하자.
Attention
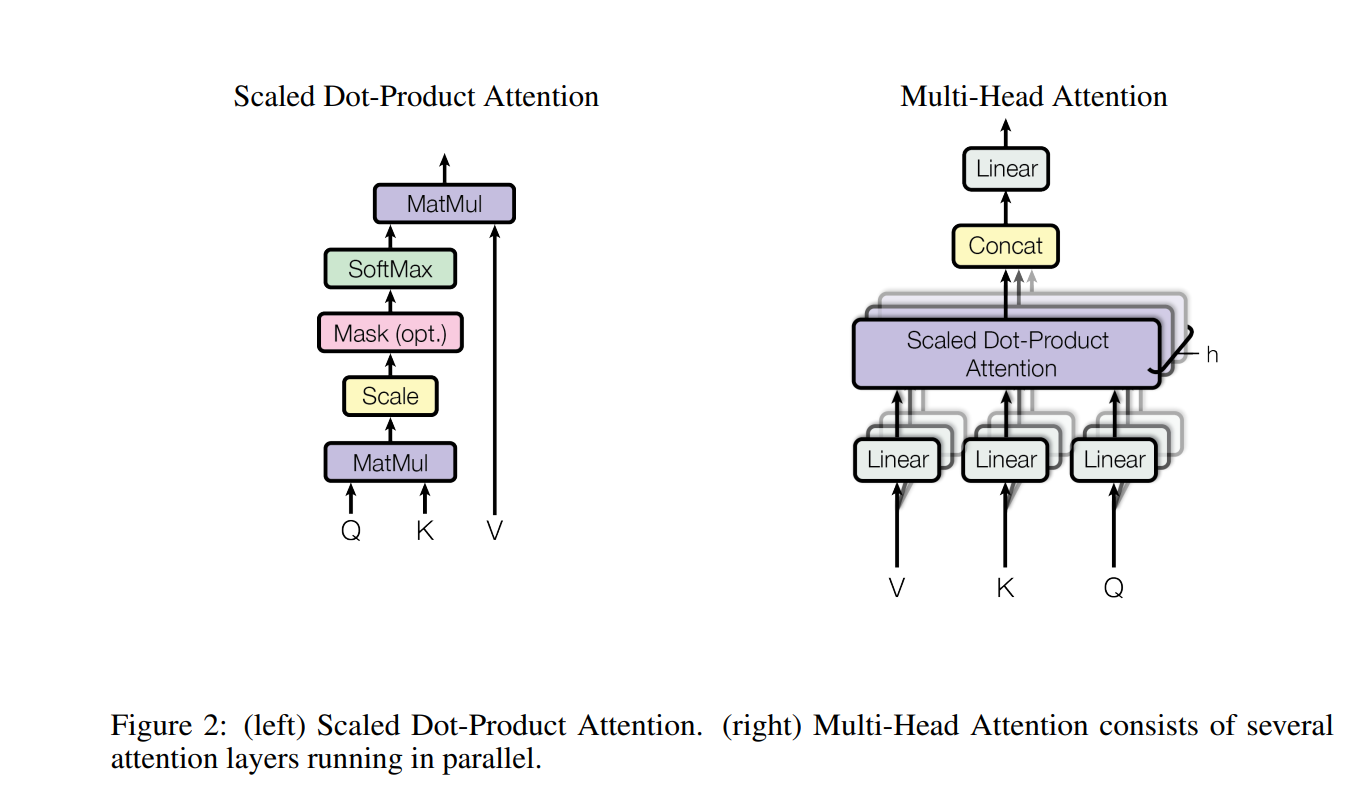 RNN없이 Encoder,Decoder이 전부 Attention으로 구성되었다는 것이 Transformer의 핵심인 만큼, Transformer에서 가장 중요한 구조는 Attention이다. 위의 전체 구조에서 보다시피 Transformer에서 사용한 Attention은 Multi-Head Attention이며, 이러한 Multi-Head Attention은 다시 Scaled Dot-Product Attention과 여러 구조들로 구성되어 있다.
