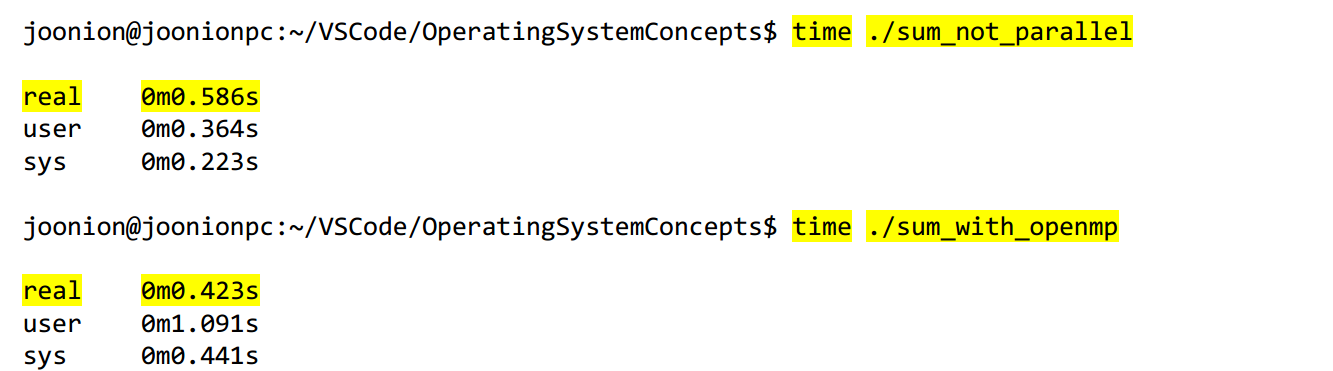
멀티스레딩
user 스레드:
커널 영역의 상위에서 지원되며 일반적으로 사용자 수준의 라이브러리(POSIX의 pthread, Java 라이브러리 등)를 통해 구현
사용자 모드에서 사용하는 스레드, JVM은 여러개 스레드를 실행할 수 있다 뿐이지 운영체제가 갖고 있는 CPU안에 있는 코어들을 자기 마음대로 넘나들 수 없다.
kernel 스레드:
운영체제에 의해 직접 지원되고 관리됩니다. 거의 모든 운영체제들은 커널 쓰레드를 지원합니다.
커널 모드에서 사용하는 스레드, OS가 직접 매니지하는 스레드

다중 쓰레드 모델
Many-to-One Model
한개의 커널쓰레드가 많은 유저 쓰레드를 감당할 수 있다.
One-to-One Model
한개의 커널스레드에 유저스레드 1개를 매핑
Many-to-Many Model
다양한 유저스레드, 다양한 커널스레드

다대일 모델(Many-to-One Model)
여러개의 사용자 수준 쓰레드를 하나의 커널 쓰레드에 매핑하는 모델
쓰레드 관리가 사용자 공간의 쓰레드 라이브러리에 의해 관리되는데 만약 한 쓰레드가 시스템 콜(System Call)에 의해 블록(Block)이 된다면 매핑된 커널 쓰레드도 블록된 상태가 되어 전체 프로세스가 봉쇄됨
또한 한번에 하나의 사용자 쓰레드만이 커널에 접근할 수 있기 때문에 다중 쓰레드가 다중 처리기(Multiprocessor)에서 수행되도 병렬로 작동할 수 없다.
