데이터베이스설계
1.1주차. Database and DBMS

이번 시리즈는 인하대학교 정보통신공학과에 개설된 강의인 "데이터베이스설계"라는 과목에 대한 포스팅입니다. 강의 내용이 백엔드 개발에 있어서도 많은 도움이 될 거 같아 포스팅으로 정리해보게 되었습니다.데이터베이스의 내의 데이터 저장 구조가 변경되어도 데이터베이스에 대한
2.1주차 실습. 개발환경 구축

1. NVM & Node 설치하기 아래의 링크에서 가장 최신 버전(작성일 기준 1.1.11)의 nvm-setup.zip 파일을 다운로드한다. >> NVM & Node 설치하기 다운로드받은 zip 파일을 열어 nvm.set-up.exe 파일을 실행한다. I accept
3.2주차. Concepts and Architecture of DBMS
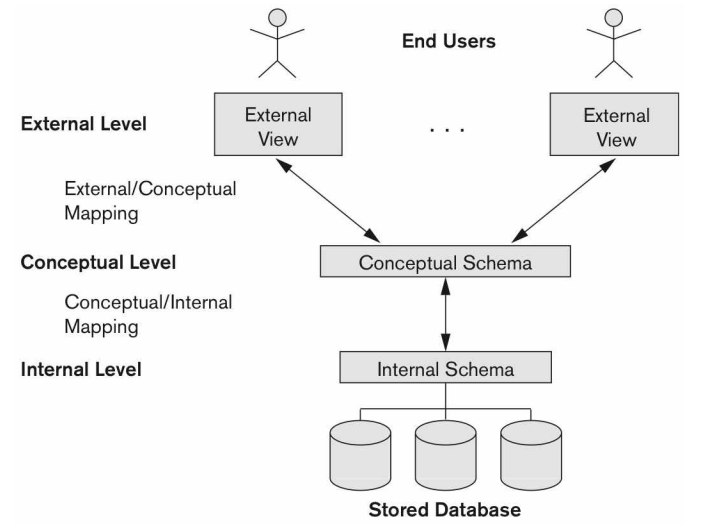
① 데이터 모델데이터의 세부 사항은 은닉하고 필요한 개념만 제공(데이터 추상화)하기 위해 사용한다.데이터 추상화는 feature extraction 과정을 포함하는데, 이 과정은 나중에 스키마를 구성하기 위해 필요하다.데이터의 타입, 관계, 제약조건을 명시하기 위해 사
4.2주차 실습. HTML, CSS, JavaScript
자기소개 페이지의 레이아웃은 header-footer, navigation bar, section을 사용하여 구성할 것이다.저번 포스팅에서 생성한 Database 폴더 하위로 week2 폴더를 추가한다. 그리고 VSCode를 실행하여 week2를 연다. 먼저 아래의 사
