1. Functional Dependency
1) 개념
Functional Dependency란, 어떠한 값을 통해 종속 관계에 있는 다른 값을 유일하게 결정할 수 있음을 의미하는 것으로, 좋은 테이블 설계에 대한 정형적 기준이 된다. 마치 함수에서 하나의 x에 대응하는 y가 유일하게 결정되어야 한다는 이치와 비슷하기 때문에, 함수적 종속이라는 이름으로 불리게 되었다.
간단한 예시로, 나이와 생년월일 필드의 관계를 생각해볼 수 있다. 생년월일 필드의 값으로 나이가 결정되기 때문에 나이 필드는 생년월일 필드에 functional dependent하다. 이것은 기호로 "생년월일 → 나이"로 표기되며, 이 때의 생년월일을 Determinant(결정자), 나이를 Dependent(종속자)라고 말한다.
조금 더 실제와 가까운 예시를 들어보면 아래와 같다.
① SSN → Name
- 주민등록번호는 사원의 이름을 결정한다.
② Pnumber → {Pname, Plocation}
- 프로젝트 번호는 프로젝트 이름과 위치를 결정한다.
③ {SSN, Pnumber} → Hours
- 주민등록번호와 프로젝트 번호는 사원이 해당 프로젝트를 위해 근무한 시간을 결정한다.
2) 종류
① Full Functional Dependency(완전 함수 종속)
- 단일 기본키: Dependent가 기본키에만 종속되는 경우
→ "학번(pk) / 이름, 학년, 성별, 학과명"으로 구성된 테이블에서 학번 필드가 이름, 학년, 성별, 학과명을 모두 결정하기 때문에 이를 완전 함수 종속 관계라고 말한다. - 복합 기본키: Dependent가 기본키를 구성하는 모든 속성에 대해 종속되는 경우
→ "학번(pk), 과목번호(pk) / 성적"으로 구성된 테이블에서 학번, 과목번호 필드가 성적을 결정하고, 학번 또는 과목번호만으로는 성적을 결정할 수 없기 때문에 이를 완전 함수 종속 관계라고 말한다.
② Partial Functional Dependency(부분 함수 종속)
- 단일 기본키: 부분 함수 종속이 발생하지 않는다.
- 복합 기본키: 기본키를 구성하는 속성 중 일부에만 종속되는 경우
→ "학번(pk), 과목번호(pk) / 학년, 성적"으로 구성된 테이블에서 학년은 학번에만 종속되기 때문에 이를 부분 함수 종속 관계라고 한다. (이 때, 성적은 완전 함수 종속 관계가 됨)
③ Transitive Functional Dependency(이행적 함수 종속)
- 테이블에서 X, Y, Z라는 3개의 속성에 대해 X→Y, Y→Z라는 종속 관계가 있을 때, X→Z가 성립하게 되는 것을 이행적 함수 종속이라고 한다.
- 즉, X를 알면 Y를 알고 이를 통해 Z를 알 수 있다는 것이다.
→ "상품코드(pk) / 상품명, 서브 카테고리(ex: 상의), 메인 카테고리(ex: 의류)"로 구성된 테이블에서 상품코드를 알면 서브 카테고리를 알 수 있고, 서브 카테고리를 알면 메인 카테고리를 알아낼 수 있다.
④ Determinant Functional Dependency(결정자 함수 종속)
- 후보 키가 아님에도, Determinant가 되는 요소가 존재하는 경우를 결정자 함수 종속이라고 한다.
→ "학번, 과목, 교수"로 구성된 수강 과목 테이블에서 교수는 후보키가 아님에도, 과목을 결정하고 있기 때문에, 이를 결정자 함수 종속 관계라고 한다.- 기본키 : {학번, 과목}
- 후보키 : {학번, 과목}, {학번, 교수}
- FD: {학번, 과목} → 교수, 교수 → 과목
2. Normalization
1) 개념
관계형 데이터베이스의 설계에서 중복된 데이터가 최소화되도록 데이터베이스의 구조를 결정하는 것을 Normalization(정규화)이라고 한다. 다시 말해 서로 독립적인 관계는 별도의 테이블로 분해한다는 것이다. 당연히 정규화된 데이터베이스는 그렇지 않은 데이터베이스에 비해 더 효율적으로 연산을 수행한다.
