스터디
1.Git의 기본
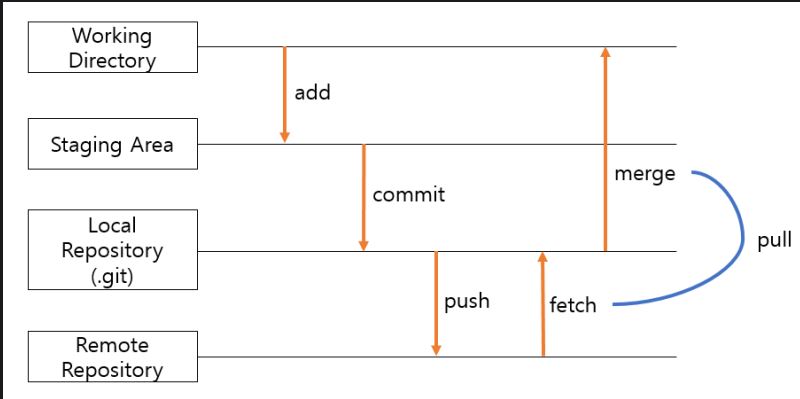
Git : 분산형 버전 관리 시스템 (원래는 Linux 소스코드를 관리할 목적으로 개발)저장소 (Git repository) : 파일이나 폴더를 저장해두는 곳원격저장소 (Remote Repository) : 원격 저장소 전용 서버에서 관리, 공유를 위한 저장소로컬 저장
2.Git 저장소 공유
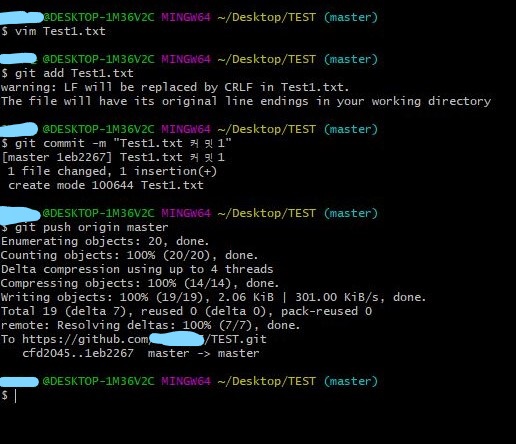
push : 업로드 (로컬 -> 원격)원격저장소에 push하면 원격저장소와 로컬 저장소가 동일한 상태가 된다.clone : 원격 저장소 복제원격 저장소의 내용을 통째로 다운로드. 변경 이력도 함께 복제되어 원격저장소와 마찬가지로 이력 참조, 커밋 가능pull : 다운로
3.Git 브랜치
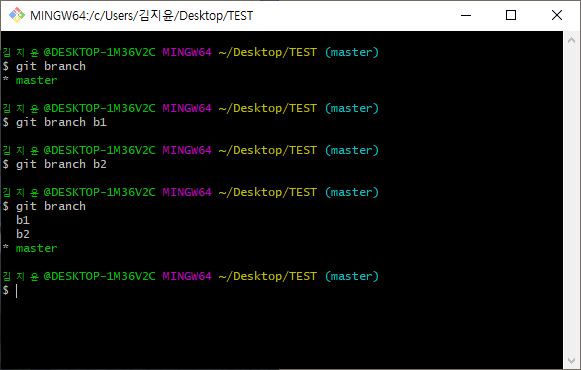
브랜치 (Branch) : 여러 개발자들이 동시에 다양한 작업을 할 수 있게 만들어주는 기능. 독립적인 저장소에서 마음대로 소스코드 변경 브랜치 : 독립적인 저장소각각 브랜치들이 서로 영향 받지 않아서 여러 작업 동시에 가능만들어진 브랜치들은 다른 브랜치와 병함(mer
4.4. Git 태그와 커밋 변경
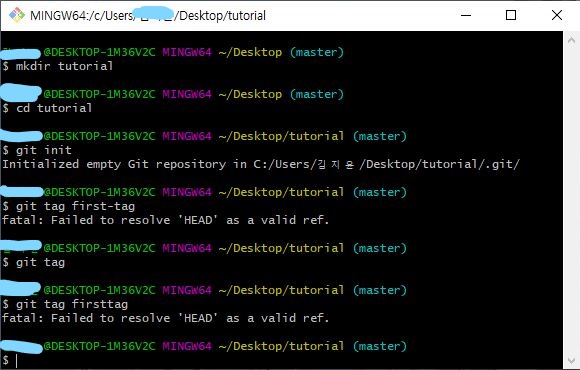
태그 (tag) : 커밋을 참조하기 쉽도록 이름을 붙인 것mkdir tutorial: tutorial 이라는 폴더 생성cd tutorial : tutorial 폴더로 이동git init : git 저장소 생성git tag ~ 부터 : 커밋을 통해 HEAD 부터 생성해
5.딥러닝 기초 (1)
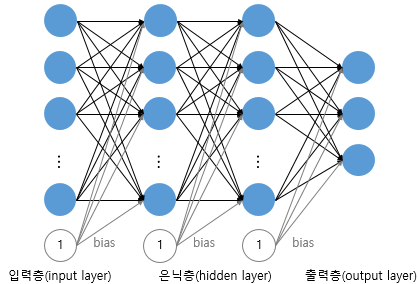
인텔리전트한 기계를 만드는 과학과 공학 (명확한 정의가 없음. 포괄적인 개념)컴퓨터가 학습할 수 있도록 구현한 알고리즘컴퓨터가 명시적으로 프로그램되지 않고도 학습할 수 있도록 하는 연구 분야 / 만약 어떤 작업 T에서 경험 E를 통해 성능 측정 방법인 P로 측정했을 때