5.3주차. Entity-Relationship Model
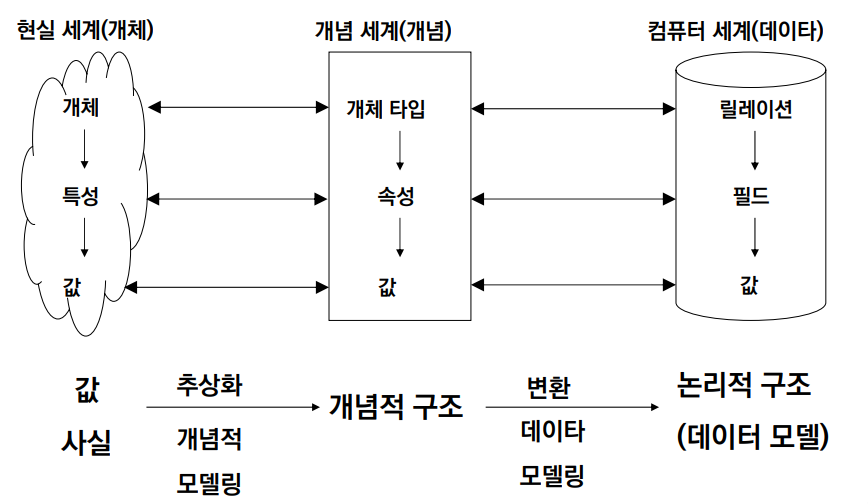
Real World의 Entity에는 Feature와 이에 해당하는 Value가 존재한다. 이들은 Comceptual World에서 각각 Entity Type과 Attribute, Instance로 매핑되고, Mini-World에서는 (MySQL을 기준으로) Tabl
6.3주차 실습. DB 구축 & SQL Query

아래와 같은 데이터베이스를 구축해보기로 하자.① cmd를 열고 아래의 명령을 입력한다.② 본인이 설정한 password를 입력한다.Can't connect to MySQL server on localhost라고 나오면 작업 관리자 > 서비스에서 MySQL80을 시작시켜
7.4주차. ERD Notation in MySQL and EERD
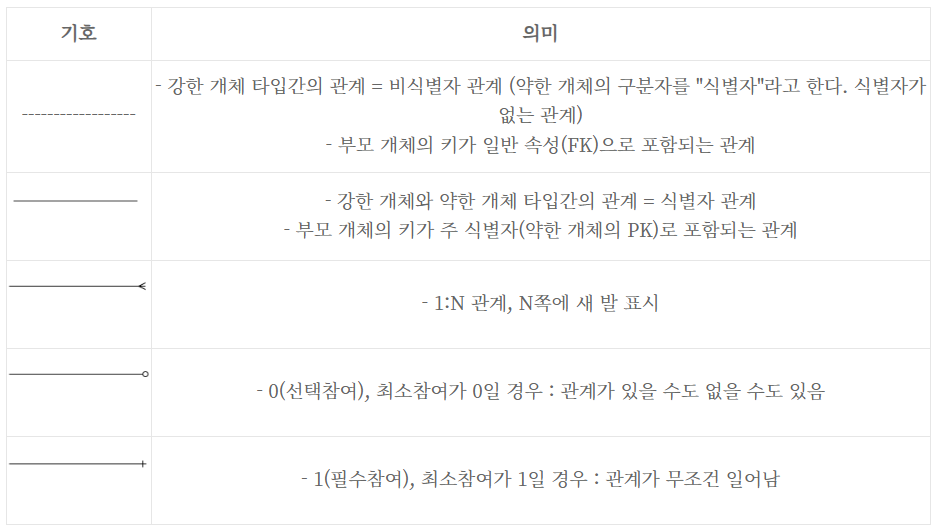
ERD의 표기법은 매우 다양하기 때문에 모두 다루기도 어렵고 알기도 어렵다. 그래서 가장 일반적이면서, MySQL에서 사용하고 있기도 한 IE 표기법에 대해 알아보기로 한다. 이전 시간에 만든 ERD에서는 마름모를 이용해 Entity간의 관계를 표시하였지만, IE 표기
8.4주차 실습. MySQL Workbench

이번 포스팅에서는 MySQL Workbench를 이용해 Inha Database를 구성해보도록 하겠습니다.① MySQL Workbench를 실행하고 Local instance MySQL80을 선택한다.비밀번호를 입력하여 로그인한다.② File > New Model을 선
