판다스의 자료구조
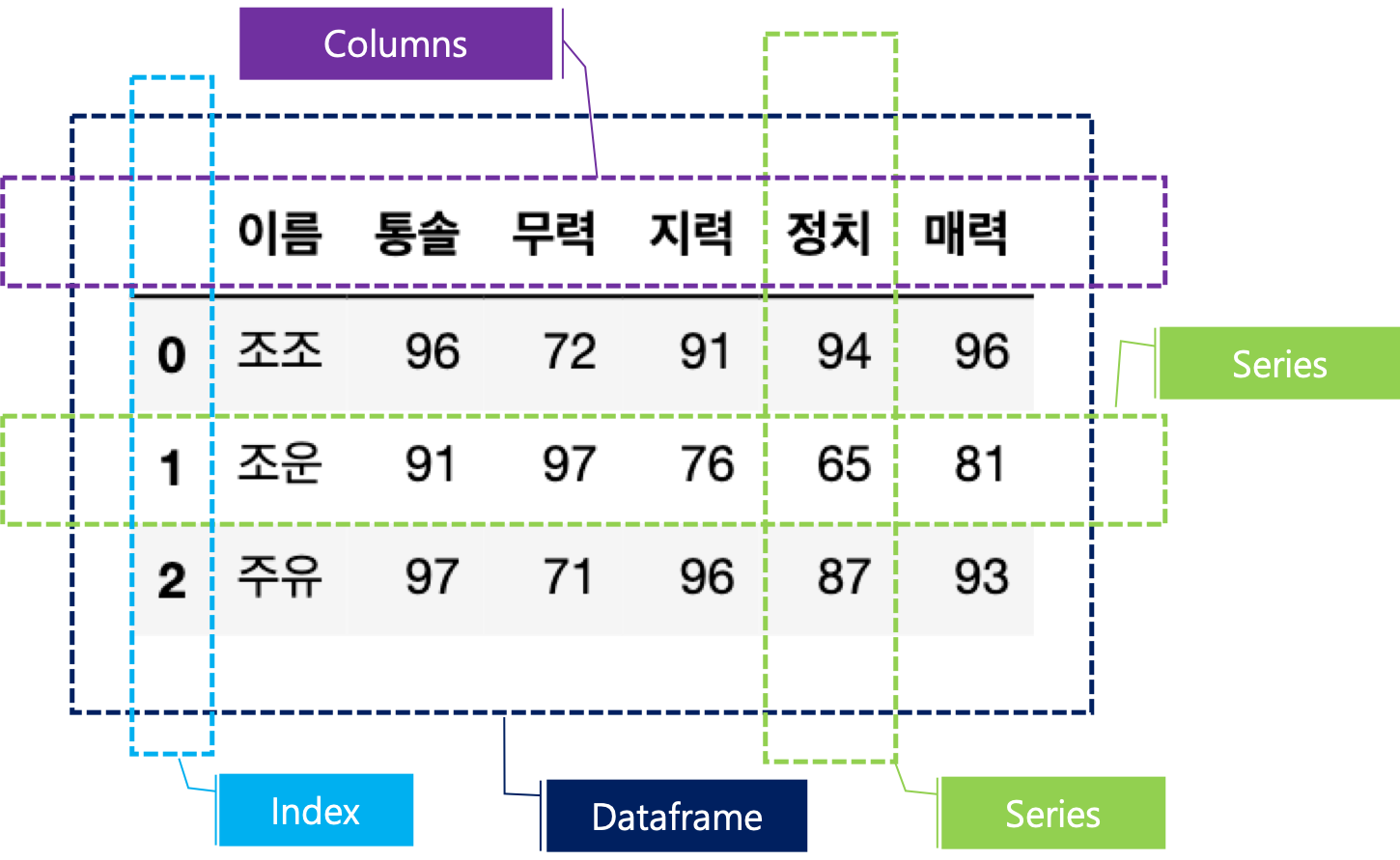
- 데이터프레임 (Dataframe) : 표 형식의 자료구조
- 시리즈의 모음
- 칼럼, 인덱스(행의 칼럼 이름), 값으로 구성
- 시리즈 (Series) : 배열 형식의 자료구조
Series
- 값의 배열 + 인덱스 배열
시리즈 생성
- pd.Series()
pd.Series(['조조', 96, 72, 91, 94, 96])- 인덱스 정보 명시하지 않으면 디폴트 값으로 숫자 인덱스 생성- 인덱스 정보 전달 : index와 values값 지정
s2 = pd.Series(['조조', 96, 72, 91, 94, 96], index=['이름', '통솔', '무력', '지력', '정치', '매력'])
s2.index
s2.values- 파이썬 딕셔너리 전달 (딕셔너리로 시리즈 생성 키-index. 밸류-값)
infos = { "이름":"조운", "통솔":91, "무력":97, "지력":76, "정치":65, "매력":81 }
pd.Series(infos)- reindex (재색인) : 생성된 시리즈의 순서 변경, 신규 인덱스(NA) 추가, 기존 인덱스 삭제
s2.reindex(['이름', '무력', '지력', '정치', '매력', '통솔'])시리즈 조회
- 조회
s2[0]
s2['이름']
s2.loc['무력'] // 인덱스 찾아줌
s2[['이름', '무력']]- 조건문
s2[s2.isnull()]
s2[s2.notnull()]시리즈 변경
- 시리즈의 값 변경
s2['무력'] = 100
s2[['무력', '지력']] = (120, 100)시리즈 삭제
- del
del s2['이름']- drop() : 삭제된 값을 복사해서 반환. 실제로 삭제되지 않는다. 다시 s2 조회하면 삭제되지 않고 그대로. inplace옵션 이용하여 바로 삭제 가능 (복사X)
s2.drop('무력')
s2.drop('무력', inplace=True)
시리즈 속성
- name : 이름
s2.name = 'person'
// 생성한 데이터에 원래 name 없고 위와 같이 생성해줘야 함
s2.name
// 확인하면 나옴- index : 인덱스
c.index
// 인덱스 확인- values : 값
c.values
// 값 확인
^^~