1. Null 값을 검색하는 쿼리
attribute가 null인지 검사하는 연산자는 Is Null과 Is Not Null이다.
① id가 null인 사원을 찾는 쿼리
select * from employee where id is null;
// select * from employee where id=null; 은 불가② 상사가 없는 모든 사원들의 이름을 검색하는 쿼리
select FName, LName
from Employee
where Super_Ssn is null;2. Nested Query와 집합 비교
where 절 안에 완전한 Select 문이 등장하는 쿼리를 중첩 질의라고 한다. where 절 안에 오는 쿼리를 서브쿼리(내부 질의), 그 밖에 있는 쿼리를 메인쿼리(외부 질의)라고 부른다.
Nested Query와 함께 자주 사용되는 비교 연산자로 IN이 있는데, IN 연산자는 집합 내에 해당 원소가 있는지 확인하기 위해 사용된다. 즉, 집합 기호 ∈와 동일한 기능을 수행한다. 또한 실행되는 순서는 Subquery-First를 따른다. 참고로, null은 연산 결과에 포함되지 않기 때문에 두 집합 내에 모두 null이 있어도 같은 원소로 보지 않는다.
지금까지 배운 내용을 토대로 실제 쿼리를 작성해보자.
① LName이 Smith인 사원이 참여 또는 담당하는 프로젝트의 프로젝트 번호 목록을 출력하는 쿼리
select distinct PNumber from Project
where PNumber in (select PNumber // 담당하는 프로젝트
from Project p, Department d, Employee e
where p.DNum=d.DNumber and d.Mgr_Ssn=e.Ssn
and e.LName='Smith')
or
PNumber in (select PNo // 참여하는 프로젝트
from Works_On w, Employee e
where e.Ssn=w.ESsn and LName='Smith');② 위의 쿼리와 동일한 기능을 하되, Union 연산자를 이용해 작성된 쿼리
(select distinct PNumber
from Project p, Department d, Employee e
where p.DNum=d.DNumber and d.Mgr_Ssn=e.Ssn and e.LName='Smith')
Union
(select distinct PNumber
from Project p, Works_On w, Employee e
where PNumber=Pno and e.Ssn=w.ESsn and LName='Smith');③ SSN이 333445555인 사원이 일하는 프로젝트와 일한 시간의 조합이 동일한 사원의 SSN을 검색하는 쿼리
select distinct w.ESsn
from Works_On w
where (PNo, Hours) in (select PNo, Hours
from Works_On
where ESsn='333445555');④ 5번 부서에서 근무하는 모든 사원보다 급여가 많은 사원의 LName과 FName을 검색하는 쿼리
select LName, FName from Employee e
where e.salary > all (select salary from Employee e
where e.DNo=5);⑤ 자신의 부양가족과 이름, 성별이 같은 사원의 FName, LName을 검색하는 쿼리
- 서브쿼리에서 메인쿼리의 alias를 사용할 수 있다.
- 이러한 쿼리를 Correlated Query(상관된 질의)라고 한다.
- 아래의 쿼리는 사원과 이름이 같고 성별이 같은 Dependent의 ESsn 필드에 존재하는 Ssn만 고른 후, 이에 대응되는 사원의 이름을 보여주고 있다.
select e.FName, e.LName
from employee e
where e.Ssn in (select ESsn
from Dependent d
where e.FName=d.Dependent_Name // 이름이 같은지
and e.gender=d.gender); // 성별이 같은지3. EXISTS
EXISTS는 IN과 비슷한 역할을 하지만, 몇몇 차이점이 존재한다. 먼저, result set을 만드는 IN과 달리, EXISTS는 메인쿼리의 결과 중에서 서브쿼리를 만족하는 해가 존재하는지만 확인한다. (반대로 NOT EXISTS는 메인쿼리의 결과 중 서브쿼리의 결과를 공집합으로 만드는 해를 찾아낸다.) 즉, 결과는 같지만 Exists의 성능이 더 좋다는 것이다. 또한 메인쿼리의 결과를 먼저 알아야 비교를 할 수 있기 때문에 실행순서로 Mainquery-First를 따른다.
그러면 IN 연산자가 왜 필요한지 의문이 생길 수 있는데, 이는 Not In과 Not Exist가 다르기 때문이라고 한다. 한마디로 설명하면, Not In은 값의 집합 안에서 특정 값이 포함되지 않는지를 확인하고 Not Exist는 하위 쿼리의 결과가 존재하지 않는지를 확인한다.
이제 Exists를 이용하여 실제 쿼리를 작성해보자.