데이터베이스의 Normalization 과정에서 Functional Dependency의 개념이 사용된다. 우리는 효율적인 데이터베이스를 설계하기 위해 Table에 오직 하나의 Funtional Dependency만 존재하도록 Normalization을 진행해야 한다.
2) 종류
① 1NF(1st normal form)
- 모든 attribute는 atomic value(복합 속성, 다치 속성, 중첩 테이블을 허용하지 않음)만 가져야 한다.
- 정규화라기 보단, 너무나도 당연한 내용이다.
② 2NF(2nd normal form)
- Partial Functional Dependency를 제거한다.
- pk에 의해 모든 attribute가 결정되면, 2NF를 만족한다.
- pk에 의해 모든 attribute가 결정되지 않는다면, partial FD를 별도의 테이블로 분리해야 한다.
- 기본키가 단일 속성으로 구성된 경우, 제 2정규화를 생략할 수 있다.
③ 3NF(3rd normal form)
- Transitive Functional Dependency를 제거한다.
- 모든 attribute가 기본키에 대해 이행적으로 종속되지 않으면 3NF를 만족한다.
④ BCNF(Boyce-Codd normal form)
- Determinant Functional Dependency를 제거한다.
- Determinant를 결정하는 Dependent 요소를 별도의 테이블로 분리한다.
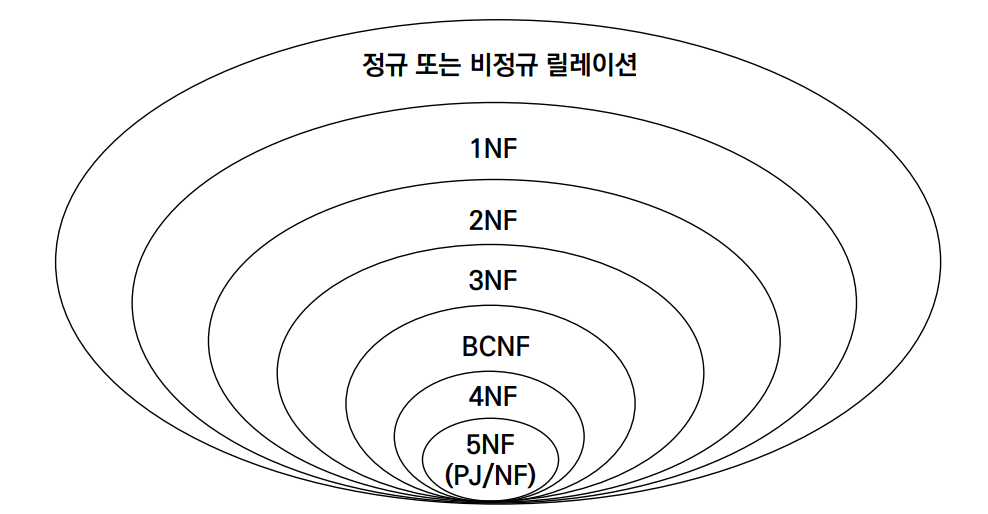
물론, 제 4정규형과 제 5정규형도 존재는 하지만, 별로 실용적이지 않기 때문에 다루지 않을 것이다. 다만 제 4정규형은 Multi-valued Dependency 제거와, 제 5정규형은 Join Dependency 제거와 관련한다는 사실만 알아두자.
3) 예시
한 테이블에 FD가 하나만 존재해야 하는 이유에 대해 명확한 예시를 통해 알아보기로 하자.
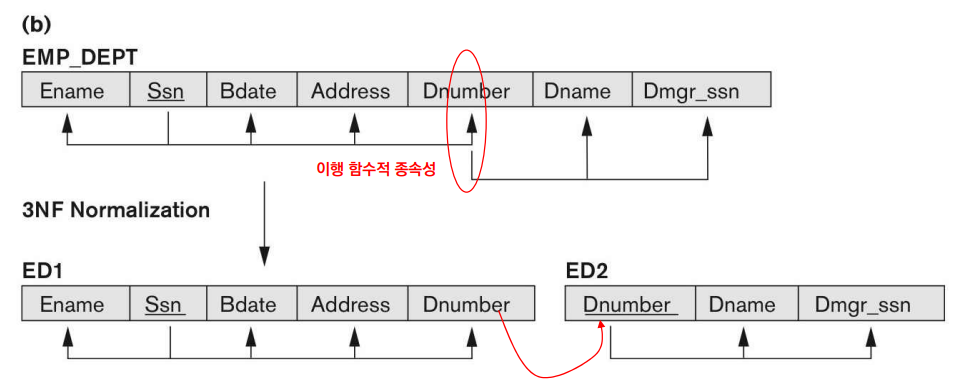
① Employee와 Department에 대한 정보를 하나의 테이블에 표시한 경우

- Ssn 필드는 Employee를 유일하게 결정할 수 있는 필드이고, Dnumber 필드는 Department를 유일하게 결정할 수 있는 필드이다.
