1. MySQL의 ERD 표기법
ERD의 표기법은 매우 다양하기 때문에 모두 다루기도 어렵고 알기도 어렵다. 그래서 가장 일반적이면서, MySQL에서 사용하고 있기도 한 IE 표기법에 대해 알아보기로 한다. 이전 시간에 만든 ERD에서는 마름모를 이용해 Entity 간의 관계를 표시하였지만, IE 표기법에서는 선을 이용해 관계를 표시한다.
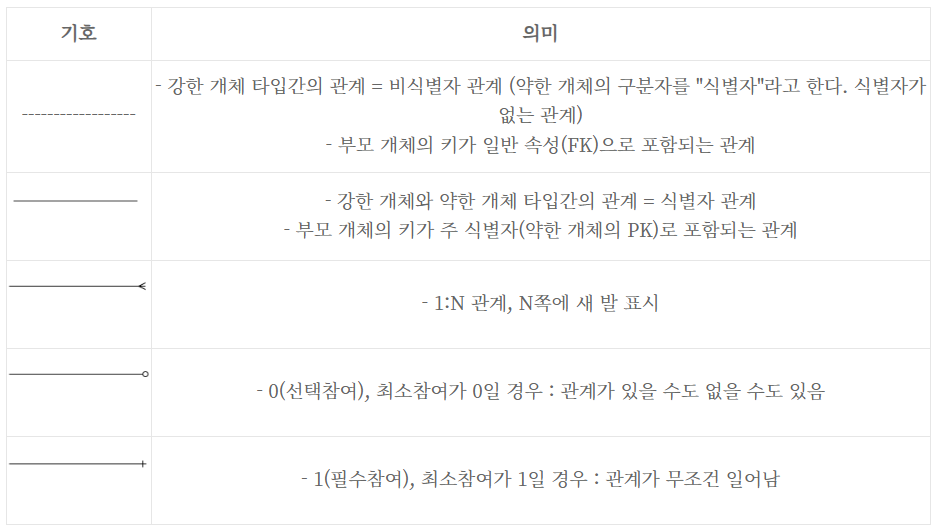
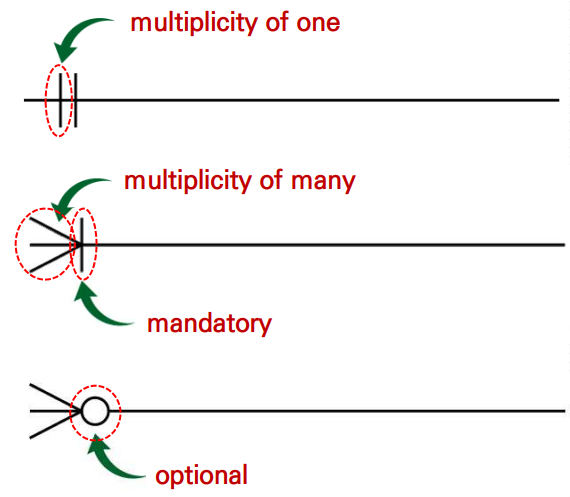
정리하자면, 테이블은 선으로 연결되며, 이 때 실선 또는 점선은 식별 관계 여부를 의미한다. 또한 연결선의 inner 부분에 | 또는 O은 필수 또는 선택을 의미하고, outer에 있는 | 또는 ∈은 각각 일대다 관계에서의 일 또는 다 테이블을 의미한다. (즉, inner의 | 와 outer의 | 의 의미가 다르다.)
실제로 Company Mini-World를 MySQL의 ERD로 나타내면 아래와 같다. (MySQL에서 ERD를 작성하는 방법은 실습에서 자세히 다루기로 하자.)
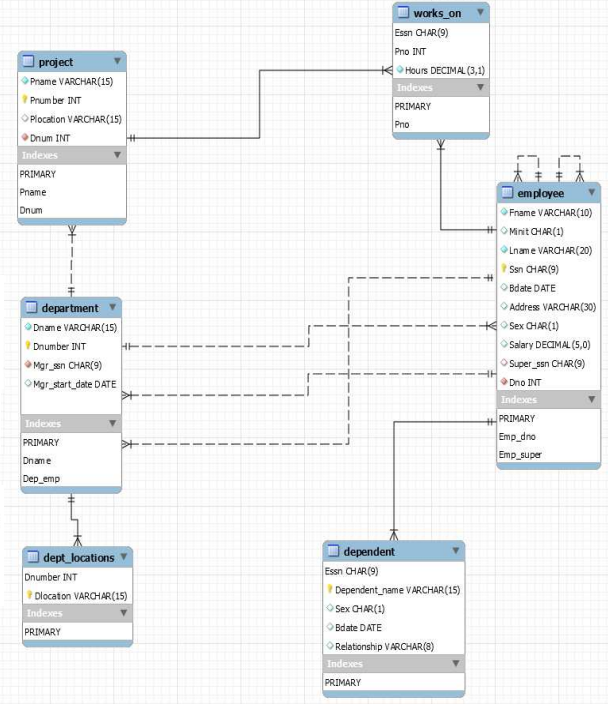
Conceptual Design에 사용된 ERD(이전 시간에 만든 ERD)와는 약간 다른 부분이 존재하는데, 그 중에서도 가장 두드러지는 부분은 식별 및 비식별 관계이다. 이전 ERD에서는 Employee와 Dependent만이 식별 관계였으나, 여기서는 Department-Dept_Location, Project-Works_on-Employee가 모두 식별 관계로 구현되었다. 이유가 무엇일까?