9.5주차. Relational Data Model
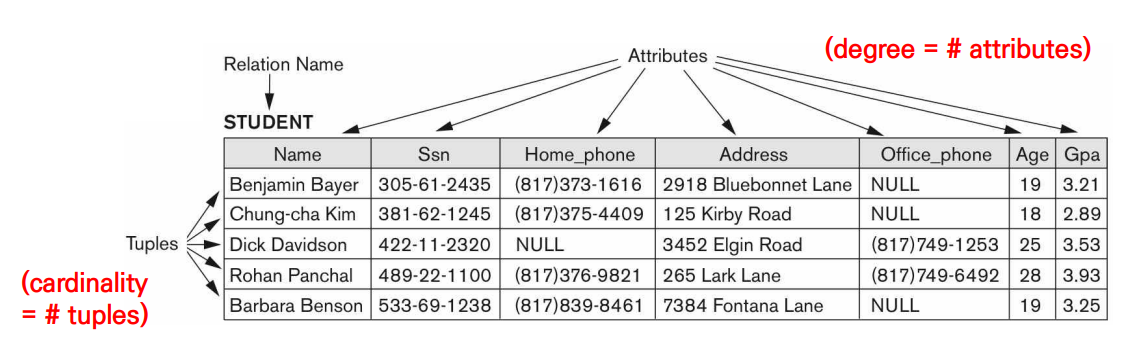
Real World에서 Row, Column, Table이라고 부르는 요소를, Relational Data Model에서는 Tuple, Attribute, Relation이라고 바꾸어 부른다. 즉, Attribute로 구성된 Tuple의 집합으로 Relation을 표현
10.5, 6주차 실습. MySQL Express 연동
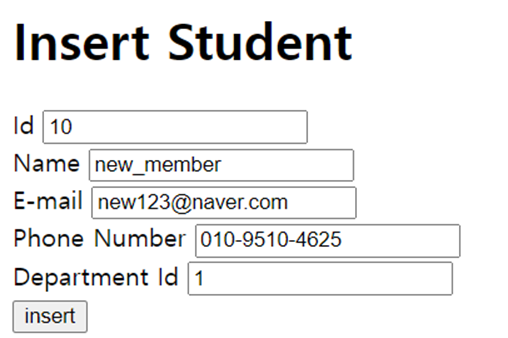
3주차 실습 포스팅에서 MySQL과 Express를 연동하는 방법에 대해 잠깐 다루었습니다. 이번 포스팅에서는 MySQL과 Express를 연동하여 실제 Query를 실행할 수 있는 웹 페이지를 만들어보도록 하겠습니다. 참고로 6주차 실습이 5주차의 내용을 확장하는 실
11.6주차. SQL 1
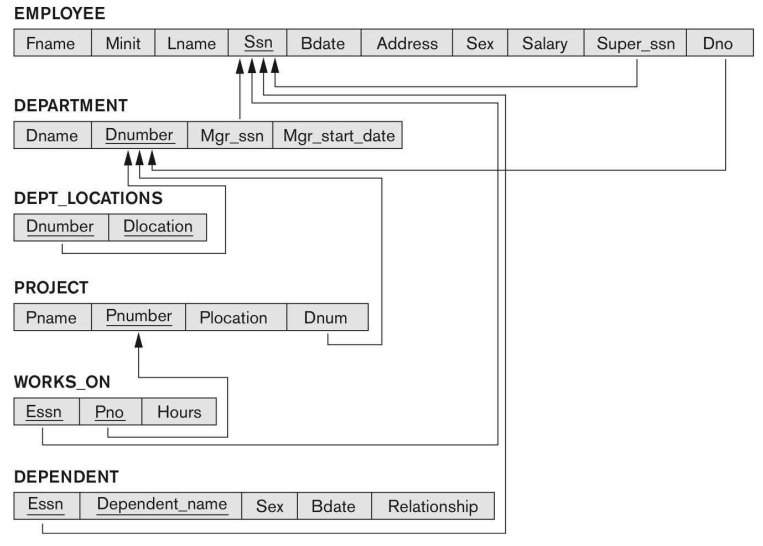
1. 개요 SQL(Structed Query Language)은 DBMS에서 자료의 검색과 관리, 데이터베이스 스키마 생성 및 수정, 데이터베이스 객체 접근 조정을 위해 사용된다. 쉽게 말해 데이터베이스 언어인 셈이다. SQL은 아래와 같이 세가지로 분류된다. 데이터
12.7주차. SQL 2
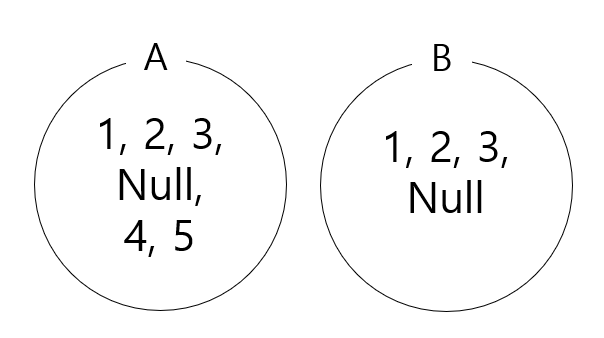
