들어가며
혼자 간단한 토이프로젝트를 진행하던 중 동시성을 처리하는 방법에 대해 조사하고 조사한 방법을 테스트한 글을 남깁니다.
진행중인 토이프로젝트는 사용자들의 링크를 저장하고 저장한 링크를 조회할 수 있는 프로젝트이고, 링크를 저장 시 태그를 부여해서 사용자가 지정한 태그별 링크를 조회할 수 있도록 합니다.
링크를 게시글이라고 생각하셔도 좋을 것 같습니다. 게시글에 사용자가 태그를 부여할 수 있고 게시글을 조회할 수 있는 프로젝트라고 생각하면 이해에 도움이 되겠습니다.
이 프로젝트에는 재고 처리와 같이 동시성 처리가 꼭 필요한 부분은 없었습니다. 하지만 이 기회에 동시성 처리에 대한 공부를 하고자 링크 엔티티에 조회수 필드(hitCount)를 추가했고, 조회 시 해당 필드의 값을 1 증가시키는 로직을 추가했습니다. 해당 기능을 테스트 하면서 동시성 처리 방법에는 어떠한 것들이 있는지 확인 및 테스트를 진행했습니다.
테스트 환경 및 세팅
테스트는 저의 로컬 환경에서 테스트했습니다.. 테스트의 결과값 실행되는 환경마다 다를 수 있으니 참고 정도만 해주시면 좋을 것 같습니다. 더불어 분산 서버 환경에서의 테스트가 아닌 단일 서버 환경에서의 테스트임을 미리 밟힙니다.
- JAVA 17
- macbook 14, M1
- spring-boot 3.1.3
- postgresql 14.6
- k6 (성능 테스트 툴) - Spring Boot로 K6 & Grafana를 활용한 부하테스트 해보기 참고
테스트 시나리오
- 30명의 클라이언트가 1초 동안 http://localhost:8080/api/v1/link/1 의 주소로 [get] 요청을 보냅니다.
k6 run -u 30 -d 1s http-request.js- 테스트 스크립트
import { check } from 'k6';
import http from 'k6/http';
export default function () {
const url = 'http://localhost:8080/api/v1/link/1';
const params = {
headers: {
'Content-Type': 'application/json',
},
};
let res = http.get(url, params);
check(res, {
'is status 200': r => r.status === 200,
});
}
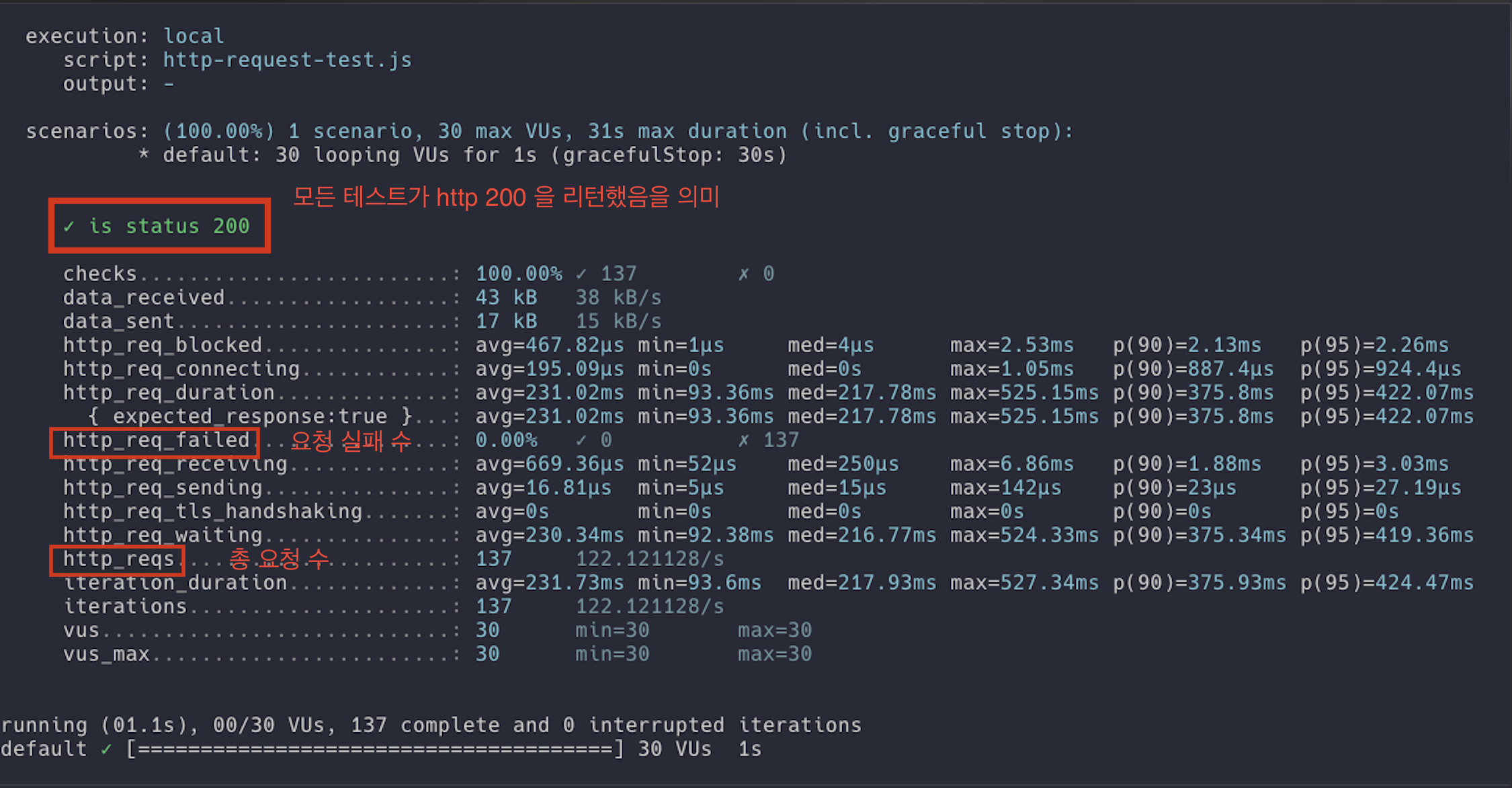
k6 테스트 결과 예시
k6가 제공해주는 많은 지표들이 있지만 해당 글에서는 표시된 부분의 수치만 살펴보겠습니다.