- Ssn 필드가 사원의 정보인 {Ename, Bdate, Address, Dnumber}를 결정하고, Dnumber 필드가 부서의 {Dname, Dmgr_ssn}을 결정하므로, Transitive FD에 의해 Full FD가 성립한다.
- 즉, 위 예시는 2NF는 만족하되 3NF는 만족하지 않으므로, 제 3정규화를 진행해야 한다.
- 3NF를 만족시키기 위해선 주어진 테이블을 {Ssn, Ename, Bdate, Address, Dnumber}, {Dnumber, Dname, Dmgr_ssn}으로 분해해야 한다.
② Employee와 Project에 대한 정보를 하나의 테이블에 표시한 경우
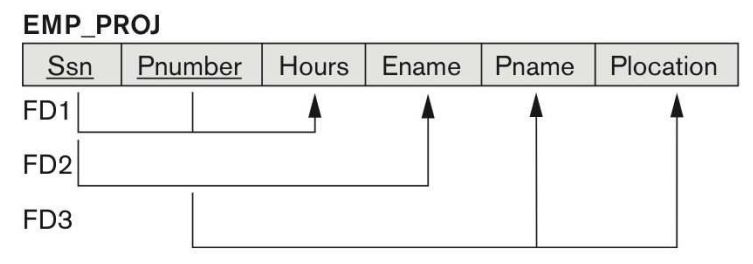
- {Ssn, Pnumber}는 hours 필드를, Ssn 필드는 Ename 필드를, Pnumber 필드는 {Pname, Plocation}을 결정한다.
- 기본키의 일부에만 종속되는 attribute가 존재하므로 1NF는 만족하되, 2NF는 만족하지 않는다.
4) 필요성
오직 하나의 Funtional Dependency만 Table에 존재하도록 Normalization을 진행해야 한다고 했는데, 만약 2개 이상의 FD가 존재하는 상태로 Table을 방치하면 어떻게 될까?
위와 같이 하나의 테이블에 두 개 이상의 Entity의 속성이 혼합되는 경우, 아래와 같은 문제를 유발할 수 있다.
- 데이터 중복으로 인해 저장공간이 낭비된다.
- Anomaly가 발생해 정확한 데이터를 알 수 없게 된다.
5) Anomaly
아래의 수강 테이블에서 발생할 수 있는 Anomaly에 대해 알아보자.

① Insertion Anomalies(삽입 이상)
- 600번 학생이 2학년이라는 정보를 삽입할 때, 수강 중인 과목이 없으면 삽입이 불가능하다.
- constraints를 만족시키기 위해 원치 않는 정보를 강제로 삽입해야 할 수 있다.
② Deletion Anomalies(삭제 이상)
- 200번 학생이 'C123' 과목 수강을 포기할 경우 3학년이라는 정보도 함께 삭제된다.
③ Modification Anomalies(수정 이상)
- 400번 학생의 학년을 4에서 3으로 변경하려면, 학번이 400인 4개의 튜플을 모두 갱신해야 한다.
이와 같은 상황을 방지하기 위해선, attribute 간의 종속 관계를 분석하여 여러 개의 테이블로 분해하는 Normalization 과정이 필요하다.
6) Lossless Join
Normalization을 위해 테이블을 분해하는 과정에서 Lossless Join 조건을 반드시 만족해야 한다. 이는 원래 테이블에서 분해된 여러 개의 테이블을 다시 join 했을 때, 원래의 테이블을 복원할 수 있어야 함을 의미한다. (사실 너무나 당연한 내용이다.)
Lossless Join 조건을 만족하지 않으면 join 연산을 수행할 때 원래 테이블에는 존재하지 않았던 Spurious(가짜) Tuple이 생길 수 있다(진짜 튜플과 구별하기 어려울 수도 있다). 따라서 테이블을 분해할 때에는 {기본키, 외래키}의 조합을 활용해야 한다.