1. Null 값을 검색하는 쿼리 attribute가 null인지 검사하는 연산자는 Is Null과 Is Not Null이다. ① id가 null인 사원을 찾는 쿼리 ② 상사가 없는 모든 사원들의 이름을 검색하는 쿼리 2. Nested Query와 집합 비교 wh
13.7주차 실습. SQL 실습
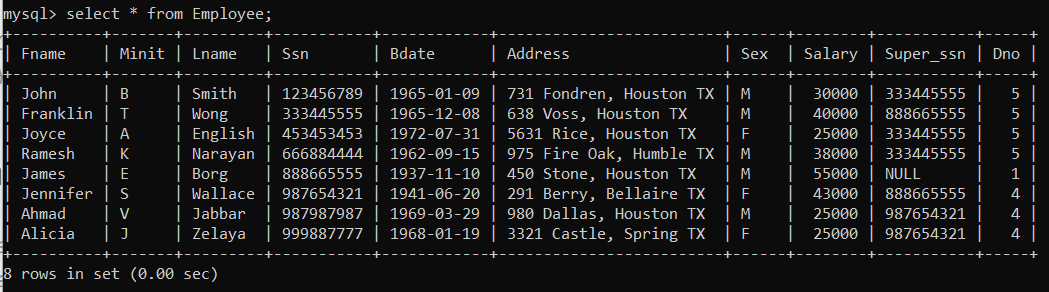
① 메모장에 아래의 내용을 입력하고 company_database.sql이라는 이름으로 working directory 하위에 저장한다.② cmd 창에 아래의 명령을 입력한다.③ select \* 또는 desc를 이용해 sql 문이 잘 적용되었는지 확인한다.아래의 데이
14.10주차 이론. Functional Dependencies and Normalization
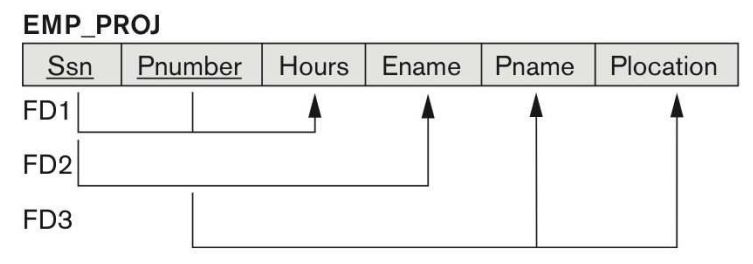
1. Functional Dependency 1) 개념 Functional Dependency란, 어떠한 값을 통해 종속 관계에 있는 다른 값을 유일하게 결정함을 의미하는 것으로, 좋은 테이블 설계에 대한 정형적 기준이 된다. 마치 함수에서 하나의 x 값에 대응하는 y
15.10주차 실습. Web Login
① 메모장을 열고, 아래의 내용을 입력한다. ② 메모장을 week10.sql이라는 이름으로 cmd의 working 디렉토리 안에 저장한다. 여기서는 바탕화면에 있는 db > Database 안에 week10을 생성하고 그 안에 week10.sql을 저장하였다. ③