테스트할 리스트
- 동시성 처리 x
- sql update 문 수정
- 낙관적 락, NONE 옵션
- 낙관적 락, OPTIMISTIC 옵션
- 비관적 락, PESSIMISTIC_WRITE 옵션 (feat. join)
- 비관적 락, PESSIMISTIC_WRITE 옵션 (feat. without join)
- 메서드에 synchronized 걸기
테스트 대상 테이블 ERD
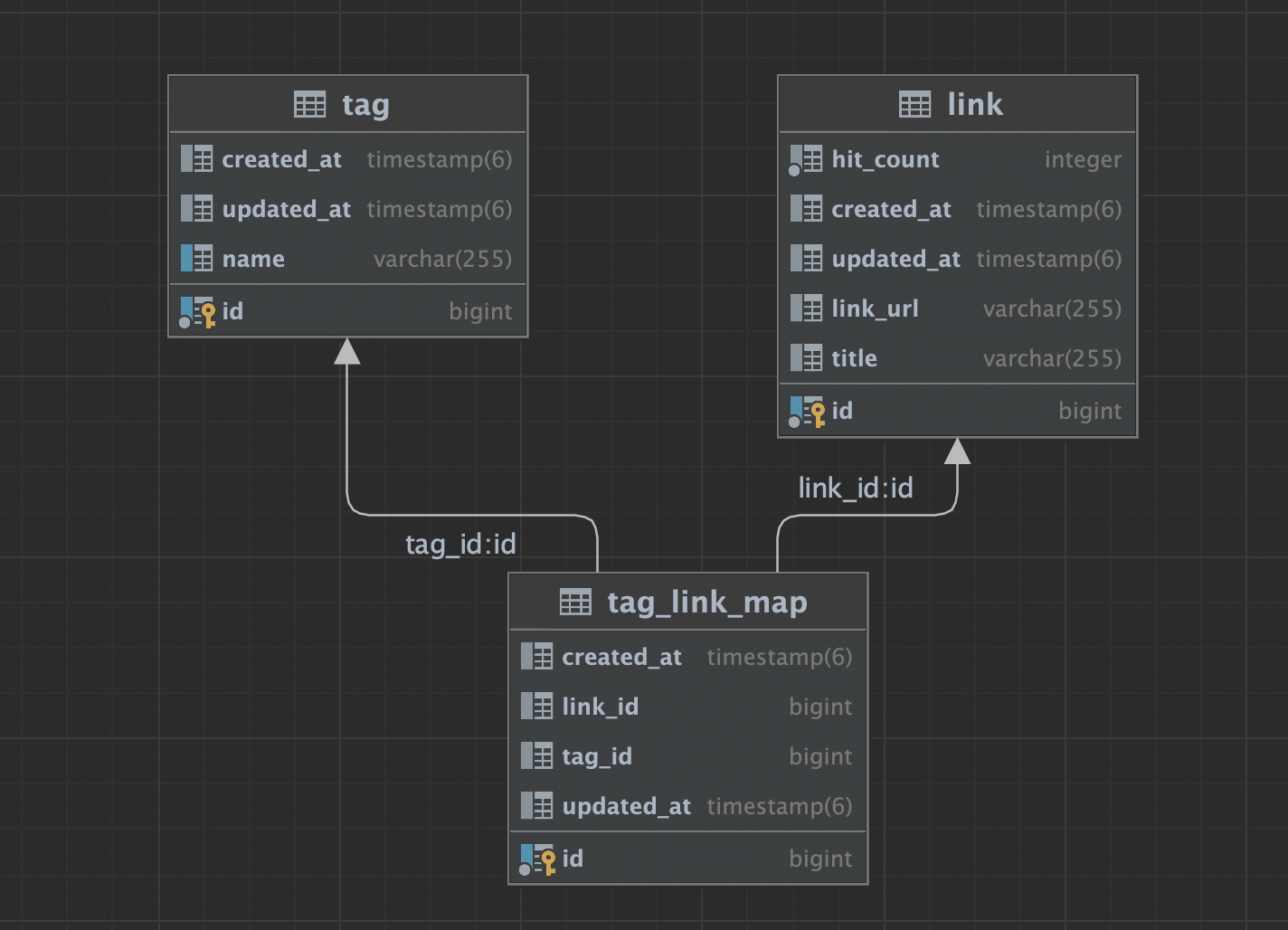
테스트 대상 테이블 데이터
가독성을 위해 유의미한 컬럼의 데이터만 명시하겠습니다.
link
| id | hit_count |
|---|---|
| 1 | 0 |
tag_link_map
| id | link_id | tag_id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 1 | 3 |
tag
| id | hit_count |
|---|---|
| 1 | tag1 |
| 2 | tag2 |
| 3 | ta3 |
테스트 진행
1. 동시성 처리 x
JPA dirty checking을 이용해 link 엔티티의 hitCount를 하나 올려주는 코드입니다. 해당 API에서는 링크와 M:N으로 연결된 Tag를 join으로 가지고 오는 findLinkByIdWithTags 메서드가 실행됩니다.
- service code
@Transactional
public GetLinkResponse getLink(Long linkId) {
var link = linkQueryDslRepository.findLinkByIdWithTag(linkId);
link.increaseHitCount();
return new GetLinkResponse(link.getId(), link.getTitle(), link.getLinkUrl(), mappingTagsFromLink(link));
}- repository code
public Optional<Link> findLinkByIdWithTags(Long linkId) {
return Optional.ofNullable(jpaQueryFactory.selectFrom(link)
.leftJoin(link.tagLinkMaps, tagLinkMap)
.fetchJoin()
.leftJoin(tagLinkMap.tag, tag)
.fetchJoin()
.where(link.id.eq(linkId))
.fetchOne());
}- sql
select l1_0.id,l1_0.created_at,l1_0.hit_count,l1_0.link_url,t1_0.link_id,t1_0.id,t1_0.created_at,t1_0.tag_id,t2_0.id,t2_0.created_at,t2_0.name,t2_0.updated_at,t1_0.updated_at,l1_0.title,l1_0.updated_at
from link l1_0
left join tag_link_map t1_0 on l1_0.id=t1_0.link_id
left join tag t2_0 on t2_0.id=t1_0.tag_id
where l1_0.id=?
update link
set hit_count=?,link_url=?,title=?,updated_at=?
where id=?-
결과
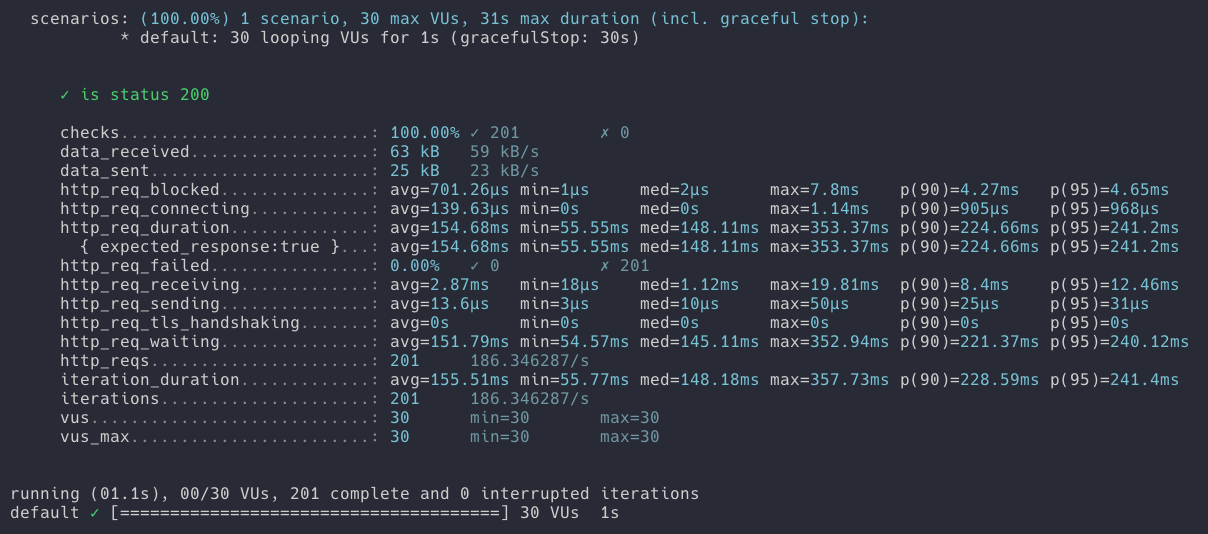
-
요청 횟수 : 201번
- 요청 성공 횟수 201번
- 요청 실패 횟수 0번 -
hitCount(조회수) 결과 : 28
30명의 가상 유저가 1초 동안 해당 API를 요청했때의 결과는 총 201번의 요청이 발생되고 조회수는 28로 저장되었습니다. 약 180개의 조회수가 유실되었습니다.