6.딥러닝 기초 (2)
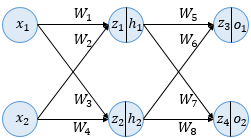
인공신경망에서의 학습 : 순전파와 역전파를 반복하며 오차를 최소화하는 가중치를 찾는 것주어진 가중치로 출력값 계산 (순전파)"(기존 가중치) - (오차를 각 가중치로 미분하고 learning rate를 곱한 값)" (역전파 , 경사하강법)1과 2를 허용 범위 내의 오차
7.소프트맥스 역전파
.png)
추가로 정리입력 : (z1, z2, z3)softmax 층 출력 : (y1, y2, y3)cross entropy 층 정답 레이블 : (t1, t2, t3)cross entropy 층 출력 : L (손실)Softmax 계층 : 입력값을 0~1사이의 값으로 정규화하여 출
8.NLP(1) 순환신경망
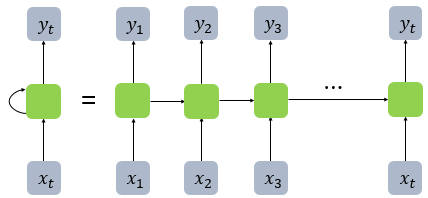
시퀀스 모델 (입출력을 시퀀스 단위로 처리)은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서 다시 은닉층 노드의 다음 계산의 입력으로 보냄.RNN 셀(메모리 셀)은 은닉층에서 활성화 함수를 통해 결과를 내보낸다은닉 상태 (hidden sta
9.cs231 역전파 코드
cs231 Convolutional Neural Networks for Visual Recognition 에 나오는 소프트맥스 역전파 코드를 공부해봄https://cs231n.github.io/neural-networks-case-study/https:
10.NLP(2) 워드 임베딩 1
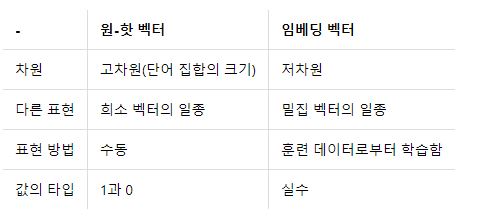
벡터 또는 행렬의 값이 대부분 0으로 표현되는 방법ex. 원핫 벡터 (정답만 1 나머지 0)한계 : 단어의 개수가 늘어나면 벡터의 차원이 한없이 커진다. (단어 집합이 클수록 고차원 벡터가 됨), 공간적 낭비원핫벡터의 경우 단어가 10000개면 벡터의 차원이 10000
