Cooperating process
영향을 주거나 영향을 받는 프로세스들
logical address space를 공유하거나 (주로 스레드) 데이터를 공유하거나 (shared memory, message passing)
concurrent하게 실행되는 프로세스들이 공유된 데이터에 엑세스할때는 데이터 깨지는 것을 염려해야함
=>copperating processes 들이 동시에 concurrent하게 실행될때 동시에 어떤 데이터에 접근할 때 시행 순서가 순서대로 실행되도록 보장해줘야한다. logical address space나 공유된 shared 메모리같은것들이 데이터 일관성이 유지될 수 있다.
concurrent 동시성
적어도 두 개의 스레드가 진행중일때 존재, CPU 코어가 한번에 하나의 명령어만을 처리, 문맥교환, Context Switching)되면서 실행되기 때문에 동시처럼 보인다.
->동시성은 하나의 CPU 코어 내에서 여러 프로세스(또는 쓰레드)들을 빠르게 교차하면서 한번에 하나의 명령어만을 수행하는 방식
parallel 병렬성
2개 이상의 CPU 코어일때, CPU 코어가 하나의 프로세스(또는 쓰레드)를 맡아서 실행한다. 병렬성의 수행방식은 컨텍스트 스위칭하지 않고 각각의 쓰레드를 수행
데이터의 통일성(integrity)
여러 프로세스들이 데이터를 공유하고있을 때
상호협력적인 프로세들이 공유 데이터에 동시적으로 접근하는 것은 데이터 불일치(data inconsistency)가 발생할 수 있다.
동시 실행(concurrent execution, 동시성) 일때 문제
어떤 한 프로세스가 실행하는 중에 인터럽트가 발생하고 CPU 코어의 제어권을 또 다른 프로세스에게 선점될 수 있다.
선점한 다른 프로세스는 기존 프로세스가 접근하고 있는 공유 자원에 접근하여 값을 바꾸는 상황이 발생하여 데이터의 불일치가 발생할 수있다.
어떤 프로세스가 언제어디서나 인터럽트 발생해서 컨텍스트 스위치 발생할 수있는데 instruction 스트림이 어디서 끊길지 모른다. 그러다가 다음 프로세스가 들어와서 자기 코드를 실행하다 보면 데이터 공유하면 항상 문제가 발생한다.
병렬 실행(parallel execution, 병렬성) 일때 문제:
병렬 실행이란 2개 이상의 CPU 코어를 통해서 하나의 프로세스을 처리한다.
병렬 실행의 대표적인 특징은 각각의 CPU 코어들이 하나의 프로세스를 실행한다.
하지만 병렬 실행중 하나의 공유 자원을 CPU 코어를 할당받은 쓰레드들이 접근한다면 데이터 불일치가 발생할 수 있다.
여러개의 프로세스가 동시에 분리된 프로세싱 코어에서 실행하게 되면 항상 동기화 문제가 발생한다.
생산자 소비자(producer-consumer) 문제
버퍼를 통한 share data를 비동기적으로 읽고싶을때 읽고 쓰고 싶을 때 쓴다. 만약 cuncurrent 하다면 한쪽이 쉴때 한쪽이 읽음 문제발생
버퍼에 아이템이 몇개인지 카운팅해보자, count를 0으로 초기화하고 새 아이템 push 할 때마다 1씩 증가 시켜주고 새아이템을 꺼내 갈때마다 1감소시켜주는 이런 코드를 생각해보자
생각해보면 P와 Q가 서로 따로 CPU를 점유(읽을때 잠시, 쓸때 잠시)하는데 문제가 없을 것같다. => 하지만 Data inconsistency 발생
Data inconsistency:
P Q 프로세스가 분리되서 동작하니까 제대로 동작할거라고 생각하는데
예를들어 count가 5다 데이터 넣을때 ++ 뺄때 -- => 실제로는 4,5,6등 나옴
전역변수 sum을 0으로 뒀다.
10000까지 증가시키는 스레드, 10000번 감소시키는 스레드 실행한다.
두개의 스레드는 코드영역, 데이터영역을 공유하기 때문에 결과는 0이 나올것 같지만 다름 -3955 , 0 , -1950 등등 나온다.
int sum = 0; //전역변수 sum
void *run1(void *param)
{
int i;
for (i = 0; i < 10000; i++)
sum++; // 증가
pthread_exit(0);
}
void *run2(void *param)
{
int i;
for (i = 0; i < 10000; i++)
sum--; // 감소
pthread_exit(0);
}
int main()
{
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, run1, NULL);
pthread_create(&tid2, NULL, run2, NULL);
pthread_join(tid1, NULL); // 메인은 기다림
pthread_join(tid2, NULL); // 메인은 이 두개 끝날때까지 기다림
printf("%d\n", sum);
}실제 ++ --을 살펴보면

이래 돼있는데 register = register -1 , +1 에서 컨텍스트 스위치가 발생하게되면 문제가 된다
예를들어
register1 에 count 5가 들어오고 +1 이됐는데 여기서 컨텍스트 스위치가 발생해서 이 스레드는 레디큐로 가고 다음 쓰레드에서 register2 = count 에서는 또 5가 들어온다.