16.11주차 이론. Indexing Structure
Sequential Data Structure에는 대표적으로 Array와 List가 있다. Array는 간단하지만 크기가 고정되어있다는 것이 단점이고, List는 다소 복잡하지만 크기가 동적으로 변할 수 있다는 것이 장점이다. 이러한 Sequential Data Str
17.11주차 실습. 인하대 수강신청 홈페이지 구현하기
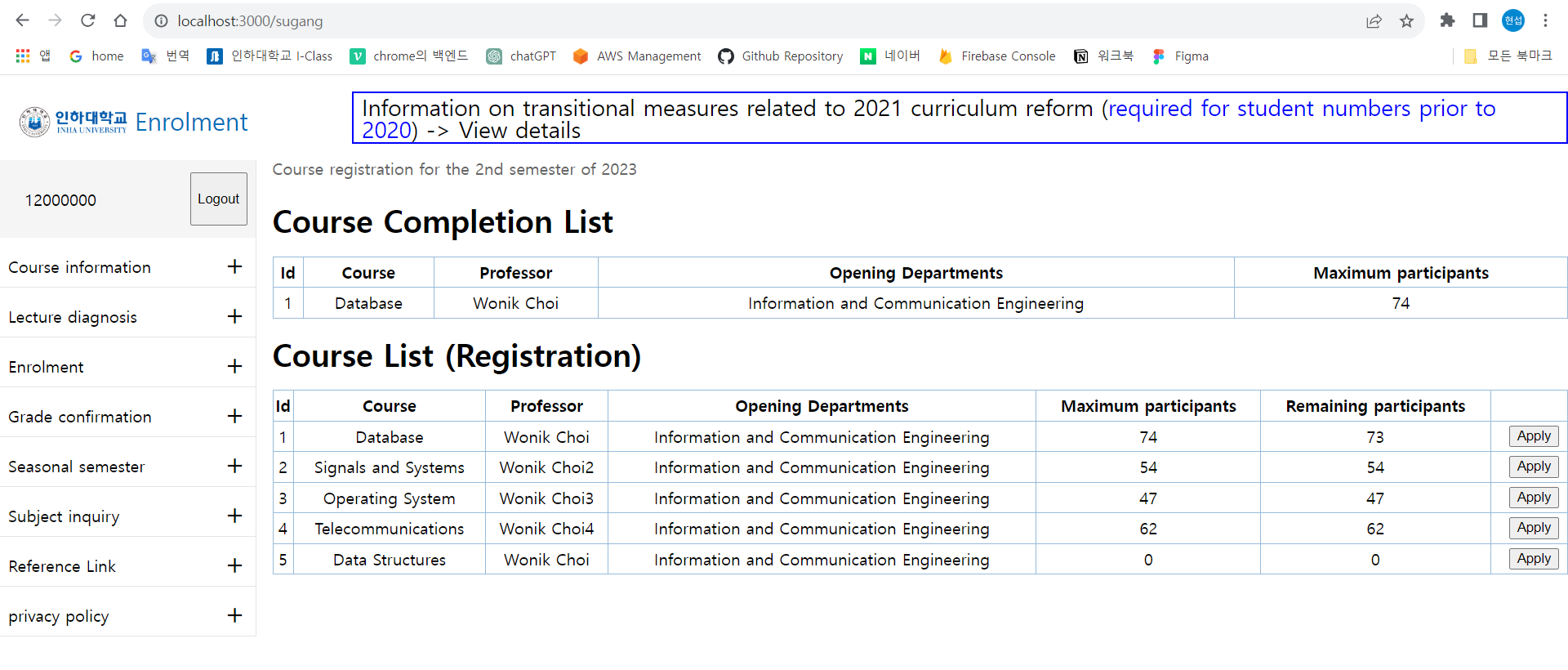
1. Cookie를 활용한 Web Login 구현하기 1) 인하대 수강신청 홈페이지 카피하기 ① 메모장을 열고, 아래의 내용을 입력한다. ② working 디렉토리 안에 week11 디렉토리를 생성한다. ③ 메모장을 week11.sql이라는 이름으로 week11 디
18.12주차 이론. Transaction Processing
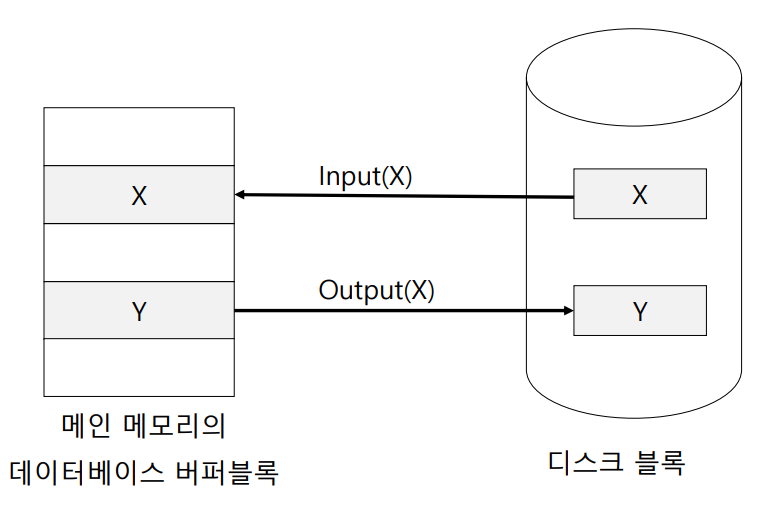
Transaction이란, 데이터베이스 작업을 수행하는 단위 프로세스로, 대표적으로 계좌이체, 좌석예약 시스템 등이 있다. 이러한 Transaction은 데이터 공유와 다수 사용자 처리를 위해 사용된다. Transaction이 적용되면 여러 명의 사용자가 동시에 동일한
19.12주차 실습. Dummy Data를 이용한 Index Performance Test
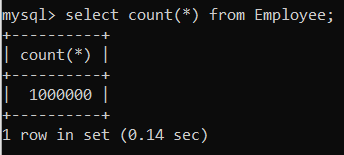