RNN없이 Encoder,Decoder이 전부 Attention으로 구성되었다는 것이 Transformer의 핵심인 만큼, Transformer에서 가장 중요한 구조는 Attention이다. 위의 전체 구조에서 보다시피 Transformer에서 사용한 Attention은 Multi-Head Attention이며, 이러한 Multi-Head Attention은 다시 Scaled Dot-Product Attention과 여러 구조들로 구성되어 있다.
Attention이란 무엇인가
Attention은 한국어로 주의, 집중이라는 의미를 가진다. Attention은 Seq2Seq 모델에서 여러 input에 주어지는 가중치였으며, 해당 input에 얼마나 주의를 기울여야 하는지에 대한 정보를 알려주는 부분이었다. 조금 더 구체적으로 말하면, Seq2Seq 모델에서 특정 순서의 Decoder 값을 출력할 때, 각 Encoder의 hidden state들을 하나로 압축하기 위하여 관련된 정도를 판별하여 Attention score를 계산하고, 이를 가중치로 부여하는 방식을 의미했다.
Attention is all you need 논문에서는 Attention에 대하여 다음과 같이 서술한다.
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
Attention은 query, key-value 쌍에 대하여 output을 mapping하는 함수이다. output은 value의 weighted sum으로 구성되며, 각 weight는 qurey와 key의 호환성 함수를 통하여 계산된다.
이는 Scaled Dot-Product Attention을 보면 이해가 쉬울 것이다.
Scaled Dot-Product Attention
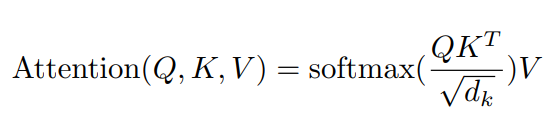
Scaled Dot-Product Attention은 Transformer 기본 attention이다. Query와 Key의 호환성(attention score)을 계산하고, 이를 softmax를 이용하여 weight(attention distribution)의 형태로 바꾼다. 마지막으로 이를 weight로 하여 value를 weight sum 한 것이다. 이를 단계별로 차근차근 진행해 보자.
1.Attention Score 구하기
1.1 Query와 Key를 내적하여 Attention Score 구하기
Attention Score을 구하는 방법은 여러 가지가 있으며, 저자는 Additive attention과 dot product attention 중 더 빠른 속도와 공간 효율성을 위하여 dot product attention을 선택하였다고 한다.
1.2.scaling
dot product는 좋으나, 연산을 함에 따라 이후 softmax를 적용함에 있어 치우침 문제가 발생하였다고 한다. 이를 보정하기 위하여 로 나누었다고 말한다.
개인적으로는 dot product는 분산값에 가 영향을 미치게 되어 치우침이 발생했고, 이를 보정하는 작업으로 생각된다.
Q, T를 구성하는 벡터의 각 값이 확률변수 X를 따르며, 라 하자.
, 각 확률변수는 전부
그러면 의 평균과 분산은 아래와 같다.
연산 결과, 값에 따라 분산이 달라지는 문제가 발생한다. 이를 보정하기 위하여 결과값을 로 나누어 최종 결과의 분산값이 에 무관한 값 가 되도록 만든 것으로 보인다.
1.3.masking(optional)
차후 decoding 부에서, masked attention을 위한 부분으로 생각된다.
2.attention distribution(가중치) 계산
attention score을 가중치로 변환하기 위하여, softmax 연산을 실행한다. (총합이 1인 가중치 형태)
3.attention value 계산
가중치(attention distribution)과 value를 matmul하여 가중합 attention value를 최종적으로 계산한다.
Multi-Head Attention
Multi-Head Attention은 Scaled Dot-Product Attention을 포함하는 조금 더 큰 모듈이다. Scaled Dot-Product Attention에 Multi-Head 테크닉을 추가하여 보다 잘 작동하도록 만든 것이다. 입력값을 여러 개의 Linear 레이어를 통하여 여러 개의 작은 벡터들로 만들고, 각각에 대하여 Attention을 연산 후 Concat한다. 이후 한 차례의 Linear 레이어를 다시 거친 뒤 output을 만든다. 이를 식으로 표현하면 아래와 같다.

