
MongoDB 워크샵 참석
지난 2월 28일에 개최된 MongoDB 워크샵에 다녀왔습니다. 2022년도에 참석했던 대규모 컨퍼런스와는 다르게 기업회원 위주의 제한된 소수의 인원으로 진행된 교육 세션이었습니다. 개인적으로 컨퍼런스보다 유익하고 얻어갈게 많았던 행사였던 것 같아요. 컨퍼런스는 새롭게 출시하는 클라우드 상품이나 버전업된 기능 위주의 발표 내용이 많았고 몇몇 초청된 기업의 트러블슈팅 발표가 주를 이루었습니다. 반면 이번 워크샵에서는 MongoDB Korea 엔지니어분들이 직접 발표를 하셨기 때문에 다양한 고객들의 문제를 다뤘던 컨설턴트 입장에서의 트러블슈팅 내용을 들을 수 있었습니다.
제가 참여했던 2월 워크샵의 경우에는 운영 관점에서의 세션으로 구성되었습니다. 물론 저도 운영이나 유지보수 업무도 겸했지만 주로 개발 관점에서의 MongoDB 사용 경험이 압도적으로 많았기 때문에 더 새롭고 도움이 되었던 것 같습니다. 아직 성장 중인 스타트업에 다니다보니 다양한 트러블슈팅을 겪거나 전문적인 모니터링의 필요성은 아직 느끼지 못했기에 더 흥미로웠던 강연이었네요. 세션은 다음과 같이 구성되었습니다.
- MongoDB, Atlas 소개
- Index와 쿼리 튜닝
- 데이터 모니터링
멀티테스킹과 타자 속도 이슈(?)로 컨퍼런스에 가면 필요한 내용만 키워드 위주의 간단한 필기를 하는 편입니다. 그래서 제가 리마인딩할 수 있을 정도의 러프한 필기 내용을 남기며,, 포스팅을 마칩니다.
MongoDB Atlas 소개
- BSON(JSON), 자료형, ObjectId 등 기본 소개
- SQL/MQL 형태 차이
- mql 기능들 소개
- mql 기능들 소개
- ServerLess vs Dedicated Cluster 차이
- ServerLess는 plan 책정을 미리 하는게 아니라 사용한 만큼
- 미리 Plan을 정해놓고 사용
- Dedicated 경우 Auto Scaling 가능
- 클러스터 확장
- 서비스의 일시적인 증가