3. 제 1 정규화
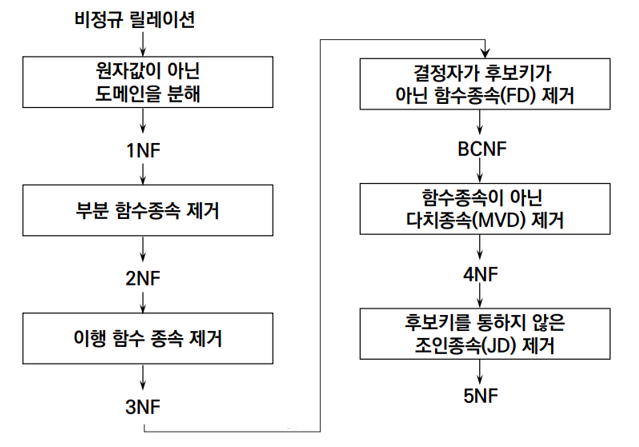
1NF를 만족하기 위해서는 테이블의 모든 attribute가 오직 atomic value만 가져야 한다. 따라서 복합 속성, 다치 속성, 중첩 테이블과 같은 non-atomic value는 허용되지 않는다.
1) 다치 속성을 갖는 경우
아래는 다치 속성을 갖는 테이블의 예시이다.
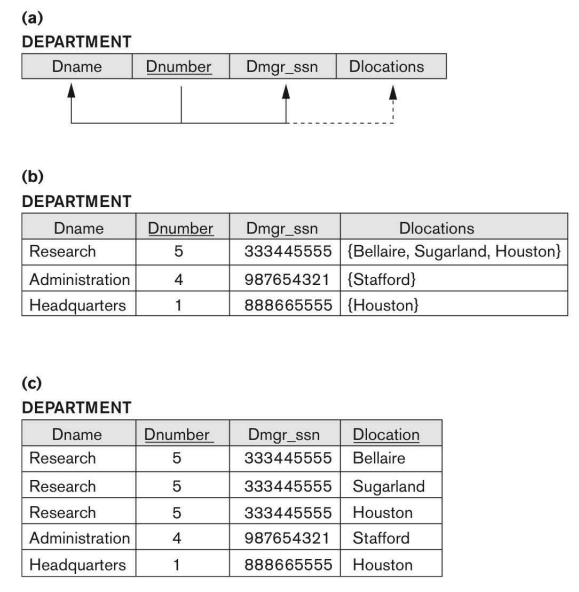
(a)와 (b)가 1NF를 만족하지 않는 이유는 Dlocation 필드가 다치 속성이기 때문이다. 이 테이블이 1NF를 만족하기 위해서는, 다치 속성을 각각의 튜플로 분리해야 한다. 이 과정을 가리켜 제 1 정규화라 하며, 그 결과는 (c)가 된다.
2) 중첩 테이블인 경우
이번에는 아래의 중첩 테이블을 정규화하는 과정에 대해 알아보자. 아래는 Emp_Proj라는 메인 테이블 안에 Projs라는 서브 테이블이 중첩되어있는 형태이다.

위 테이블이 1NF를 만족하지 않는 이유는 다대다 관계를 가져야 할 테이블들이 하나의 테이블 안에 중첩되면서 redundancy가 발생하기 때문이다.
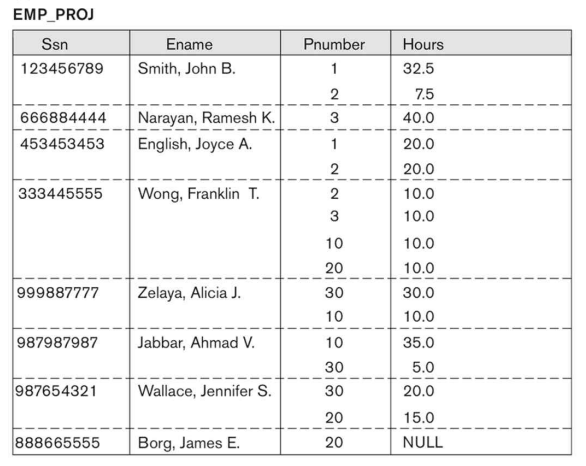
이처럼 한 사람이 여러 프로젝트에 참여하는 경우 데이터 중복이 심하게 발생하게 된다. 따라서 테이블을 아래와 같이 분해해야 한다.