11.NLP(3) 워드 임베딩 2
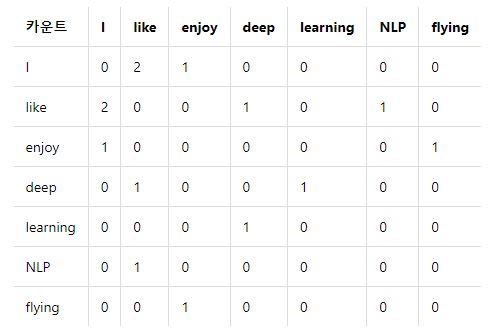
글로브(Global Vectors for Word Representation) : 카운트 기반 + 예측 기반카운트 기반인 LSA와 예측 기반의 Word2Vec을 보완LSA (Latent Semantic Analysis)각 문서에서의 각 단어의 빈도수를 카운트한 행렬을
12.NLP(4) 워드임베딩 3
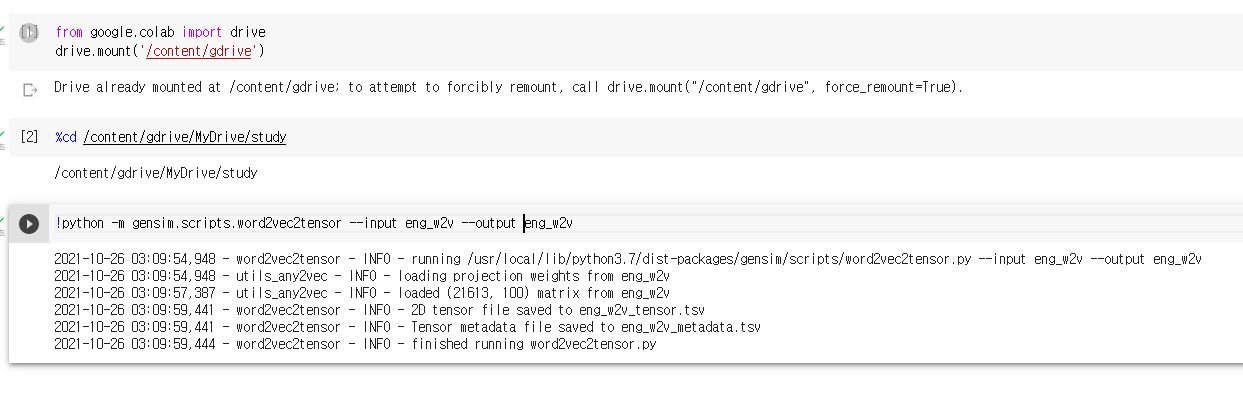
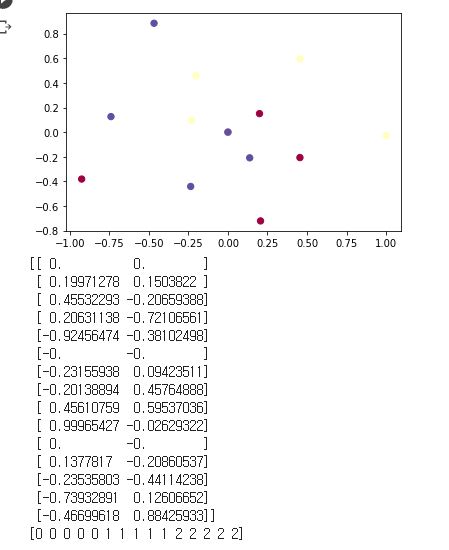
임베딩 프로젝터 (enbedding projector) : 데이터 시각화 도구 (구글). 학습한 임베딩 벡터들을 시각화한다.(시각화를 위해서 모델 학습 과정을 끝내고 파일로 저장되어 있어야 함)eng_w2v_metadata.tsv와 eng_w2v_tensor.tsv (
13.NLP(4) 합성곱 신경망

합성곱 신경망 : 합성곱층(Convolution layer) + 풀링층(Pooling layer)합성곱층 : 합성곱 연산(CONV)와 그 결과가 ReLU를 지나는 것풀링층 : 합성곱층의 결과가 POOL이라는 구간을 지나가는것 (풀링 연산)다층 퍼셉트론의 한계 : 왼쪽의
14.NLP(4) RNN을 이용한 인코더-디코더

시퀀스 투 시퀀스 : 이력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 모델ex. 챗봇(질문-대답), 번역기(입력-번역결과), 요약, STT(Speach to Text)내부 : 인코더 + 디코더인코더 : 입력 문장의 모든 단어들을 순차적으로 입력 받은 뒤에 마지막에
15.NLP(5) 어텐션 메커니즘
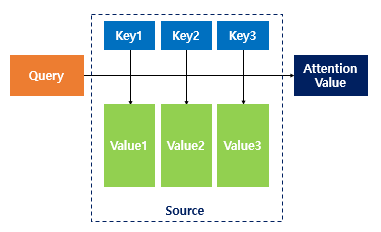