식별 관계는 부모 테이블과, 부모의 pk를 절대적으로 필요로 하는 테이블 간의 관계이다. 먼저, Department-Dept_Location의 관계를 생각해보자. Department의 pk가 없는 Dept_Location은 존재할 수 없기 때문에 이는 식별 관계이다. 또한 Project-Works_on-Employee의 관계에서, Works_on은 Project와 Employee의 pk를 관리하는 연결 테이블이며, 두 테이블의 pk 중 하나라도 없는 경우 존재할 수 없기 때문에 Works_on도 Project, Employee와 식별 관계를 맺는다.
이전 ERD에서는 Dept_Location이 Multivalued Attribute로 Department Entity에 포함되어 있었고, Works_on은 Entity가 아닌 Relationship이었기 때문에 식별 관계로 표시하지 않았던 것이다.
2. EERD
EERD는 Enhanced ERD 또는 Extended ERD로, ERD에 추가적인 개념을 도입한 것을 의미하는데, 추가적인 개념 중에서 가장 중요한 것은 Super Class/Sub Class, Specialization/Generalization이다.
1) Super Class/Sub Class
Entity는 의미 있는 sub group으로 나누어질 수 있다. 예를 들어, Employee는 Secretary, Engineer, Technician 등으로 세분화될 수 있다. 이렇게 세분화하는 작업을 Subgrouping이라 하고, sub group에 속하는 요소를 Subclass 또는 Subtype이라고 한다. 이 때, Employee는 Super Class(부모 클래스)가 되고, 각 Sub Class는 자식 클래스가 된다. 우리는 이를 Is-A 관계라고 말한다.
Super Class와 Sub Class 간에는 반드시 아래의 두 가지 관계 중 하나의 관계가 발생한다.
- Disjoint(d): Sub Class 간의 구분이 명확해, 반드시 하나의 Sub Class에만 속하는 경우
- Overlap(o): 여러 Sub Class에 동시에 속할 수 있는 경우
Employee를 Secretary, Engineer, Technician으로 구분할 때, 이들의 관계는 d인가 o인가? 상식적으로, 한 명의 사원이 Secretary이면서 Engineer일 수는 없기 때문에 d이다. 이번에는 사원을 Hourly_Employee와 Salaried_Employee로 구분한다고 해보자. 이 때의 관계는 d인가 o인가? 마찬가지로, (상식 선에서) 한 명의 사원이 Hourly_Employee이면서, Salaried_Employee인 경우는 없으므로 d이다. 사실 Sub Class는 명확히 구분되는 경우가 많기 때문에, 대부분 d 관계를 가지게 된다.
하지만, o인 경우도 분명히 존재한다. 예를 들어, University에서 Person을 Student(재학생), Alumnus(졸업생), Employee(교직원)로 subgrouping 한다고 하자. 이 때, 어떤 Person은 Alumnus이면서 Employee일 수 있기 때문에 이러한 경우가 o 관계에 해당한다.
지금까지 살펴본 내용을 실제 EERD에서 확인해보자.