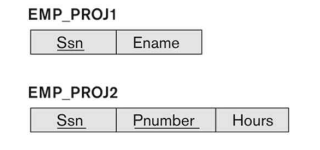
여기서 테이블이 분해되더라도 기본키는 그대로인 것을 확인할 수 있는데, 이를 primary key propagation(key attribute를 제외하고는 redundancy가 없어야 함)이라 한다.
이와 같이 중첩 테이블은 중첩된 테이블을 분리하는 방식으로 1NF를 만족시킬 수 있다.
4. 제 2 정규화
1) 필요성
1NF를 만족하는 테이블에서는 더 이상 non-atomic value가 존재하지 않지만, 여전히 Anomaly는 발생한다. 대표적으로 아래와 같은 경우이다.
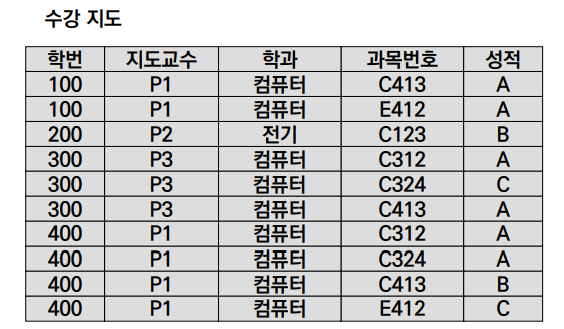
① Insertion Anomaly
- 500번 학생의 지도교수가 P4라는 사실의 삽입은 교과목을 등록하지 않는 한 불가능하다.
② Deletion Anomaly
- 200번 학생이 'C123' 과목 수강을 포기할 경우, 지도교수가 P2라는 정보까지 손실된다.
③ Modification Anmaly
- 400번 학생의 지도교수를 P1에서 P3로 변경할 경우 학번이 400인 4개의 튜플의 지도교수 값을 모두 P3로 변경해야 한다.
분명 1NF를 만족함에도 불구하고 Anomaly가 발생하고 있는데, 이는 Partial FD가 존재하기 때문이다.
- 기본키: {학번, 과목번호} → 성적
- 기본 키의 일부: 학번 → {지도 교수, 학과}
- 기본키가 아님: 지도 교수 → 학과
1NF의 Partial FD를 제거하여 2NF로 만들면, Anomaly를 어느 정도 해결할 수 있게 된다.
2) 정규화 과정
아래의 1NF 테이블을 2NF를 만족하도록 정규화해보자.
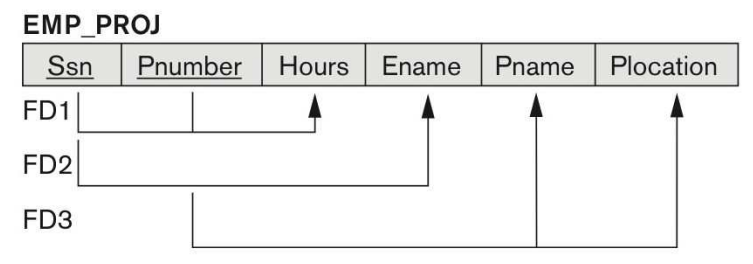
① FD1은 완전 함수 종속 관계이다.
- {Ssn, Pnumber} → Hours
② FD2, FD3는 부분 함수 종속 관계이다.
- Ssn → Ename
- Pnumber → Pname, Plocation
③ 테이블이 Full FD를 만족하도록 아래와 같이 분해한다.