2. sql update 문 수정
조회수 유실을 막기 위해 여러 가지 방법이 있겠지만 sql의 업데이트문을 수정함으로써 조회수 유실을 막을 수 있었습니다. 해당 코드에서는 JPA의 dirty checking을 사용하지 않고 별도의 update 문을 작성함했습니다. 발생된 sql문을 보면 SET hit_count = ? 가 나가는 것이 아니라 SET hit_count = hit_count+1 가 나가는 것이 가장 큰 특징입니다.
- service code
@Transactional
public GetLinkResponse getLink(Long linkId) {
var link = linkQueryDslRepository.findLinkByIdWithTag(linkId);
linkRepository.updateHitCount(link.getId());
return new GetLinkResponse(link.getId(), link.getTitle(), link.getLinkUrl(), mappingTagsFromLink(link));
}- repository code
@Modifying
@Query("UPDATE Link l SET l.hitCount = l.hitCount + 1 WHERE l.id = :id")
void updateHitCount(Long id);- sql
update link set hit_count=(hit_count+1) where id=?- 결과
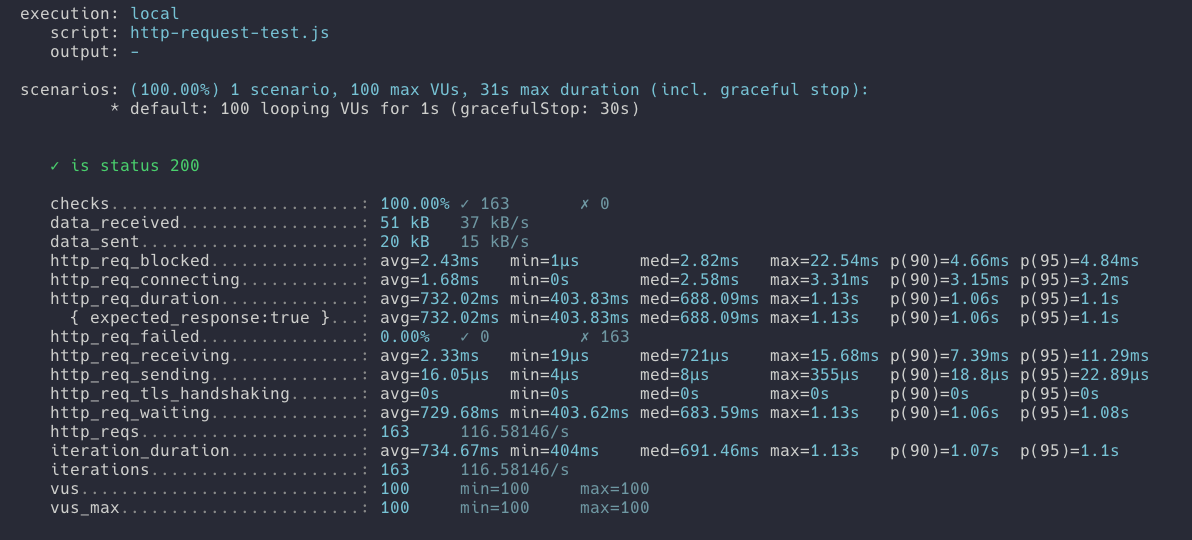
- 요청 횟수 : 135번
- 요청 성공 횟수 135번
- 요청 실패 횟수 0번 - hitCount(조회수) 결과 : 135
결과를 보면 요청 횟수가 동시성 처리를 하지 않은 테스트에 비해 꽤나 줄었습니다. 하지만 요청한 횟수만큼 정확한 조회수를 확보했습니다.
참고 : 동시성을 고려한 조회수 증가 기능
3. 낙관적 락, NONE 옵션
해당 테스트에서는 다시 JPA의 dirty checking을 사용해서 조회수를 증가시키도록 다시 수정했습니다. 그리고 @version 어노테이션을 이용하여 동시성 처리를 시도했습니다. 낙관적 락에도 여러가지 옵션이 있습니다만 NONE 옵션을 사용해서 테스트 했습니다.
- service code
@Transactional
public GetLinkResponse getLink(Long linkId) {
var link = linkQueryDslRepository.findLinkByIdWithTag(linkId);
link.increaseHitCount();
return new GetLinkResponse(link.getId(), link.getTitle(), link.getLinkUrl(), mappingTagsFromLink(link));
}- entity code
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Link extends BaseAuditEntity {
private String title;
private String linkUrl;
private int hitCount = 0;
@OneToMany(mappedBy = "link", fetch = FetchType.LAZY)
private List<TagLinkMap> tagLinkMaps = new ArrayList<>();
@Version
private Integer version; // 추가됨
public void increaseHitCount() {
hitCount++;
}
}- repository code
public Optional<Link> findLinkByIdWithTags(Long linkId) {
return Optional.ofNullable(jpaQueryFactory.selectFrom(link)
.leftJoin(link.tagLinkMaps, tagLinkMap)
.fetchJoin()
.leftJoin(tagLinkMap.tag, tag)
.fetchJoin()
.where(link.id.eq(linkId))
.setLockMode(LockModeType.NONE) // LOCK 모드 추가, 기본값
.fetchOne());
}-
sql
-
충돌이 일어나지 않을 시
select l1_0.id,l1_0.created_at,l1_0.hit_count,l1_0.link_url,t1_0.link_id,t1_0.id,t1_0.created_at,t1_0.tag_id,t2_0.id,t2_0.created_at,t2_0.name,t2_0.updated_at,t1_0.updated_at,l1_0.title,l1_0.updated_at,l1_0.version
from link l1_0
left join tag_link_map t1_0 on l1_0.id=t1_0.link_id
left join tag t2_0 on t2_0.id=t1_0.tag_id
where l1_0.id=?
update link
set hit_count=?,link_url=?,title=?,updated_at=?,version=?
where id=? and version=?- 충돌이 일어날 시 ([io-8080-exec-20] 스레드 주목 필요, 실행된 sql의 일부분)

[io-8080-exec-100]
select l1_0.id,l1_0.created_at,l1_0.hit_count,l1_0.link_url,t1_0.link_id,t1_0.id,t1_0.created_at,t1_0.tag_id,t2_0.id,t2_0.created_at,t2_0.name,t2_0.updated_at,t1_0.updated_at,l1_0.title,l1_0.updated_at,l1_0.version
from link l1_0
left join tag_link_map t1_0 on l1_0.id=t1_0.link_id
left join tag t2_0 on t2_0.id=t1_0.tag_id
where l1_0.id=?
[io-8080-exec-100]
update link
set hit_count=?,link_url=?,title=?,updated_at=?,version=?
where id=? and version=?