한 개의 커널쓰레드에 너무 많은 유저스레드 붙일 수 없음, 모지라면 이제 여러개 유저쓰레드를 여러개 커널쓰레드에 붙인다. 여러개의 유저스레드가 커널스레드의 서비스를 받아서 서로 매핑 시켜서 처리하고, 반납하고 반복
=> 여러개의 사용자 수준 쓰레드를 하나의 커널 쓰레드에 매핑
하나의 사용자 쓰레드가 블록되면 전체 프로세스가 봉쇄됨
다중 쓰레드가 다중 처리기에서 수행되도 병렬로 작동 불가능
일대일 모델(One-to-One Model)
각각의 사용자 쓰레드가 각각의 커널 쓰레드에 매핑
하나의 쓰레드가 블록되어도 다른 쓰레드가 수행 가능하기 때문에 많은 병렬성 제공
다중 처리기에서 다중 쓰레드가 병렬로 수행되는 것을 허용
사용자 쓰레드를 생성할 때 커널 쓰레드도 생성되기 때문에 응용 프로그램의 성능이 저하됨
다대다 모델(Many-to-Many Model)
여러 개의 사용자 수준 쓰레드를 그보다 작거나 같은 수의 커널 쓰레드로 매핑함
하나의 사용자 쓰레드가 블록되어도 다른 사용자 쓰레드를 실행 시킬수 있음 (병렬성)
개발자가 필요한 만큼의 사용자 쓰레드를 생성할 수 있음
두 수준 모델(Two-Level Model)
다대다 모델의 변형으로 많은 사용자 쓰레드를 적거나 같은 수의 커널 쓰레드로 매핑시키는 것을 유지하지만 하나의 사용자 쓰레드가 하나의 커널 쓰레드에 종속되도록 함
thread library
프로그래머에게 쓰레드를 생성하고 관리하기 위한 API를 제공
thread를 creating 하고 managing(생성 종료 슬립.)
커널 지원없이 사용자 공간에서만 라이브러리를 제공
운영체제에 의해 지원되는 커널 수준 라이브러리를 구현
PISIX Pthreads(리눅스에서 많이)
Windows thread(윈도우에서)
Java thread(jvm이니까 위도우면 윈도우 스레드, 리눅스면 PISIX 스레드 사용, 운영체제에 종속적) :
사용자 수준 쓰레드로 간주
JVM은 운영체제에 따라서 다중 쓰레드 모델을 다르게 매핑시킨다.
Windows 계열에서는 다중 쓰레드 모델로 일대일 모델이다.
다대다 모델을 사용하는 운영체제에서는 쓰레드들이 다대다 모델에 맞게 매핑될 수 있
Pthreads
POSIX(IEEE 1003.1c)가 쓰레드 생성과 동기화를 위해 제정한 표준 API사용자 수준 쓰레드로 간주, JVM은 이러한 쓰레드 관리를 수행한다.
void * runner == public void run()같은 함수
pthread_create == new Thread 같은거
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
/* the data shared by the threads */
int sum;
/* thread call this function */
void * runner(void *param); // runner 함수
int main(int argc, char *argv[])
{
pthread_t tid; // thread identifier
pthread_attr_t attr; // thread attributes
pthread_attr_init(&attr);
pthread_create(&tid, &attr, runner, argv[1]);
//new Thread 같은거
//runner 함수 넣어줌
pthread_join(tid, NULL);//대기
printf("sum = %d\n", sum); // runner끝나면 sum 출력
}
void *runner(void *param) // *param에 argv[~] 넘어옴
{
int i, upper = atoi(param);
sum = 0;
for (i = 0; i <= upper; i++)
sum += i;
pthread_exit(0);
}thread fork 해서 프로세스가 생성되고
create pthread에 의해 pthread 생성
#include <stdio.h>
#include <unistd.h>
#include <wait.h>
#include <pthread.h>
int value = 0;
void * runner(void *param); //runner
int main(int argc, char *argv[])
{
pid_t pid;
pthread_t tid;
pthread_attr_t attr;
pid = fork(); // fork
if (pid == 0) { // child process
//create 하고 join 함 두개의 스레드 생김
pthread_attr_init(&attr);
pthread_create(&tid, &attr, runner, NULL);
pthread_join(tid, NULL);
//스레드 만들고 join해줌, runner가 끝날때까지 대기
//runner에 의해 value=5가 된다.
printf("CHILD: value = %d\n", value); // LINE C
//5출력
}
else if (pid > 0) { // parent process
wait(NULL);
printf("PARENT: value = %d\n", value); // LINE P
// 자식으 value가 5인데 부모는 복제하지 않았던
// value값이니까 얘는 0임
}
}
void *runner(void *param)
{
value = 5;
pthread_exit(0);
} => 포크를 통해 두 프로세스는 value를 공유안하고 분리가 됨 (부모0 자식 5)
, 두 개의 스레드는 데이터를 공유한다.