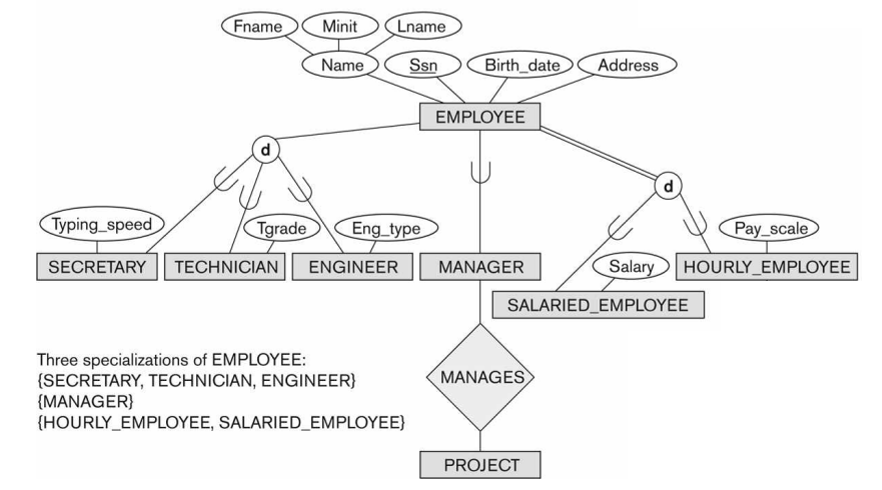
Is-A 관계는 부분집합 기호로 나타낸다. 또한 Employee-Manger와 같이 Sub Class가 하나밖에 없는 경우는 d 또는 o를 명시하지 않는다.
지난 시간의 내용을 잠깐 복습하면, 모든 Employee가 Secretary, Technician, Engineer에 속하는 것은 아니므로(다른 업무에 종사하는 사원도 있다는 가정 하에), Employee는 좌측 sub group에 대해 Partial Participate 한다. 반면, 임금을 받지 않는 사원은 없으므로, 우측 sub group에 대해서는 Total Participate 한다. 참고로, Sub Class는 d 관계인 경우 항상 Partial Participate 한다.
2) Specialization/Generalization
위 EERD에 나타나 있긴하지만, 설명하지 않은 부분이 있다. 바로 Secretary의 Typing_Speed와 같은 Sub Class의 Attribute들이다. 이것을 설명하기에 앞서, sub grouping이 왜 필요한지 생각해보자.
Employee에는 공통적으로 적용되어야 할 속성과 특별하게 적용되어야 할 속성이 있다. 예를 들어, Name, SSN, Address 등은 모든 사원에 대해 공통적으로 적용되어야 할 속성이고, Typing_Speed, Tgrade(자격 등급), Eng_Type(전공 분야)은 사원의 직무에 따라 다르게 요구되는 속성이다. 이처럼 속성을 구분하여, 공통적인 속성은 부모 클래스의 Attribute로 포함시키고, 특별한 속성은 자식 클래스의 Attribute로 포함시키기 위해 sub grouping을 하는 것이다.
만약 특별 속성까지 부모 클래스의 Attribute로 넣는다면 어떻게 될까? 당연히 Null 값의 빈번한 발생으로 데이터의 일관성이 낮아질 것이며, 데이터 중복으로 인해 데이터베이스의 효율도 떨어지게 될 것이다. 아래의 그림을 보자.
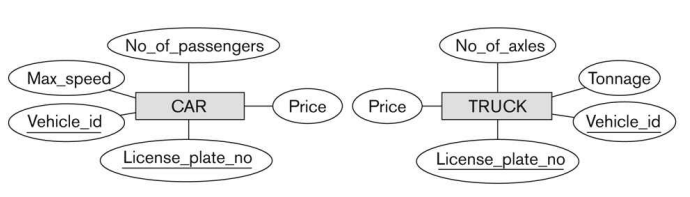
공통 속성을 한눈에 파악하기 어려울 뿐더러 데이터 중복도 빈번히 발생하고 있다. 이를 실제 테이블로 구현할 경우, 서로에게 없는 특성이 Null로 채워지게 되면서, 완성도가 매우 낮은 데이터베이스가 되어버릴 것이다. 이제 아래의 그림을 보자.
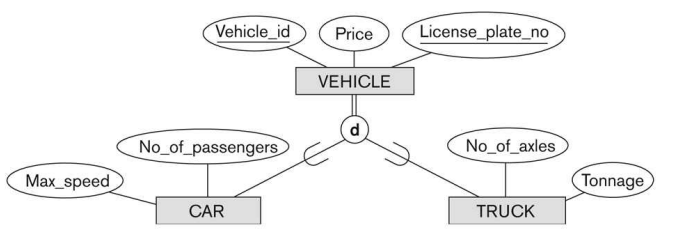
공통 속성이 한눈에 들어오고, 데이터 중복도 사라지게 된다. sub grouping이 필요한 이유가 바로 이것 때문이다.
이로써 Specialization/Generalization의 개념을 자연스럽게 이해하게 된다. Sub Class에서 Super Class를 바라보는 관점이 Generalization이고, Super Class에서 Sub Class를 바라보는 관점이 Specialization이다. 적절한 Specialization/Generalization은 데이터베이스 효율을 높여줄 뿐 아니라, 가독성을 높이는 데에도 도움이 된다.