[io-8080-exec-93]
select l1_0.id,l1_0.created_at,l1_0.hit_count,l1_0.link_url,t1_0.link_id,t1_0.id,t1_0.created_at,t1_0.tag_id,t2_0.id,t2_0.created_at,t2_0.name,t2_0.updated_at,t1_0.updated_at,l1_0.title,l1_0.updated_at,l1_0.version
from linkl1_0
left join tag_link_map t1_0 on l1_0.id=t1_0.link_id
left join tag t2_0 on t2_0.id=t1_0.tag_id
where l1_0.id=?
[io-8080-exec-20] join을 이용한 select
select l1_0.id,l1_0.created_at,l1_0.hit_count,l1_0.link_url,t1_0.link_id,t1_0.id,t1_0.created_at,t1_0.tag_id,t2_0.id,t2_0.created_at,t2_0.name,t2_0.updated_at,t1_0.updated_at,l1_0.title,l1_0.updated_at,l1_0.version
from link l1_0
left join tag_link_map t1_0 on l1_0.id=t1_0.link_id
left join tag t2_0 on t2_0.id=t1_0.tag_id
where l1_0.id=?
[io-8080-exec-89]
select l1_0.id,l1_0.created_at,l1_0.hit_count,l1_0.link_url,t1_0.link_id,t1_0.id,t1_0.created_at,t1_0.tag_id,t2_0.id,t2_0.created_at,t2_0.name,t2_0.updated_at,t1_0.updated_at,l1_0.title,l1_0.updated_at,l1_0.version
from link l1_0
left join tag_link_map t1_0 on l1_0.id=t1_0.link_id
left join tag t2_0 on t2_0.id=t1_0.tag_id
where l1_0.id=?
[io-8080-exec-89]
update link
set hit_count=?,link_url=?,title=?,updated_at=?,version=?
where id=? and version=?
[io-8080-exec-93] update 문
update link
set hit_count=?,link_url=?,title=?,updated_at=?,version=?
where id=? and version=?
[io-8080-exec-20] update 문
update link
set hit_count=?,link_url=?,title=?,updated_at=?,version=?
where id=? and version=?
[io-8080-exec-89]
select l1_0.id,l1_0.created_at,l1_0.hit_count,l1_0.link_url,l1_0.title,l1_0.updated_at,l1_0.version
from link l1_0
where l1_0.id=?
[io-8080-exec-20] 내가 작성하지 않은 select 문
select l1_0.id,l1_0.created_at,l1_0.hit_count,l1_0.link_url,l1_0.title,l1_0.updated_at,l1_0.version
from link l1_0
where l1_0.id=?이 테스트는 sql이 조금 독특하게 나갔습니다. [io-8800-exec-20]이라고 적혀있는 부분은 각 스레드를 의미합니다. version의 충돌이 났을 때와 나지 않았을 때 나가는 sql 문이 달랐습니다. 충돌이 나지 않을 시에는 예상대로 sql 나갔지만 충돌이 났을 때는 제가 작성하지 않은 link 테이블에 대한 select 문에 한 번 더 나간다는 특징이 있습니다. 왜 해당 sql이 나가는지는 조금 더 확인이 필요합니다.
-
결과
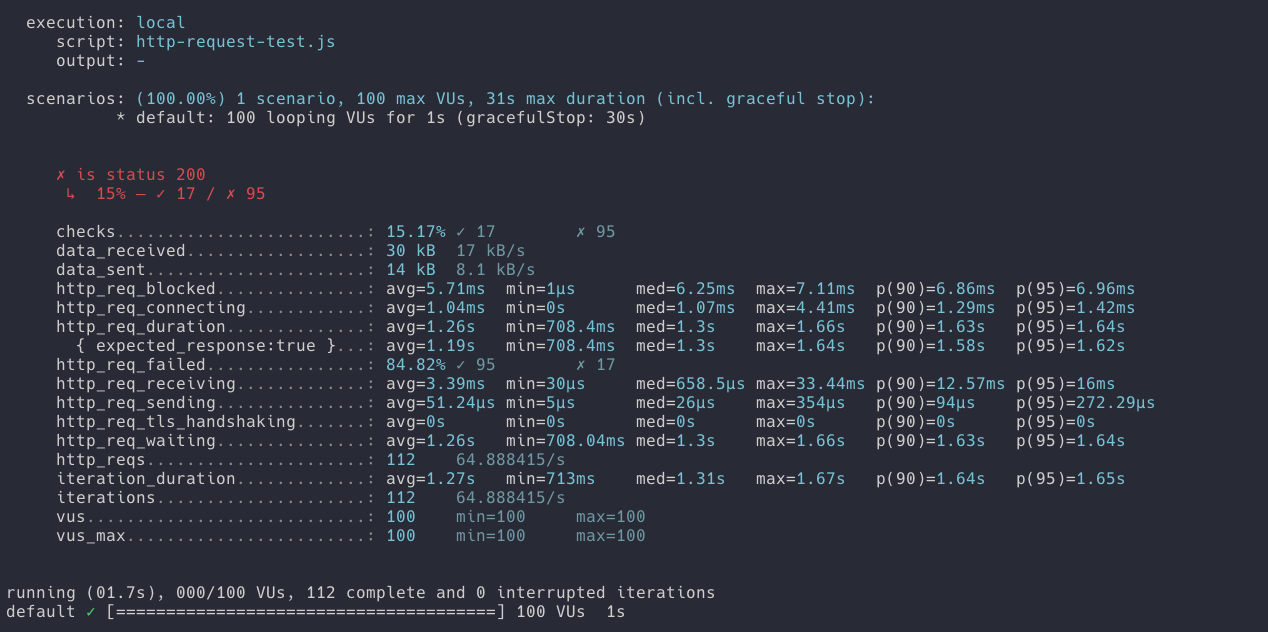
-
요청 횟수 : 69번
- 요청 성공 횟수 11번
- 요청 실패 횟수 58번 -
hitCount(조회수) 결과 : 11
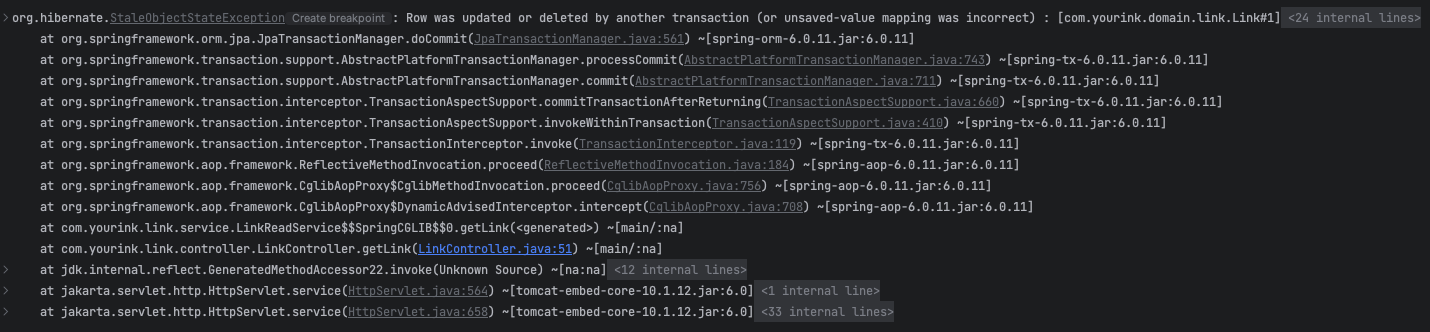
결과를 보면 요청 횟수가 줄었습니다. 낙관적락을 사용하면 서로 다른 트랜잭션에서 같은 row를 수정할 시 버전을 체크합니다. 버전이 다른 row에 대해서 update 쿼리가 나가게 되면 StaleObjectStateException: Row was updated for deleted by another trasaction 이라는 예외가 터집니다. 개발자는 이 예외를 catch 해서 다시 조회수를 증가시키는 로직을 작성할 수도 있습니다. 상황에 맞는 적절한 예외처리의 책임이 개발자에게 있습니다.