- Scale Up으로 성능 증가
- 증가된 읽기 서비스에 대한 대응
- Secondary Node만 추가
- 읽기 노드만 Scale Out
- 전체 서비스(쓰기 성능까지) 사용량의 지속적인 증가
- Primary-Secondary 노드 트리 자체를 추가 (Scale out)
- Shard 구성으로 쓰기 트래픽 분산
- 서비스의 일시적인 증가
- 클러스터 네트워크
- VPC Peering
- VPC끼리 Peering 맺음
- 내부 IP 그대로 사용해서 레이턴시가 적다
- Private Link (endPoint)
- DB -> vpc 로는 접근 불가능 (단방향임)
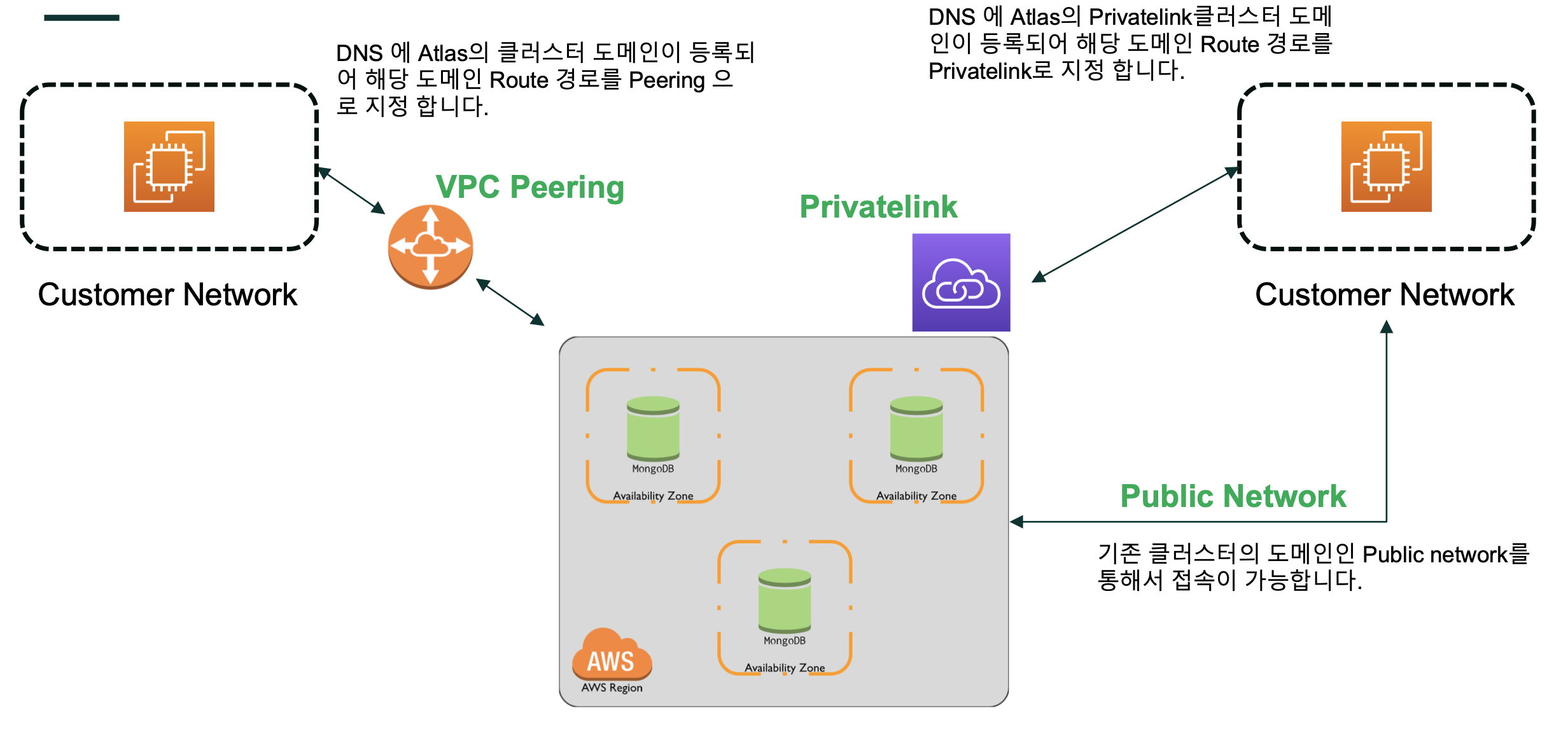
- VPC Peering
참고할만한 내용
- Update Operation
$setOnInsert:$set과 비슷하지만 upsert 시 insert에서만 동작
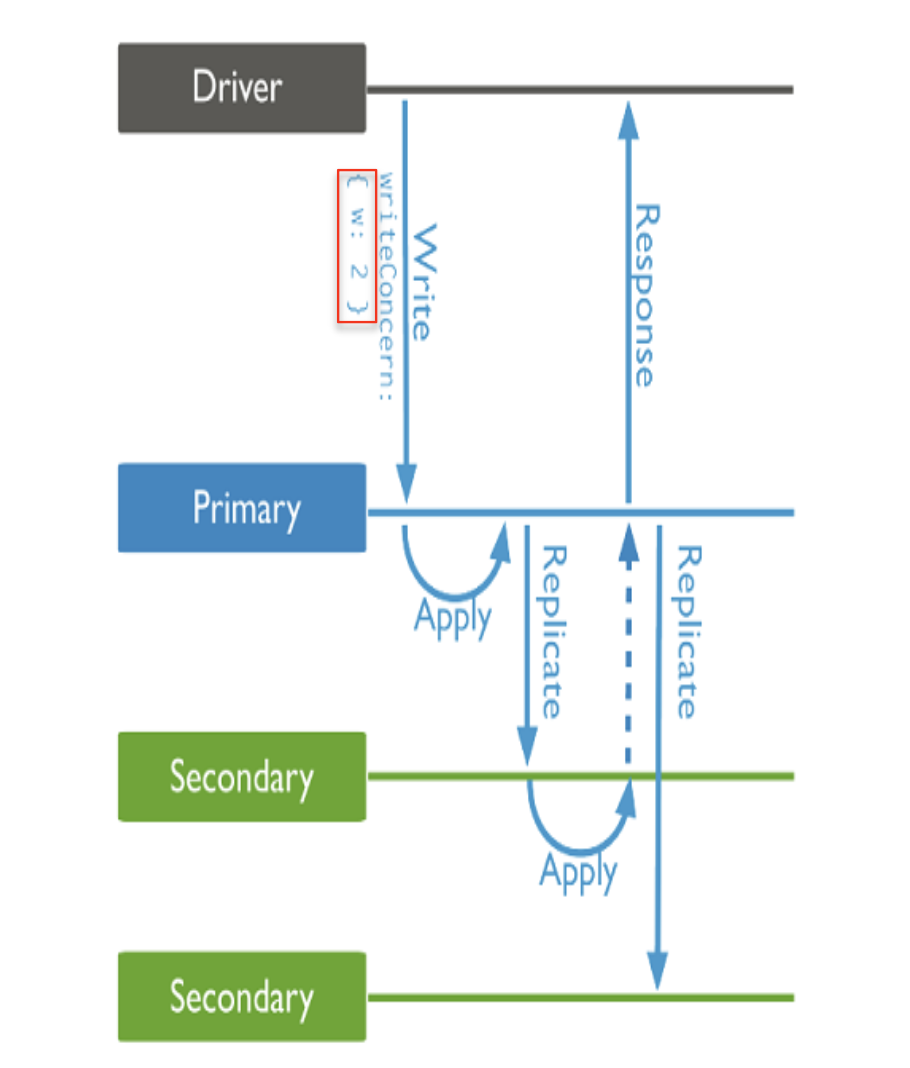
- Insert Replication
Write Concern옵션을 사용하면 Primary 뿐 아니라 Secondary DB에 복제가 확인되어야 완료 응답 리턴- 데이터 정합성 보장
Q&A
- 고가용성 제공
- Primary DB 죽었을 때 쿼리를 Queueing 해두면서 최대 5초동안 Retry
- Primary DB 죽었을 때 쿼리를 Queueing 해두면서 최대 5초동안 Retry
- ACID 제공
- One Document에는 무조건
- Ver.4부터 Mulit Document 도 제공!
인덱스
- 인덱스는 메모리 등 리소스를 사용하므로 공짜가 아니다!
- 인덱스 선정 신중하게
- 인덱스 많으면 데이터 이관시에도 오래 걸림
- 각 인덱스는 쓰기성능에 대략 10% 정도 오버헤드를 준다
- Collection 당 64개의 index 생성 가능
- 20~30 개 이상의 인덱스 사용 시 성능 degrade 될 수 있다.
- Index Types
- Primary Index