① 자신의 부양가족과 이름, 성별이 같은 사원의 FName, LName을 검색하는 쿼리
select e.FName, e.LName
from employee e
where exists (select *
from Dependent d
where e.Ssn=d.ESsn // 자신의 부양가족
and e.gender=d.gender // 성별이 같은지
and e.FName=d.Dependent_Name); // 이름이 같은지② 부양가족이 적어도 한 명 이상 있는 관리자의 이름을 검색하는 쿼리
select FName, LName
from Employee e
where exists (select * from Dependent d
where e.Ssn=d.ESsn)
and
exists (select * from Department d
where e.Ssn=d.Mgr_Ssn);
③ 부양가족이 없는 사원의 이름을 검색하는 쿼리
select FName, LName
from Employee e
where not exists (select *
from Dependent d
where e.Ssn=d.ESsn); ④ 5번 부서가 담당하는 모든 프로젝트에 참여하는 사원들의 이름을 검색하는 쿼리
- 5번 부서의 프로젝트에 하나라도 참여하지 않는 사원을 구하는 문제로 바꿀 수 있다.
- 서브쿼리는 5번 프로젝트의 집합과 사원이 참여하고 있는 프로젝트의 집합의 차집합 결과가 공집합인 경우를 검색하는 쿼리이다. (Not Exists는 서브쿼리의 결과가 공집합인 경우에만 참을 반환하기 때문이다.)
select FName, LName
from Employee e
where not exists ((select PNumber
from Project p
where DNo=5)
except (select PNo
from Works_On w
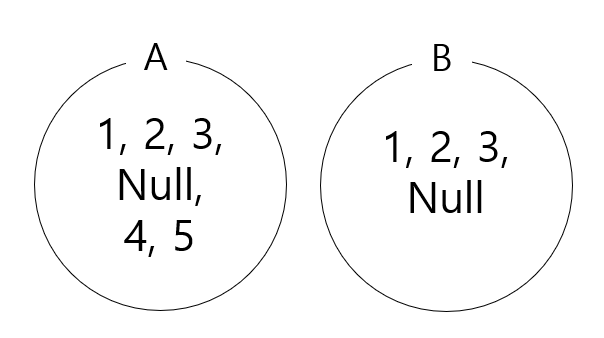
where e.Ssn=w.ESsn));Not In과 Not Exists의 차이점이 잘 와닿지 않을 수 있는데, 이 두 연산의 차이점은 null이 포함될 때 극명하게 드러난다. null에 대한 Not In과 Not Exists 연산은 예상과 다른 결과가 나타나기 때문에 주의해야 한다. 아래와 같은 집합이 존재한다고 가정하자.
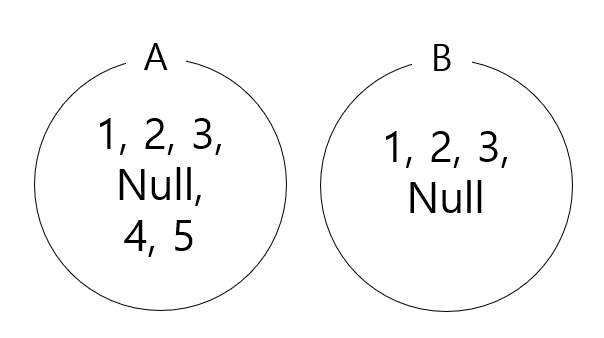
select * from A
where A.id not in (select id from B);단순하게 생각하면 위 쿼리의 결과가 4, 5가 나올 것 같지만, 실상은 Empty Set이 나온다. 이는 Not In 연산에서 null은 그 어떤 값과도 일치하지 않는 값으로 간주되기 때문이다. 그러므로 반드시 id가 null이 되지 않도록 만들어주는 조건과 함께 쿼리를 작성해야 한다.
select * from A
where A.id is not null
and A.id not in (select id from B where B.id is not null);위 쿼리의 결과는 4, 5가 될 것이다.
그럼 Not Exisits의 경우는 어떨까? 서브쿼리의 null은 그 어떤 값과도 일치하지 않으므로, 결과에 null이 포함될 것이다.
select * from A
where not exists (select * from B
where A.id=B.id);Not In의 결과가 Empty Set이었던 것 과 다르게 위 쿼리의 결과는 Null, 4, 5가 된다. 이렇듯 Not In과 Not Exists 연산은 분명히 다른 것이기는 하지만, 사실 null이 없는 경우라면 동일한 결과를 나타낸다. 즉, id와 같이 null이 허용되지 않는 값에서는 Not In과 Not Exists는 성능 차이 외에는 별다른 차이점이 없는 셈이다.
4. Aggregate Function
SQL에서 제공하는 집계함수에는 count, sum, max, min, avg 등이 있다.