다음 스레드 다 처리하고 카운트는 --돼서 4가돼있는데 스레드1은 남아있는 작업 실행해야되니까 count = register1 을 실행하니까 기억하고있던 register1(6)을 count에 써버린다.

=> 두개의 인스트럭션이 어떤 순서로 sequential하게 실행되느냐에 따라서 임의적인 순서로 interleaving되면 Data inconsistency가 발생한다.
Race Condition: 경쟁 상황
여러개의 프로세스(or 스레드)가 존재하는 경우
같은 공유자원에 동시에 접근하고 갱신하는 경우
어떤 데이터를 공유할때 concurrent하게 access하거나 처리하려고하면 실행의 결과는 어떤 순서에 따라서 달라진다.
Race Condition해결방법
특정시간에 한개의 프로세스만 shared data 를 다룰수 있다.
=> 프로세스 동기화 synchronized
논리적인 주소 공간을 공유하는 상호 협력적 프로세스들의 순서가 있는 실행(orderly execution, 동기화)이 보장되어야한다.
in java
run1, run2 는 서로다른 별도의 객체가된다. count가 다름(메모리 다른 힙에저장) 경쟁상태가 아님 레스컨디션이 아님
=> 문제발생하지 않음
public class RaceCondition1 {
public static void main(String[] args) throws Exception {
RunnableOne run1 = new RunnableOne();
RunnableOne run2 = new RunnableOne();
Thread t1 = new Thread(run1);
Thread t2 = new Thread(run2);
t1.start(); t2.start(); // 시작
t1.join(); t2.join(); // t1끝날때까지 기다려라, t2끝날때까지 기다려라
System.out.println("Result: " + run1.count + ", " + run2.count);
}
}
class RunnableOne implements Runnable {
int count = 0;
@Override
public void run() {
for (int i = 0; i < 10000; i++)
count++;
}
}그래서 static 으로 count 선언
=>race condition 발생
class RunnableTwo implements Runnable {
static int count = 0;
@Override
public void run() {
for (int i = 0; i < 10000; i++)
count++;
}
}
public class RaceCondition2 {
public static void main(String[] args) throws Exception {
RunnableTwo run1 = new RunnableTwo();
RunnableTwo run2 = new RunnableTwo();
Thread t1 = new Thread(run1);
Thread t2 = new Thread(run2);
t1.start(); t2.start();
t1.join(); t2.join();
System.out.println("Result: " + RunnableTwo.count); // 여기서는 레이스컨디션 발생
}
}The Critical Section Problem (임계영역 문제)
어떤 한 프로세스가 임계 구역으로 정해진 구역에서 실행중이면 다른 프로세스들은 해당 임계 구역의 코드들을 실행하지 못하는 구역
임계 구역에서는 다른 프로세스와 공유자원의 값을 변경하거나, 테이블을 갱신하거나 파일을 쓰거나 하는 등의 작업을 수행
두개 이상의 프로세스가 임계구역에 존재할 수 없다.
n개의 프로세스가 있을 때 어떤 코드 영역을 critical section이라고 부르자
어떤 데이터 영역을 critical section에서 shared data를 엑세스(업데이트)한다
하나의 프로세스가 critical section을 실행하고 있을 때 다른 프로세스들은 이 critical section에 진입(실행)할 수 없다.
=> race condition 발생 안함
두개의 프로세스가 동시에 ciritical section을 실행하지 않는다.
-> 프로세스들의 synchronization -> cooperatively 하게 공유데이터 처리
코드 구역
entry-section: 임계 구역에 들어가기 위해서 허락을 요청하는 코드 구역. critical section에 진입하는 코드영역 진입한다는 허가를 얻는다.
critical-section: 다른 프로세스와 공유하는 자원을 갱신하거나 접근하는 구역
exit-section: 임계 구역에서 나오는 구역. 나와서 허가반납한다.
remainder-section: 나머지 남은 코드

critical section 풀때 요구사항
Mutual Exclusion: 상호배제 보장
어떤 프로세스가 critical section 실행중일때 다른 프로세스들은 critical section 진입할 수가 없다.