버전이 맞지 않는 로우를 업데이트 칠 시 아래와 같은 에러가 납니다.
4. 낙관적 락, OPTIMISTIC 옵션
해당 테스트는 조회 쿼리의 락 모드의 옵션을 변경했습니다. NONE -> OPTIMISTIC
- service code
@Transactional
public GetLinkResponse getLink(Long linkId) {
var link = linkQueryDslRepository.findLinkByIdWithTag(linkId);
link.increaseHitCount();
return new GetLinkResponse(link.getId(), link.getTitle(), link.getLinkUrl(), mappingTagsFromLink(link));
}- entity code
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Link extends BaseAuditEntity {
private String title;
private String linkUrl;
private int hitCount = 0;
@OneToMany(mappedBy = "link", fetch = FetchType.LAZY)
private List<TagLinkMap> tagLinkMaps = new ArrayList<>();
@Version
private Integer version;
public void increaseHitCount() {
hitCount++;
}
}- repository code
public Optional<Link> findLinkByIdWithTags(Long linkId) {
return Optional.ofNullable(jpaQueryFactory.selectFrom(link)
.leftJoin(link.tagLinkMaps, tagLinkMap)
.fetchJoin()
.leftJoin(tagLinkMap.tag, tag)
.fetchJoin()
.where(link.id.eq(linkId))
.setLockMode(LockModeType.OPTIMISTIC) // LOCK 모드 변경
.fetchOne());
}-
결과
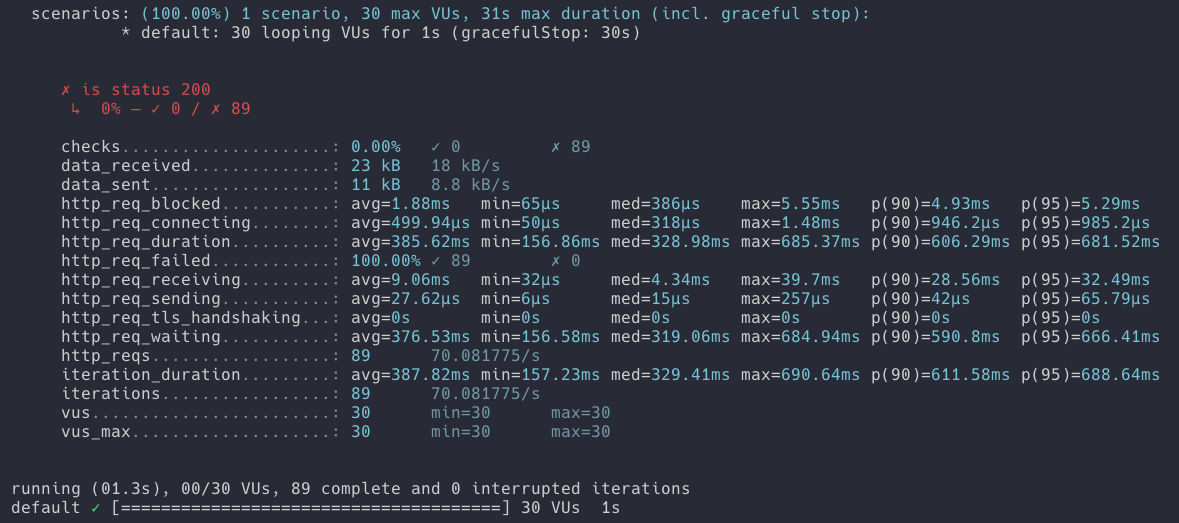
-
요청 횟수 : 89번
- 요청 성공 횟수 0번
- 요청 실패 횟수 89번
- hitCount(조회수) 결과값 : 0
Tag엔티티와 링크 엔티티를 이어주는 TagLinkMap 엔티티가 OPTIMISTIC을 지원하지 않는다는 에러 메세지를 받았습니다. 개인적으로는 Link 엔티티에만 @Version 어노테이션이 있고 Link와 조인되는 엔티티에는 Version 어노테이션이 없어서인가 라는 추측을 했습니다만 추가적인 테스트는 진행하지 않았습니다.
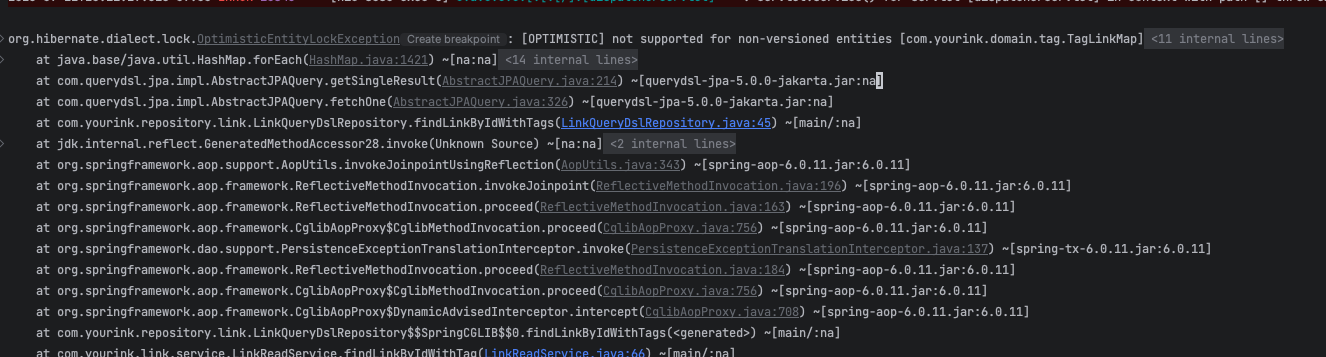
당연하게도 모든 요청이 실패했습니다. NONE 옵션과 OPTIMISTIC의 차이점을 테스트하고 싶었는데 해당 테스트에서 유의미한 결과를 도출하지는 못했습니다. 하지만 hudi 님이 작성하신 JPA의 낙관적 락을 사용한 동시성 이슈 해결 이라는 글을 보면 OPTIMISTIC 옵션과 NONE 옵션의 차이를 확인하실 수 있습니다.
NONE옵션은 조회한 엔티티를 수정할 때 다른 트랜잭션에 의해 이 엔티티가 변경되지 않음을 보장합니다. 즉, 엔티티를 수정해야 버전을 체크하죠. 반면, 위 코드에서 사용한OPTIMISTIC옵션은 조회한 엔티티가 트랜잭션 동안 다른 트랜잭션에 의해 변경되지 않음을 보장합니다. 즉, 엔티티를 수정하지 않더라도 버전을 체크해요.hudi님 블로그 발췌
5. 비관적 락, PESSIMISTIC_WRITE 옵션 ,(feat. join 사용)
비관적 락과 PESSIMISTIC_WRITE 옵션을 테스트를 진행했습니다. 이전 코드와 달라진 점은 Link 엔티티에서 @Version 어노테이션을 삭제했고, repository 코드에서 락모드를 PESSIMISTIC_WRITE로 설정했습니다.