Attention의 사용방식
전체 구조에서는 크게 2가지의 방식으로 Attention을 이용하였다.
- Self-Attention
Self attention은 Query, Key, Value의 값이 동일하게 입력된 attention을 말하며, 스스로에 대한 attention을 계산하기에 self-attention이라 부른다. 예를 들면, “Petter is going to bookstore, cause he want to buy textbook.”과 같은 문장에서, Petter과 he는 같은 것을 의미하므로 높은 attention이 나와야 한다. encoder, decoder 모듈의 각 첫 번째 attention이 이와 같다.
decoder 모듈에는 Masked Multi-Head attention이라는 이름으로 사용되고 있는데, 이는 학습 시 사용되는 Teacher Forcing을 적용하기 위한 방식으로 후에 설명할 것이다. - encoder-decoder attention
decoder의 두 번째 attention은 query는 decoder에서, key와 value는 encoder에서 가져와 사용한다. 이는 논문에서 encoder-decoder attention이라 부른다.(cross attention이라고도 한다.) decoder가 현재 단어를 예측하기 위하여, 현재 진행중인 query에 대하여 encoder이 어떠한 영향을 미칠 것인가를 연산한다. 이는 기존의 seq2seq 모델에서 사용한 attention과 동일하다.
Masked Multi-Head Attention
기본적으로, Seq2Seq 모델을 일련의 단어열을 입력받고, 일련의 단어열을 '순차적으로' 예측하는 방식이다. 먼저 input을 encoder에 입력받은 뒤, decoder에서 첫 번째 단어를 예측하고, 이후 이를 다시 decoder의 입력으로 삼아 두 번째 단어를 예측한다. 이후 다시 n-1번째 단어를 입력받아 n번째 단어를 예측하는 방식이다.
그런데, training 과정에서 이러한 방식에 문제가 발생한다. 초기에는 학습이 잘 되어 있지 않기에 decoder이 잘못된 단어를 예측할 가능성이 높다. 그러면 두 번째 단어는 잘못된 첫 번째 단어를 기반으로 예측되었기에 더욱 이상한 단어가 예측되고, 이러한 오류는 계속해서 커져 정상적인 학습이 일어나지 않게 된다.
이를 예방하는 기법으로 Teacher Forcing 기법이 있다. decoder에서 예측한 단어와 관계없이, 다음 단어를 예측하기 위해서는 이전 단어의 answer을 입력하는 것이다. 입력값은 항상 정답이 입력되기에, 초기 학습을 보정하여 정상적으로 학습을 진행할 수 있다.
이러한 기본 골자는 Transformer에서도 같으며, 따라서 Transformer에서도 Teacher Focing을 적용해야 한다. 그런데, 기존의 Seq2Seq이 Sequence를 순차적으로 입력받은데 비해, Transformer은 self-attention을 위하여 Sequence를 한번에 입력받는다. 만약 Teacher Forcing처럼 answer을 입력으로 줄 경우, answer이 정답을 유추하는 데 영향을 미치게 된다. 이 때문에 N번째 단어를 유추할 때 N-1번째 단어까지만 보여주고, 그 이후의 모든 단어를 masking하여 training한다. 이 때문에 Decoder에서는 단순한 multi-head attention이 아니라 masked multi-head attention 구조를 사용한다.
Positional Encoding
Attention 모델의 특성상, 입력 순서에 대한 정보가 손실되기 쉽다. 이를 보정하고자 위치 정보를 가진 벡터를 추가한다. 논문에서는 삼각함수를 이용하여 이러한 정보를 추가하였다.
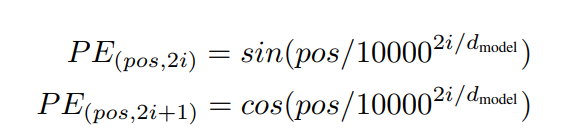
참조자료
어텐션 메커니즘 (Attention Mechanism) : Seq2Seq 모델에서 Transformer 모델로 가기까지
[NLP 논문 구현] pytorch로 구현하는 Transformer (Attention is All You Need)
Positional Encoding vs. Positional Embedding