-> deadlock과 starvation이 발생할 수 있음
Prgress:(avoid deadlock)
어떤 프로세스가 critical section에 있는데 아무도 이 critical section에 무한대로 진입하지 못하는 상황. 프로세스는 무한정 기다리면 안되고 적절한 시기에 진입을 시켜야 한다.
Bounded Waiting: (avoid starvation)
대기시간 한정 : 리미트를 준다.
여러 프로세스들이 critical section에 진입하고 싶은데 우선순위들 때문에 평생 실행못하고 대기만 함
진입 요청이 허용될 때까지 다른 프로세스들이 그들 자신의 임계 구역에 진입하도록 허용되는 횟수에 제한이 있어야한다.
운영체제 커널영역에서 발생할 수 있는 예
P0 에서 fork해줘서 pid 부여해줄려고하는데 리턴하기전에 P1에서도 fork해줘서 pid가 두개 같아져서 충돌날 수 있다.
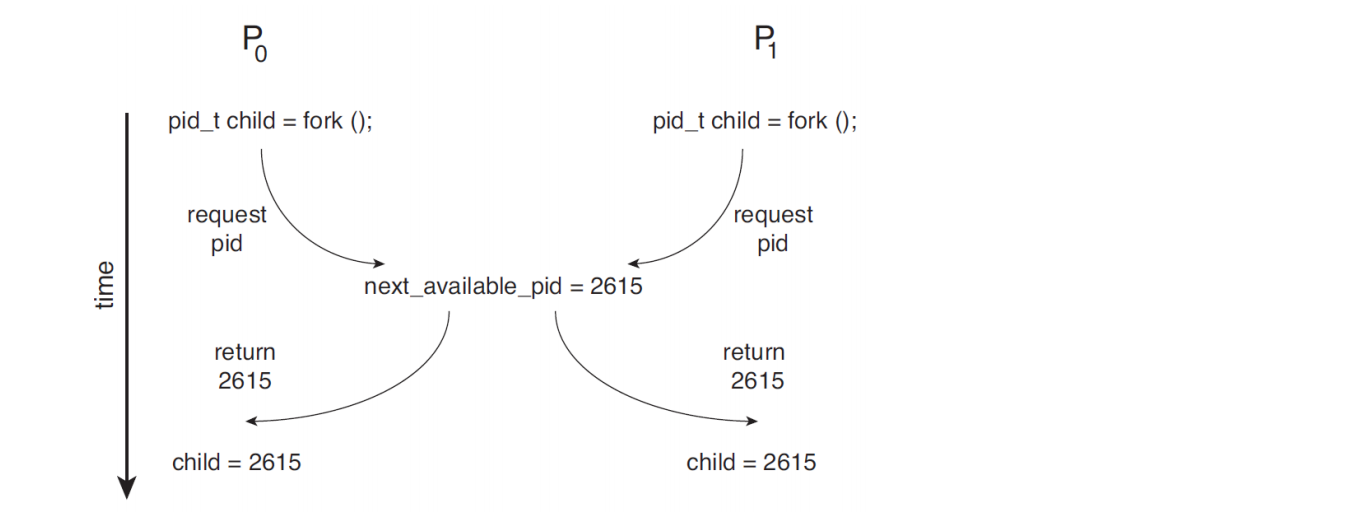
single-core 일때
critical secition에 진입하는 가장 좋은 방법: interrupt가 발생하지 않도록 한다.
어떤 shared variable에 접근하고 있으면 예를들어 count++하고 있을 때 이 시간 동안 interrupt 하지 못하게한다.
이 instruction의 current sequence 를 순서대로 실행되도록 반드시 보장해줘야한다. preemption하지 않게
멀티프로세서 화경에서는 코어가 여러개 있으면 모든 인터럽트를 다 막아 줘야한다. -> 시스템 성능이 확 떨어짐
non-preemptive 커널
어떤 커널모드가 한번 진입을 하고 나면 자기가 이 커널모드를 내려놓을 때까지 계속 CPU를 쓰게 해주니까 race condition 이 발생할 일이 없다.
어떤 프로세스가 커널모드에 진입을 하게 되면 자발적으로 커널 모드를 종료할때까지는 경쟁상태로부터 자유롭다.
count++할때까지 경쟁상태가 안발생하니까(context switching 안하니까) 아무문제 없음 -> 성능이안좋으니 안 씀
preemptive 커널
어떤 프로세스가 커널 모드에서 수행중일때 다른 프로세스가 선점하는 것을 하용한다.
프로세스 실행되는 중간에 preempted(선점)될수있다. -> 동기화 문제 발생하고 다루기 어렵다. 하지만 응답성이 훨씬 좋음 , 성능이 좋음