- service code
@Transactional
public GetLinkResponse getLink(Long linkId) {
var link = linkQueryDslRepository.findLinkByIdWithTag(linkId);
link.increaseHitCount();
return new GetLinkResponse(link.getId(), link.getTitle(), link.getLinkUrl(), mappingTagsFromLink(link));
}- entity code
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Link extends BaseAuditEntity {
private String title;
private String linkUrl;
private int hitCount = 0;
@OneToMany(mappedBy = "link", fetch = FetchType.LAZY)
private List<TagLinkMap> tagLinkMaps = new ArrayList<>();
// version 필드 삭제
public void increaseHitCount() {
hitCount++;
}
}- repository code
public Optional<Link> findLinkByIdWithTags(Long linkId) {
return Optional.ofNullable(jpaQueryFactory.selectFrom(link)
.leftJoin(link.tagLinkMaps, tagLinkMap)
.fetchJoin()
.leftJoin(tagLinkMap.tag, tag)
.fetchJoin()
.where(link.id.eq(linkId))
.setLockMode(LockModeType.PESSIMISTIC_WRITE) // LOCK 모드 변경
.fetchOne());
}- sql
1. 조인을 이용한 select 문 실행
2. 앞선 select 문에서 조회 및 조인되는 대상 row들에 각자 row을 거는 select for update 문을 다시 날려 락을 건다.
- 아래의 sql에서는 link 테이블에 1 개의 row, 중간 테이블인 tag_link_map에 3개의 row, tag 테이블에서 3개의 row에 락을 건다.
[nio-8080-exec-3]
select l1_0.id,l1_0.created_at,l1_0.hit_count,l1_0.link_url,t1_0.link_id,t1_0.id,t1_0.created_at,t1_0.tag_id,t2_0.id,t2_0.created_at,t2_0.name,t2_0.updated_at,t1_0.updated_at,l1_0.title,l1_0.updated_at
from link l1_0
left join tag_link_map t1_0 on l1_0.id=t1_0.link_id
left join tag t2_0 on t2_0.id=t1_0.tag_id
where l1_0.id=?
[nio-8080-exec-3]
select id from tag_link_map where id=? for update
[nio-8080-exec-3]
select id from tag_link_map where id=? for update
[nio-8080-exec-3]
select id from tag_link_map where id=? for update
[nio-8080-exec-3]
select id from tag where id=? for update
[nio-8080-exec-3]
select id from tag where id=? for update
[nio-8080-exec-3]
select id from tag where id=? for update
[nio-8080-exec-3]
select id from link where id=? for update
[nio-8080-exec-3]
update link set hit_count=?,link_url=?,title=?,updated_at=? where id=?- 결과
- 요청 횟수 : 137번
- 요청 성공 횟수 137번
- 요청 실패 횟수 0번
- hitCount(조회수) 결과값 : 16
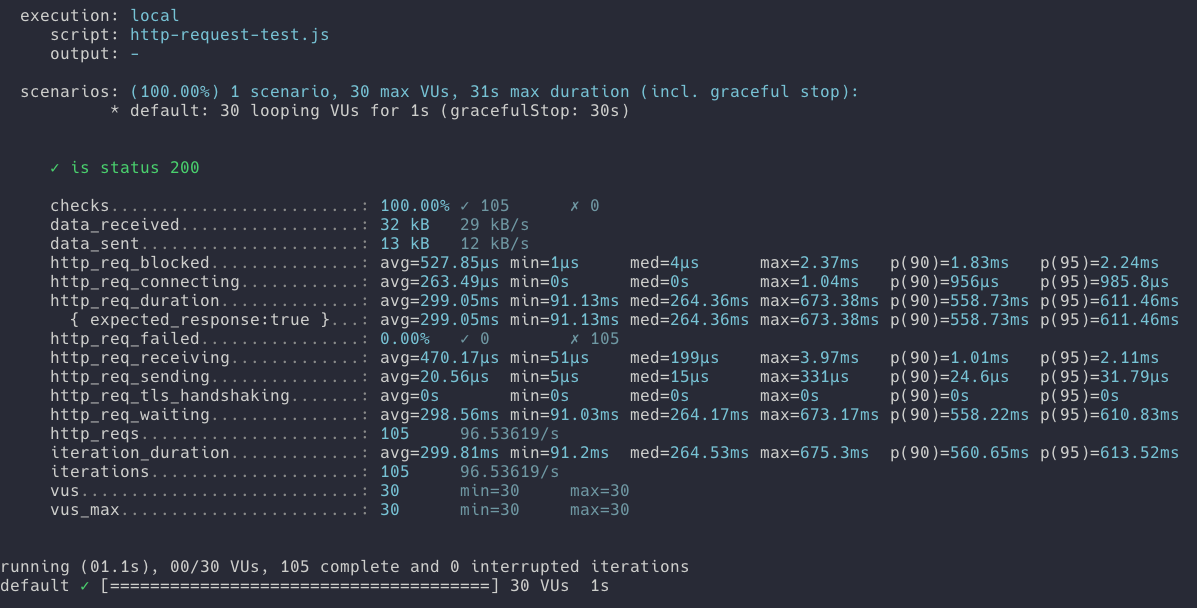
낙관적 락과 달리 실패한 요청은 없었습니다. 다만 데이터의 정합성은 맞을 것이라는 제 예상과 달리 총 137의 요청이 발생했지만 16번의 조회수만 증가했습니다. 원인은 실행된 sql을 보면 어느 정도 짐작을 해볼 수 있을 것 같은데요. 조인을 사용 시 조인을 사용하는 select 문에서 락을 거는것이 아니라 조회 후 조회된 row에 대해 각각 새로운 select문이 발생하고 락을 겁니다.
문제는 락을 건다고 해서 다른 스레드에서 조회를 못하는 것이 아니라는 점입니다. 두 개의 스레드 A, B 만 실행된다고 가정했을 시 첫 번째 스레드 A에서 join을 포함한 select문 실행된 후 그 결과로 조회된 row에 모두 락을 겁니다. 테스트를 하기 전에는 락을 걸었으니 조회가 되지 않을 것이라고 예상했습니다만 스레드 B에서 락이 걸린 row들에 대해서 select를 못하는 건 아니었습니다. A 스레드에서 락을 걸면, B 스레드에서 해당 row들에 대해 락을 획득하지 못할 뿐 조회는 가능합니다. soongjamm 님의 Select 쿼리는 S락이 아니다. (X락과 S락의 차이) 이라는 글을 보시면 도움이 됩니다.
이 테스트에서는 어떤 이유에서인지 모르지만 (join 사용 시 for update 문이 왜 나가지 않는지 찾아봐야되겠죠?) 서비스 코드에서 링크를 조회 시 for update 가 제외된 채로 조회문이 나간다는 것이 가장 큰 차이점이라고 생각합니다.