① 사원의 salary의 합, 최고 급여, 최저 급여, 평균 급여를 검색하는 쿼리
select sum(salary) as Tot_Sal,
max(salary) as Max_Sal,
min(salary) as Min_Sal,
avg(salary) as Avg_Sal
from Employee;② Research 부서에 있는 모드 사원들의 salay의 합과 최고 급여, 최소 급여, 평균 급여를 검색하는 쿼리
select sum(e.salary) as Tot_Sal,
max(e.salary) as Max_Sal,
min(e.salary) as Min_Sal,
avg(e.salary) as Avg_Sal
from Employee e, Department d
where d.DName='Research' and e.DNo=d.DNumber;③ Research 부서 소속 사원의 수를 검색하는 쿼리
select count(*) from Employee e, Department d
where e.DNo=d.DNumber and d.DName='Research';④ 구별되는 사원들의 salary의 개수를 검색하는 쿼리
select count(distinct salary) from employee;⑤ 둘 이상의 부양 가족이 있는 모든 사원의 LName, FName을 검색하는 쿼리
select FName, LName
from Employee e
where (select count(*)
from Dependent d
where e.Ssn=d.ESsn) >= 2;5. Group By & Having
1) Group By 절
특정 attribute가 같은 tuple을 그룹화하기 위해 Group By 절을 사용한다. Group By 절에는 두 가지 중요한 힌트가 존재한다.
- "각 부서에 대해서", "각 프로젝트에 대해서"와 같이 "~에 대해서"는 곧 Group By를 사용해야하는 상황임을 알려준다.
- select에 사용되는 필드명과 group by 절에 사용되는 필드명이 같다.
두번째 내용이 잘 이해가 안 될수도 있는데, 사실 너무나도 당연한 내용이다. 그룹은 집계 함수를 이용해 많은 데이터를 하나로 통합한 결과이다. 해당 그룹에 대해 통계를 내려면, 당연히 그룹 간의 명확한 기준이 있어야 하는데, 이것이 바로 group by 절에 사용되는 필드명이다. 그리고 이 필드명이 반드시 결과 테이블에 포함되어야 어떤 그룹에 대한 통계치인지를 알 수 있을 것이다.
① 각 부서에 대해서 부서 번호, 부서 내에 있는 사원의 수, 평균 봉급을 구하는 쿼리
select DNo, count(*), avg(salary)
from Employee e
group by e.DNo;② 각 프로젝트에 대해서 프로젝트 번호, 프로젝트 이름, 해당 프로젝트에 참여하는 사원들의 수를 검색하는 쿼리
select PNumber, PName, count(*)
from Project p, Works_On w
where p.PNumber=w.PNo
group by PNumber, PName;2) Group By & Having
Group By 절에 조건을 사용하기 위해 Having 절이 사용된다. where과 비슷하지만, 두가지 차이점이 있다.
- where 조건은 그룹화 이전에, having 조건은 그룹화 이후에 적용된다.
- having 조건은 집계 결과에 대한 조건이다.
① 세 명 이상의 사원이 참여하는 각 프로젝트에 대해서 프로젝트 번호, 프로젝트 이름, 프로젝트에서 근무하는 사원의 수를 검색하는 쿼리
select PNumber, PName, count(*)
from Project p, Works_On w where p.PNumber=w.PNo
group by PNumber, PName having count(*) >= 3;② 6명 이상의 사원이 근무하는 각 부서에 대해서 부서번호와 40000이 넘는 급여를 받는 사원의 수를 검색하는 쿼리
- nested group by를 이용하여 작성할 수 있다.
select d.DNumber, count(*)
from Department d, Employee e
where d.DNumber=e.DNo and e.salary > 40000 and
DNo in (select e.DNo
from Employee e
group by e.DNo
having count(*) > 5)
group by DNumber; ③ 각 프로젝트에 대해서 프로젝트 번호, 프로젝트 이름, 5번 부서에 속하면서 프로젝트에 참여하는 사원의 수를 검색하는 쿼리
select PNumber, PName, count(*)
from Project p, Works_On w, Employee e
where p.PNumber=w.PNo and e.Ssn=w.ESsn and e.DNo=5
group by PNumber, PName;3) Select 문의 구성
select문은 반드시 아래의 순서로 작성되어야 한다.
select → from → where → group by → having → order by6. View
SQL에서 말하는 View는 다른 테이블에서 유도된 Virtual Table이다. View는 테이블과 어플리케이션 사이에 위치하며, read-only이므로 갱신 연산은 제한된다. 정확히 말하면, 하나의 테이블로만 구성된 view에서만 업데이트를 허용한다. 그러나 단일 테이블로 구성된 view는 거의 없기 때문에 사실상 업데이트가 불가하다고 보는 편이 낫다.
뷰를 정의하기 위해서는 아래의 SQL문에 View의 이름과 View에 포함시킬 테이블을 select 문으로 작성하면 된다.
create view {View 이름} as {select 문}View에서 사용할 필드의 이름을 지정하고 싶다면 아래와 같이 작성하면 된다.
create view {View 이름(attribute 이름, ...)} as {select 문}View에 대한 select 쿼리는 일반적인 테이블에서와 동일한 방법으로 사용 가능하며, drop을 사용하면 View를 삭제할 수 있다.
create view Dept_Info(Dept_Name, No_Of_Empls, Total_Sal) as
select DName, count(*), sum(salary)
from Department d, Employee e
where d.DNumber=e.DNo
group by d.DName;
drop view Dept_Info;