- 모든 컬렉션(테이블)은 한개의 primary key 인덱스를 가짐
- Compound Index
- 다큐먼트에 2개 이상의 필드를 대상으로 인덱스 생성
- MultiKey Index
- 배열 형태의 데이터에 인덱스 생성Index into arrays
- Wildcard Index
- 배열, sub-documents, 모든 매칭되는 필드에 자동화된 인덱스 생성
- Text Indexes
- 텍스트 검색용 인덱스
- GeoSpatial Indexes
- 좌표 공간 검색 지원을 위한 2d & 2dSphere 인덱스
- Hashed Indexes
- 샤드 환경 데이터 분산을 위한 해시 데이터
- 샤드 환경 데이터 분산을 위한 해시 데이터
- Primary Index
- Index Features
- TTL Indexes
- 특정 시간 후 문서가 자동으로 파기를 위한 단일 필드 인덱스
- Unique Indexes
- 데이터의 중복을 방지하기 위한 인덱스
- Partial Indexes
- 필드내에서 일부 데이터 만에 대한 인덱스
- Case Insensitive Indexes
- 대소문자 구분 검색을 지원하는 텍스트 검색용 인덱스
- Sparse Indexes
- 대상 필드에 존재하는 데이터만을 대상으로 하는 인덱스
- Hidden Indexes
- 인덱스의 논리적 삭제가 수행
- Hidden을 걸고 문제가 없으면 인덱스를
Drop하는 식으로 사용
- TTL Indexes
- Compass 사용법
- execution Plan 보는 법
쿼리튜닝
- 20% 이상의 데이터를 읽는데에는 인덱스 없이 Full Scan이 더 빠를 수도 있음
- 쿼리에 대한 패턴 분석이 먼저 필요함
- 필터 조건, 소팅 조건 등 분석
- 어떤 쿼리를 많이 쓰는지 등
- ESR Rule
- Equality-Sorting-Range 순으로 복합 인덱스 서순을 정하는 것이 효율적
- 몽고디비는 Range 쿼리의 결과에 대해 인덱스 정렬을 수행할 수 없다.