6. 비관적 락, PESSIMISTIC_WRITE 옵션 (feat. join 미사용)
앞선 테스트에서 조인을 사용하면 for update 문이 제외되고 이는 제대로된 동시성 제어를 할 수 없다는 것을 확인했습니다. 이번 테스트는 조인을 사용하지 않고 비관적 락을 사용해보도록 하겠습니다. repository 코드에 새로운 조회 쿼리를 작성했습니다. 이 메서드에서는 join을 사용하지 않았습니다. 이는 제가 만든 API 스펙 (링크 조회 시 연결된 태그도 같이 조회)과 맞지 않지만 우선 테스트와 컴파일 에러를 임시적으로 해결하기 위해 서비스 코드의 리턴 값에 List.of("tag1")를 인수로 넣었습니다.
service code
@Transactional
public GetLinkResponse getLink(Long linkId) {
var link = linkQueryDslRepository.findLinkByIdWithLock(linkId);
link.increaseHitCount();
return new GetLinkResponse(link.getId(), link.getTitle(), link.getLinkUrl(), List.of("tag1");
}- entity code
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Link extends BaseAuditEntity {
private String title;
private String linkUrl;
private int hitCount = 0;
@OneToMany(mappedBy = "link", fetch = FetchType.LAZY)
private List<TagLinkMap> tagLinkMaps = new ArrayList<>();
// version 필드 삭제
public void increaseHitCount() {
hitCount++;
}
}- repository code
public Optional<Link> findLinkByIdWithLock(Long linkId) {
return Optional.ofNullable(jpaQueryFactory.selectFrom(link)
.where(link.id.eq(linkId))
.setLockMode(LockModeType.PESSIMISTIC_WRITE)
.fetchOne());
}- sql
- join을 사용했었을 때와 다르게 (당연하게도) 별도의 락을 위한 쿼리가 발생되지 않습니다.
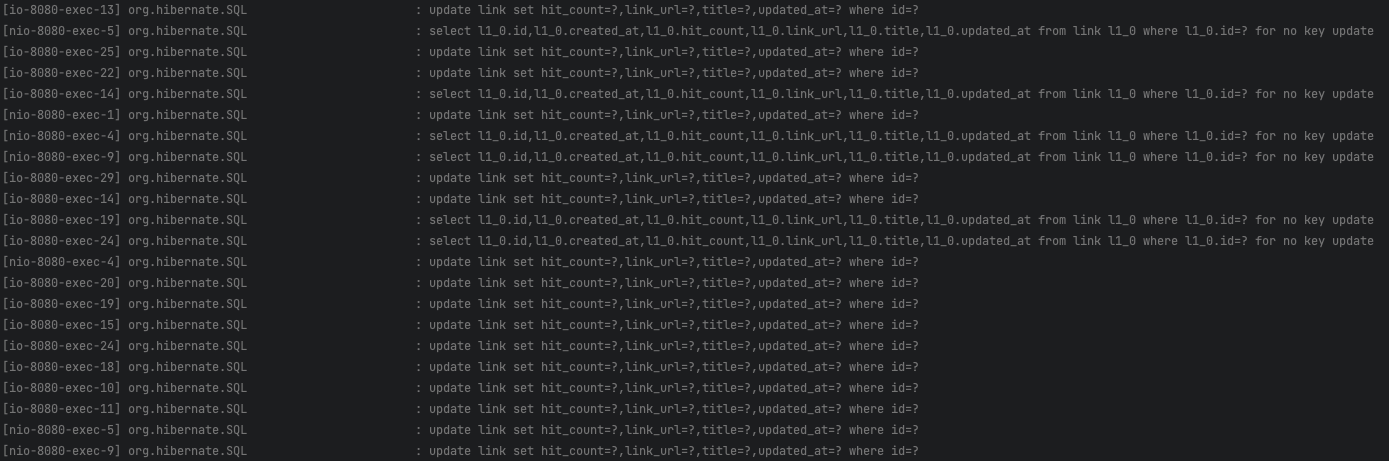
# 실행되는 sql 중 일부
... 생략
[io-8080-exec-13]
update link
set hit_count=?,link_url=?,title=?,updated_at=?
where id=?
[nio-8080-exec-5]
select l1_0.id,l1_0.created_at,l1_0.hit_count,l1_0.link_url,l1_0.title,l1_0.updated_at from link l1_0
where l1_0.id=? for no key update
[io-8080-exec-25]
update link
set hit_count=?,link_url=?,title=?,updated_at=?
where id=?
[io-8080-exec-22]
update link
set hit_count=?,link_url=?,title=?,updated_at=?
where id=?- 결과
- 요청 횟수 : 223번
- 요청 성공횟수 223번
- 요청 실패 회수 0번
- hitCount(조회수) 결과값 : 223
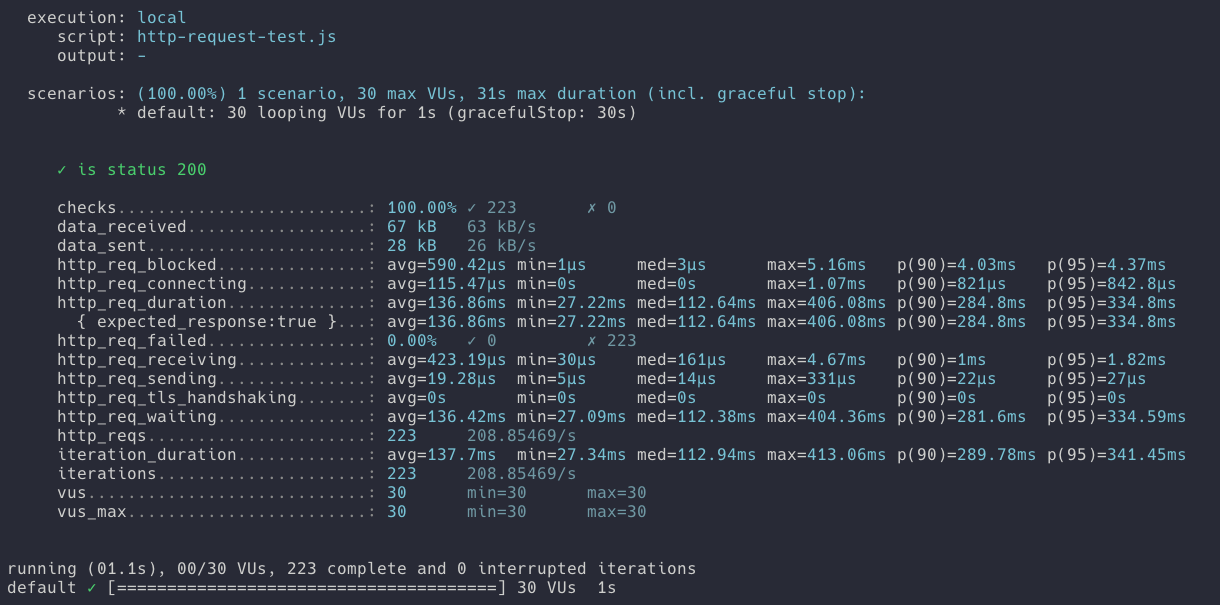
조인을 사용하지 않고 단일 테이블을 조회 시 락이 잘 걸리고 동시성 제어도 잘 동작합니다. 다만 이 테스트의 코드에서는 링크와 연결된 태그를 정상적으로 응답하지 못했습니다. 이는 꼭 조인으로만 해결할 수 있는 건 아닙니다. 링크와 연결된 태그를 찾는 별도의 코드를 추가적으로 개발해서 요구사항에 맞게 충분히 개발할 수 있습니다.
link 조회 -> 중간 테이블에서 link_id가 일치하는 row조회 -> 해당 결과에서 태그의 id를 추출 -> 태그 테이블에 다시 조회
또는 링크의 id를 받아서 해당 링크와 연결된 태그만 반환해주는 API를 새로 만드는 방법으로도 해결할 수 있겠죠.