seq2seq 모델의 문제점하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니까 정보 손실이 발생기울기 소실 문제 (RNN의 고질적인 문제)아이디어 : 디코더에서 출력단어를 예측하는 매 시점마다 인코더에서의 전체 입력 문장을 다시 한번 참고한다. 해당 시점에서 예
16.NLP(6) 트랜스포머(Transformer)
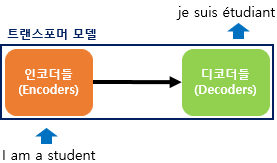
트랜스포머 : 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델. RNN을 사용하지 않음. 성능은 R
17.NLP(7) BERT(Bidirectional Encoder Representations from Transformers)
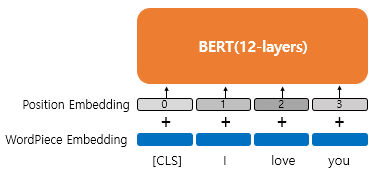
사전 훈련된 언어 모델양방향 언어 모델마스크드 언어모델\-버트 : 2018년에 구글이 공개한 사전 훈련된 모델트랜스포머 사용위키피디아(25억 단어)와 BooksCorpus(8억 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델레이블이 없는 방대한 데이
18.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding

자연어처리에 효과적ex. sentence-level tasks(natural language inference, paraphrasing(predict the relationships between sentences)), token-level tasks(named ent
19.데이터분석 (1) Pandas
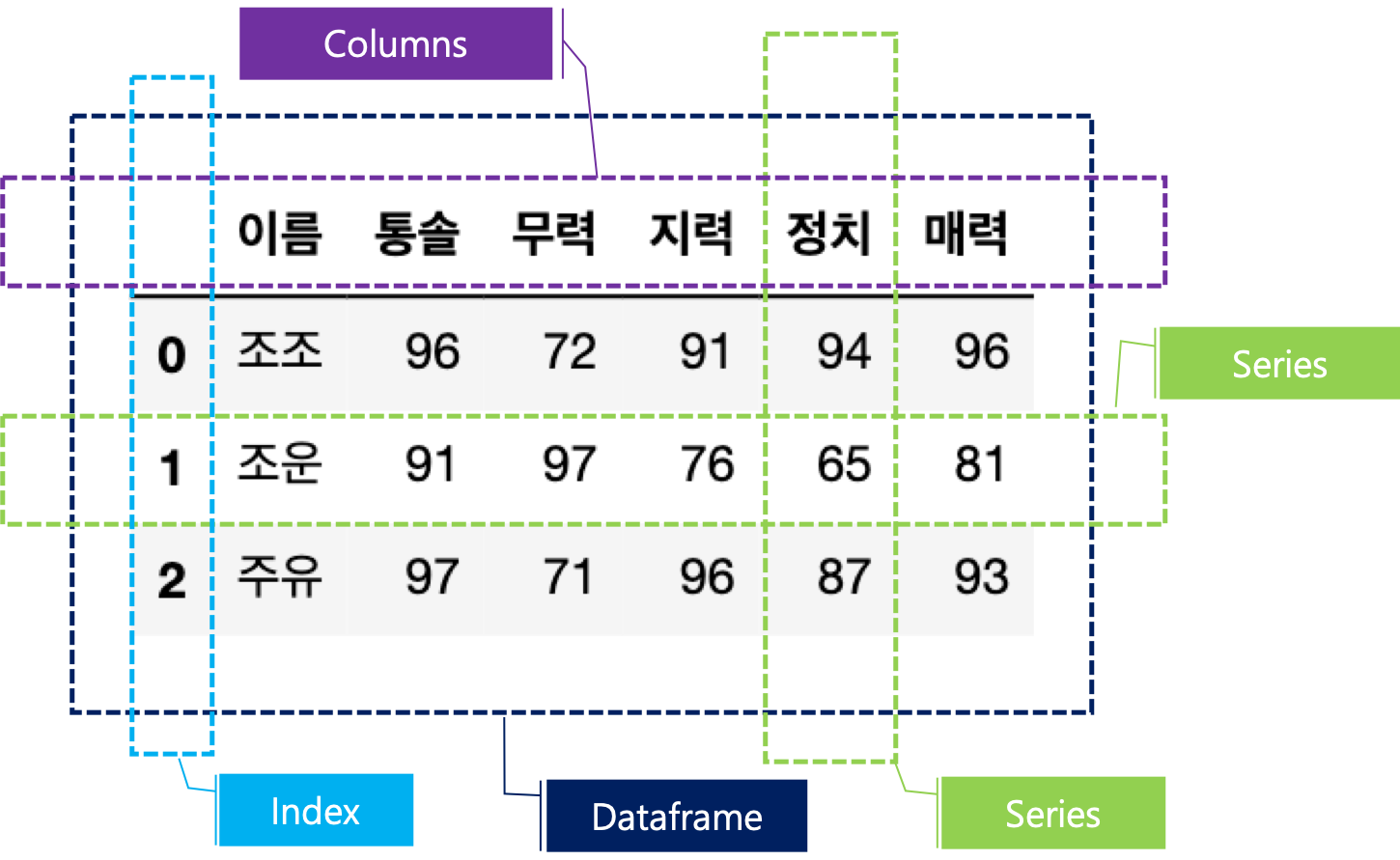
데이터프레임 (Dataframe) : 표 형식의 자료구조시리즈의 모음 칼럼, 인덱스(행의 칼럼 이름), 값으로 구성시리즈 (Series) : 배열 형식의 자료구조값의 배열 + 인덱스 배열 pd.Series()인덱스 정보 전달 : index와 values값 지정파이썬 딕