- MongoDB의 특징이다.
- 따라서 정렬 조건자 뒤에 범위 필터를 배치
- Covered Query
- 쿼리에 인덱스 필드가 포함된 프로젝션 이용 시 인덱스에서 직접 결과를 반환
- 문서 스캔을 하지 않기 때문에 효율적!!
- 튜닝시 항상 Selectivity 와 Cardinality를 고려해봐라
Selectivity: 쿼리 결과로 반환되는 레코드의 비율
Cardinality: 컬럼이 가질 수 있는 고유한 값의 수
Compass 재발견
- UI 가 예전보다 훨씬 좋아졌다.
- 쿼리를 쳤을 때 explain이 UI로 보기 좋게 나옴
MongoDB University
- DBA, 개발자 학습 과정이 있음!
데이터 모니터링
- 그냥 Metrics는 최대 5분 정도의 레이턴시 존재
- 실시간 수치 필요하면 RealTime 참고
- 쿼리 프로파일러는 계속 켜두지 말고 디버깅 등,,할 때에만
- 실시간 필요하다면 샘플링을 작게해서...
- 실시간 필요하다면 샘플링을 작게해서...
- Cluster Metrics
- Normalize 붙은건 100%로 노말라이즈한 값 보여줌
- 안 붙고 클러스터 8개면 최대 800%
- 붙은건 최대가 100%
- 안 붙고 클러스터 8개면 최대 800%
- Max 가 붙은건 최대치 안 붙은건 평균을 보여준다
- Normalize 붙은건 100%로 노말라이즈한 값 보여줌
- 보통 WiredTiger 캐시가 메모리 절반을 잡아먹음
- 양호한 상태이다!!
- 양호한 상태이다!!
- System Memory가 아니라 그냥 Memory는 Mongo Process 의 사용량
- Resident, virtual 메모리 사용량 차이가 많이 난다면 쿼리에 문제 있음!
Query Targeting
- scanned / returned 값
- 1에 가까울 수록 좋다!!!
- 높을 수록 인덱스 or Document Scan을 많이 한 것!!
- 하지만 ESR 룰에 맞추면 무조건 1보다 커진다...!
- 인덱스 스캔 관점에서는 ESR이 비효율적임
- 하지만 ESR을 추천하는건 인덱스 스캔을 좀 많이 해도,, Memory Sorting하는게 성능 저하가 훨씬 크다!!!
- 물론 Selectivity가 작다면 ESR보다 ER이 효율적일 수 있다.
Disk IOPS
- IOPS가 높아진다면 캐시가 부족한 것!
Wired Tiger 특징
- WiredTiger의 특징은 할당 받은 Storage를 반납하지 않음.
- 인덱스 리빌딩이 필요 없음!
- delete를 한다면 빈 메모리는 이후에 추가적으로 사용함.
- Defragment를 하고 싶다면 내부적으로 compact 라는 명령어를 사용해야 함
참고
- Update 시에는 Read도 필요하다.
- mongoDB READ는 거~의 Lock 영향을 받지 않는다
- auto Scaling은 cpu 사용량을 기준으로,,, Disk I/O 는 기준이 아니다.

Dev Log.