백만명의 Employee가 존재하는 테이블을 생성해보자. (sql의 길이가 길어서 sql문을 제공해주지는 않을 것이다. 아래의 Dummy Data 생성 방법에 대한 설명을 읽고 직접 만들어보기 바란다.)① million_insert_quries.sql이라는 이름으로 s
20.13주차 이론. Concurrency Control
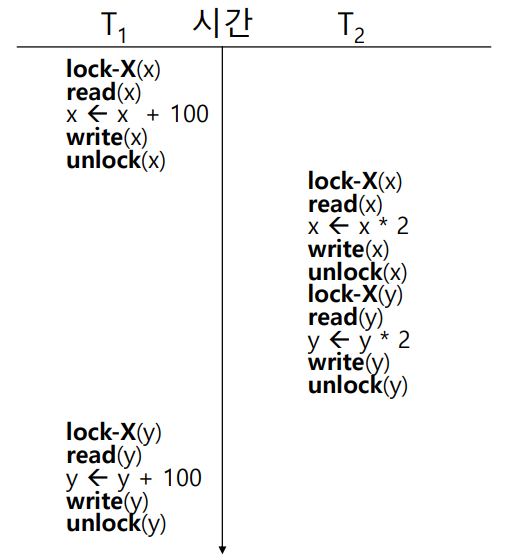
1. 동시성과 병렬성 여러 사용자가 동시에 Database를 원활하게 사용하기 위해선, Database에서 Concurrent Sharing 기능을 제공해주어야 한다. 여러 명의 사용자를 동시에 처리하기 위해 아래의 두 가지 방법을 고려해 볼 수 있다. ① Inter
21.14주차 이론. NoSQL
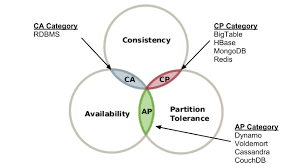
NoSQL의 해석을 둘러싸고 아래와 같은 견해가 존재한다. No SQL : 말그대로 No SQL로 SQL이 아니다.None Relational Database: 관계형 DB 모델이 아니다.Not Only SQL: SQL 뿐만이 아니다.이 중 가장 일반적인 해석은 Not
22.15주차 이론. Big Data & Data Mining
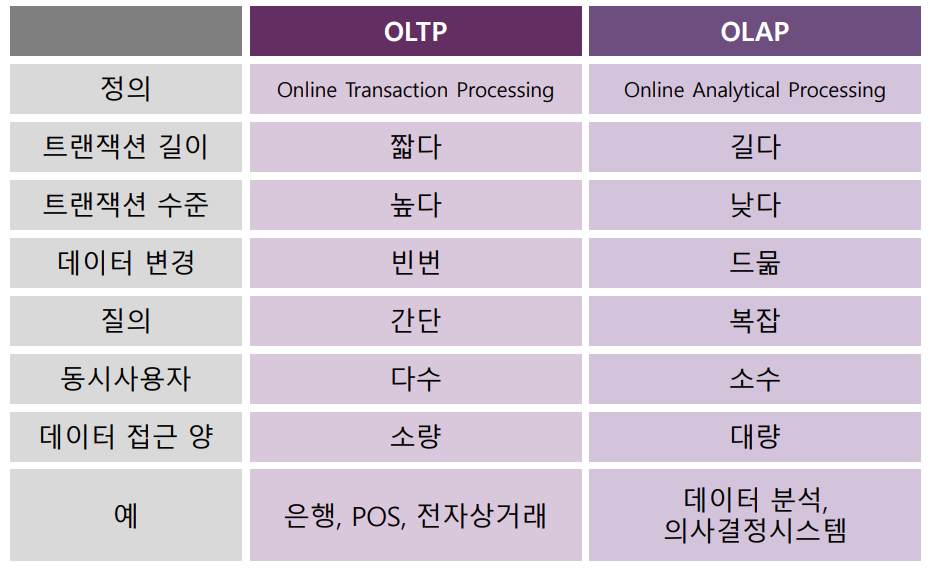
예전에는 Big Data의 핵심 속성을 3Vs라고 불렀다.Volume: 데이터의 크기Velocity: 데이터의 생성 및 처리 속도Variety: 데이터의 다양성그러나 나중에 아래의 2가지 속성이 추가되면서, 현재는 5Vs로 Big Data의 핵심 속성을 정의하고 있다.