이 테스트에서 눈여겨 볼 점은 락을 거는 쿼리에서 no key for update가 추가되어 select 문이 나가고 있습니다. 앞선 테스트 들에서는 for update가 추가되어 락을 걸었는데 말이죠. 이것이 postgres 만의 특징인지 다른 DBMS에서도 이와 같이 동작하는지 추가적인 확인 및 스터디가 필요할 것 같습니다.
7. synchronized method
번외로 synchronized 키워드를 통해서 동시성을 제어할 수 있는지 테스트 했습니다.
- service code
@Transactional
public synchronized GetLinkResponse getLink(Long linkId) {
var link = linkQueryDslRepository.findLinkByIdWithTags(linkId).get();
link.increaseHitCount();
return new GetLinkResponse(link.getId(), link.getTitle(), link.getLinkUrl(), mappingTagsFromLink(link));
}- entity code
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Link extends BaseAuditEntity {
private String title;
private String linkUrl;
private int hitCount = 0;
@OneToMany(mappedBy = "link", fetch = FetchType.LAZY)
private List<TagLinkMap> tagLinkMaps = new ArrayList<>();
public void increaseHitCount() {
hitCount++;
}
}- repository code
public Optional<Link> findLinkByIdWithTags(Long linkId) {
return Optional.ofNullable(jpaQueryFactory.selectFrom(link)
.leftJoin(link.tagLinkMaps, tagLinkMap)
.fetchJoin()
.leftJoin(tagLinkMap.tag, tag)
.fetchJoin()
.where(link.id.eq(linkId)) // 아무 락도 걸지 않음
.fetchOne());
}- 결과
- 요청 회수 : 244번
- 요청 성공회수 244번
- 요청 실패 회수 0번
- hitCount : 135
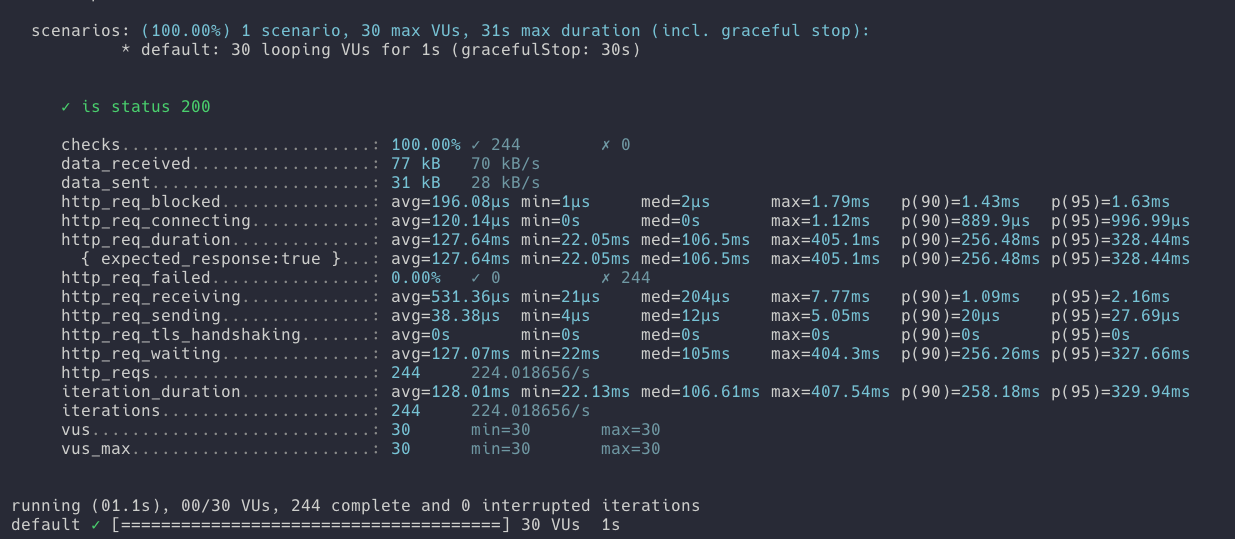
결과는 동시성이 완벽하게 제어되지는 않았습니다. 이는 @Transactional 어노테이션과 관련이 있음을 확인했습니다. @Transactional을 붙힌 메서드는 별도의 프록시 객체에서 실행된다고 합니다. 그래서 저의 예상과 다르게 동작함을 확인했습니다. 관련해서는 synchronized와 @Transactional 을 동시에 사용 시 문제점 , 이 글을 보시면 이해해 도움이 되실 것 같습니다. 해당 글을 읽어보시면 synchronized와 @Transactional을 동시에 사용하고서도 동시성을 제어하는 코드를 제공합니다.
하지만 여기서 조금 더 고려해봐야할 것은 synchronized 키워드를 써도 분산 서버 환경에서 제대로 동작할 것인가 입니다. 지금은 바야흐로 대클라우드 시대이고 한 대의 서버로만 서비스를 운영한다는 보장이 없습니다. 이 때 synchronized는 하나의 프로세스 내에서의 동시성만 보장해주므로 여러 대의 인스턴스로 운영하는 서버 환경에서는 제대로된 동시성을 보장할 수 없을 것입니다.
마치며
이번 테스트에서는 데이터베이스와 JPA가 제공해주는 동시성 제어 전략을 위주로 테스트를 진행했습니다. 이외에도 동시성을 제어하는 여러 전략들이 있음을 확인했습니다. redis를 이용한 동시성 제어가 있겠습니다. 메세지큐를 이용해서도 동시성을 제어할 수 있다고 하는데 이에 대해서는 아직 자료조사를 해보지 못했습니다. redis를 이용한 동시성 제어를 살짝 맛보고 싶으신 분은 인프런의 재고시스템으로 알아보는 동시성이슈 해결방법 강의를 한 번 보시는 것도 추천드립니다. redis 뿐만 아니라 제가 테스트한 대부분의 방법이 강의에 포함되어 있습니다.
긴 글 읽어주셔서 감사합니다.
피드백은 언제나 환영입니다.
참고
- 선착순 티켓 예매의 동시성 문제: 잠금으로 안전하게 처리하기
- JPA의 낙관적 잠금(Optimistic Lock), 비관적 잠금(Pessimistic Lock)
- Pessimistic Locking in JPA
- JPA의 낙관적 락과 비관적 락을 통해 엔티티에 대한 동시성 제어하기
- JPA의 낙관적 락을 사용한 동시성 이슈 해결
- 동시성을 고려한 조회수 증가 기능
- Select 쿼리는 S락이 아니다. (X락과 S락의 차이)
- 동시성 문제 해결하기 V2 - 비관적 락(Pessimistic Lock)
- synchronized와 @Transactional 을 동시에 사용 시 문제점
- 성능 테스트의 중요성과 목적 그리고 효과
- Spring Boot로 K6 & Grafana를 활용한 부하테스트 해보기
- 재고시스템으로 알아보는 동시성이슈 해결방법