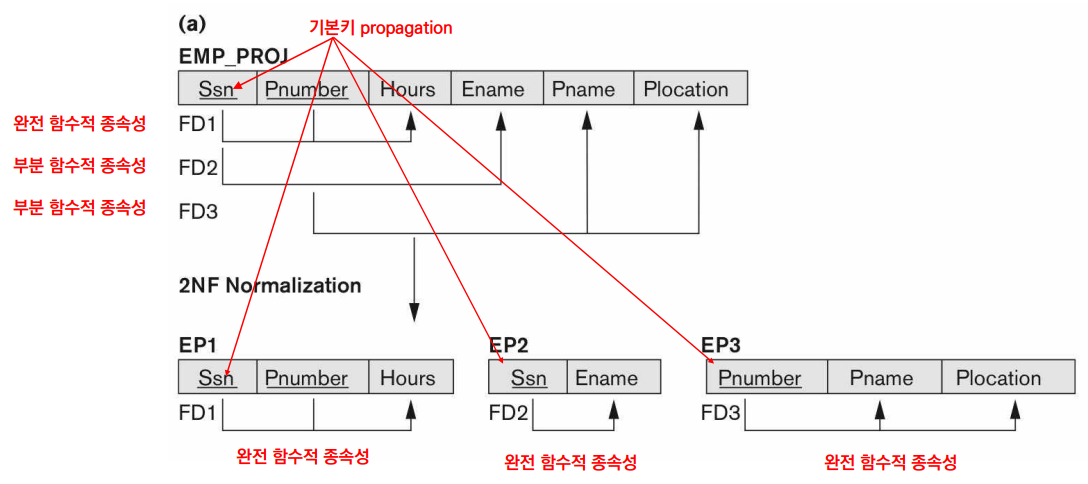
이처럼 1NF를 만족하면서 Full FD로만 구성된 테이블은 2NF를 만족한다.
5. 제 3 정규화
1) 필요성
2NF를 만족하는 테이블에서도 Anomaly가 여전히 발생한다.
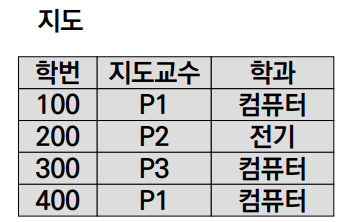
① Insertion Anomaly
- 지도교수의 지도를 받는 학생이 존재하지 않을 경우, 어떤 지도교수가 특정 학과에 소속되어있다는 사실을 삽입할 수 없다.
② Deletion Anomaly
- 300번 학생의 튜플을 삭제하면 지도교수 P3가 컴퓨터공학과 소속이라는 사실도 삭제된다.
③ Modification Anomaly
- 지도교수 P1의 소속이 전자과로 변경된다면, 1번과 4번 튜플을 모두 변경해야 한다.
2NF를 만족함에도 불구하고 Anomaly가 발생하는 이유는 Transitive FD가 존재하기 때문이다.
- 학번 → {지도교수, 학과}이므로 2NF를 만족한다.
- 그러나 학번을 알면 지도교수를 알 수 있고, 지도교수를 알면 학과를 알 수 있다는 점에서 Transitive FD가 발생한다.
2NF의 Transitive FD를 제거하여 3NF로 만들면, Anomaly를 어느 정도 해결할 수 있게 된다.
2) 정규화 과정
위 테이블을 3NF를 만족하도록 정규화해보자. 3NF를 만족하려면 학번 → 지도교수 → 학과의 이행적 종속을 끊어야 한다.
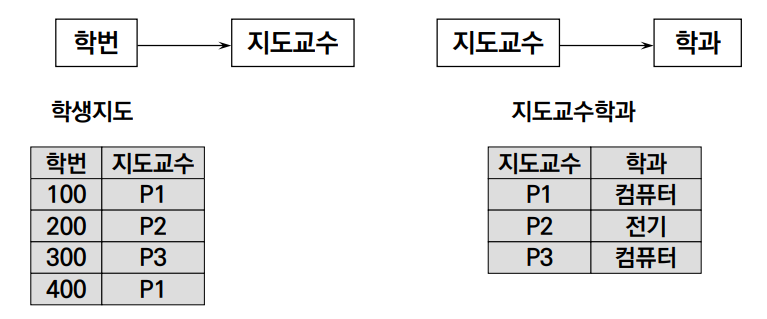
① 이행적 종속을 끊는 방법은 Determinent를 pk로 사용하고, Dependent이면서 Determinent인 요소를 fk, pk로 사용하는 것이다.
② {학번(pk) / 지도교수(fk)}, {지도교수(pk) / 학과}와 같이 분해하면 이행적 종속이 끊어진다.
6. Boyce-Codd 정규화
1) 필요성
제 3 정규화까지 진행한 테이블에선 거의 Anomaly가 발생하지 않는다. 그럼에도 간혹 Anomaly가 발생할 수도 있다.