Implict Threading
멀티 코어 시스템에서의 멀티스레딩 설계,
애플리케이션 개발자에게 너무 어려우므로 컴파일러 및 런타임 라이브러리한테 대신 시킴
Thread Pools
프로세스를 시작할때 일정한 수의 스레드를 생성해두는 것
1.웹서버는 요청을 받으면 스레드를 생성하는것이 아닌 사용중이지 않은 스레드에 요청을 수행하도록 한다.
2.만약 모든 스레드가 사용중이라면 사용 가능한 스레드가 생길때까지 작업을 대기한다.
여러개의 스레드를 스레드 풀에다가 저장해 놓고, 필요하면 하나 끄집어가지고 thread 돌리겠다.
new Thread를 프로그래머가 하지말자, thread pool.getThread같은걸 제공한다. 미리 만들어 놓고 getThread하면 리턴해주고 없으면 기다리라하면됨
thread pool이란걸 따로 만들어서 서비스를 제공해주는 라이브러리 만들자
Fork & Join
하나 이상의 자식 스레드를 fork한 다음 자식의 종료를 기다린 후 join하고 그 시점 부터 자식의 결과를 확인하고 결합한다.
explicit 스레딩을 implicit 스레딩하게 쓸 수 있다.
OpenMP
컴파일러 지시어를 주어서 C/C++ 에서 병렬처리 할 수 있다.
Grand Central Dispatch(GCD)
macOS 나 iOS에서 사용
OpenMP
parallel rigion만 우리가 identify 지정해주면 코드블록을 알아서 병렬적으로 실행시켜주자.
컴파일러에게 일을 시킨다. (x 라이브러리)
그 부분을 OpenMP runtime library가 그 부분을 병렬로 스레드로 만들어준다.
#pragma omp parallel :이 블록 안에 있는 코드는 parallel 하게 돌려주세요
#include <stdio.h>
#include <omp.h>
int main(int argc, char *argv[])
{
#pragma omp parallel // compiler directive
{
printf("I am a parallel region.\n");
}
//이 블록 안에 있는 코드는 parallel 하게 돌려주세요
return 0;
}omp_set_num_threads(4) : 스레드갯수 4개로 지정
omp_get_thread_num() : 스레드 번호 반환
#include <stdio.h>
#include <omp.h>
int main(int argc, char *argv[])
{
omp_set_num_threads(4);
#pragma omp parallel
{
printf("OpenMP thread: %d\n", omp_get_thread_num());
// 스레드 번호 출력
}
return 0;
}배열 a값 배열 b값 더해서 배열 c에 넣는다.
#pragma omp parallel for : for문 병렬처리
#include <stdio.h>
#include <omp.h>
#define SIZE 10000000
int a[SIZE], b[SIZE], c[SIZE];
int main(int argc, char *argv[])
{
int i;
for (i=0;i<SIZE;i++)
a[i] = b[i] = i;
#pragma omp parallel for
for (i=0;i<SIZE;i++){
c[i] = a[i] + b[i];
}
return 0;
}=> omp parallel 해준게 더 빨리끝남, 안해줬을때 보다
병렬처리 안했을때: 유저모드시간 + 커널모드시간 = 걸린시간
병렬처리 했을 때: 커널쓰레드가 알아서 다해줌, 오픈MP 라이브러리에 커널스레드가 알아서 처리해줌