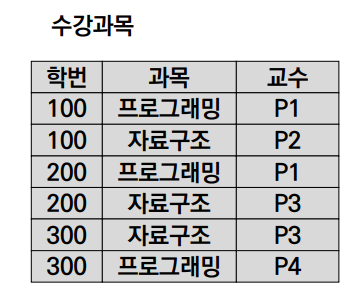
① Insertion Anomaly
- 교수 P5가 자료구조를 담당하는 사실의 삽입은 수강 학생이 있을 때에만 가능하다.
② Deletion Anomaly
- 100번 학생이 자료구조 수강을 취소하여 튜플을 삭제하면 P2가 담당 교수라는 사실도 삭제된다.
③ Modification Anmaly
- P1이 프로그래밍 대신 자료구조를 담당하게 되면 P1이 담당하는 모든 과목에 대한 튜플을 변경해야 한다.
3NF를 만족함에도 불구하고 Anomaly가 발생하는 이유는 Determinant FD가 존재하기 때문이다.
- {학번, 과목} → 교수이므로 2NF를 만족하고, 이행적 종속도 없으므로 3NF도 만족한다.
- 그러나 후보키가 될 수 없는 교수가 과목을 결정할 수 있다는 점에서 Determinant FD가 발생한다.
3NF의 Determinant FD를 제거하여 BCNF으로 만들면, Anomaly를 어느 정도 해결할 수 있게 된다.
2) 정규화 과정
위 테이블을 BCNF를 만족하도록 정규화해보자. BCNF를 만족하려면, 후보키가 아닌 Determinent를 pk와 fk로 사용해야 한다.
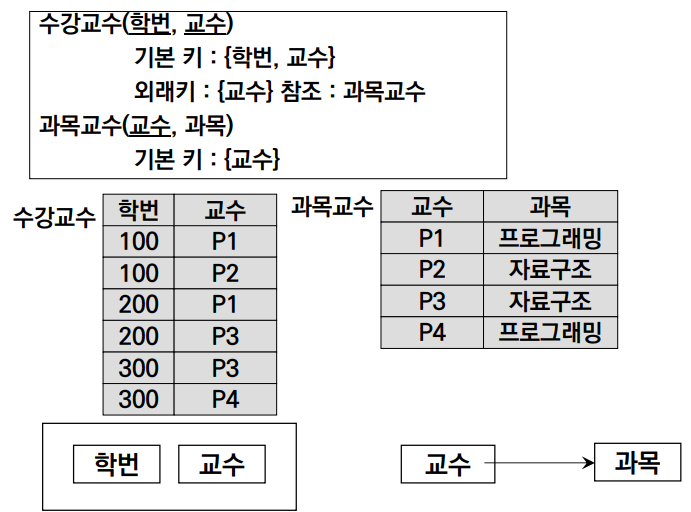
① 후보키가 아님에도 과목을 결정했던 교수를, pk로 하는 과목 교수 테이블을 만든다.
② 이후 학번과 교수를 복합 기본키로 하는 수강 교수 테이블을 만든다.
③ 이제 더 이상 후보키가 아닌 Determinent가 존재하지 않게 된다.
7. 정규화 Review
1) ERD의 정규화 분석
① 1NF를 만족하고 있는지 확인
- 중복된(모든 Column이 동일한) 행이 없고, 모든 속성이 atomic value이다.
- ERD에 있는 모든 Entity가 PK를 갖는지 확인한다.
② 2NF를 만족하고 있는지 확인
- Partial FD를 제거한다.
- PK가 단일 속성으로만 구성된 경우에는, 항상 2NF를 만족한다.
- PK가 복합 기본키인 경우, PK 속성의 일부가 나머지 속성들과 종속 관계를 갖는지 확인해야 한다.
③ 3NF를 만족하고 있는지 확인
- Transitive FD를 제거한다.
- PK가 아닌 속성들 중에 종속 관계가 존재하는지 확인한다.
2) 시험 문제 출제 유형
① 정규화를 만족하지 않는 테이블에 대하여..
- FD를 찾아내는 문제
- 몇번째 정규형을 위반하고 있는지 찾아내는 문제
- 정규형을 만족하도록 정규화(몇번째 정규화까지 진행해야 하는지를 알아내는 것이 중요)하는 문제
② 주어진 Requirement를 분석하여 FD를 직접 찾아내는 문제