Index Range Scan이란?
인덱스의 접근 방법 가운데 가장 대표적인 접근 방법이다. 인덱스를 통해 레코드(1 row)를 한 건만 읽는 경우와 한 건 이상을 읽는 경우는 다른 이름을 구분한다.
SELECT * from employees where first_name between 'Ebbe' and 'Gad';Index Range Scan은 검색해야 할 인덱스의 범위가 결정되었을 때 사용하는 방법이다.
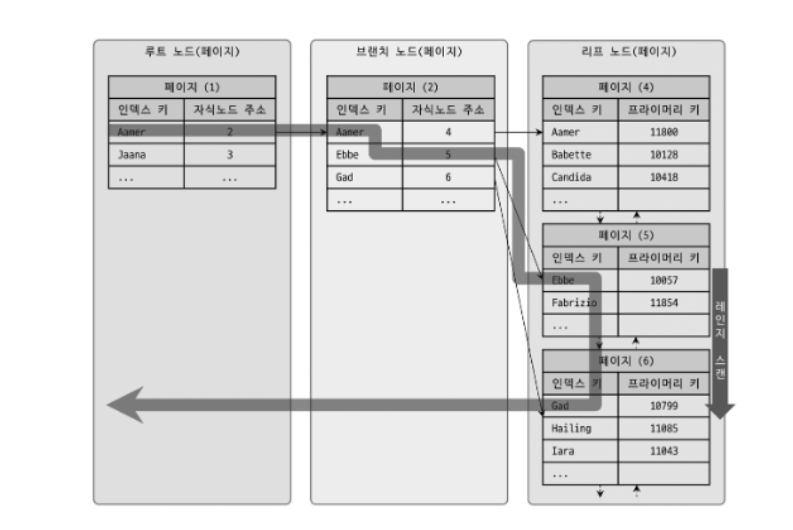
화살표를 보면 알 수 있듯이, 루트 노드에서 비교를 시작해 브랜치 노드를 거치고 최종 리프노드까지 찾아 들어가야만 비로서 시작 지점을 찾을 수 있다.
시작해야 할 위치를 찾으면 그때부터는 리프 노드의 레코드만 순서대로 읽어오면 된다.
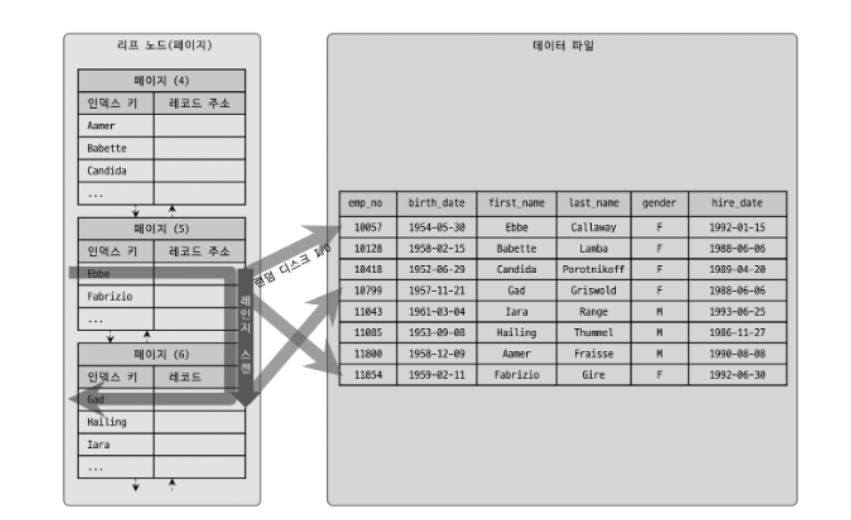
스캔 시작 위치를 검색하고, 그 지점부터 필요한 방향으로 인덱스를 읽어 나가는 과정을 확인할 수 있다. 중요한 것은 어떤 방식으로 스캔하든 관계없이, 해당 인덱스를 구성하는 칼럼의 정순 또는 역순으로 정렬된 상태로 레코드를 가져온다는 점이다.
즉, 인덱스를 스캔하는 방식과 관계없이 데이터베이스에서 데이터를 가져올 때, 인덱스의 정렬 순서를 따르게 된다는 것이다.
예를 들어, 인덱스가 이름을 기반으로 정렬되어 있다면, 데이터베이스에서 데이터를 가져올 때 이름 순으로 정렬된 상태로 결과가 반환된다. 이는 인덱스 스캔 방식과 관계없이 해당 인덱스의 정렬 순서에 따라 결과가 반환된다는 것을 강조한다.
또한 인덱스의 리프 노드에서는 검색 조건에 일치하는 건들은 데이터 파일에서 레코드를 읽어오는 과정이 필요하다는 것이다. 이때, 리프 노드에 저장된 레코드 주소로 데이터 파일의 레코드를 읽어오는데, 레코드 한건 단위로 I/O가 일어난다.
위의 그림처럼 3건의 레코드가 검색 조건에 일치했다고 가정하면, I/O가 최대 3번 필요하다. 그래서 인덱스를 통해 데이터 레코드를 읽는 작업은 비용이 많이 드는 작업으로 분류된다.
인덱스를 통해 읽어야 할 데이터 레코드가 20~25%를 넘으면 인덱스를 통한 읽기보다 테이블의 데이터를 직접 읽는 것이 더 효율적인 처리 방식이다.
어떻게 보조 인덱스로 Index Range Scan이 가능할까?
앞에서 보조 인덱스는 정렬이 안된다고 알고 있는데, 왜 Index Range Scan이 되는지 질문이 나올 수 있다고 생각한다.
Index Range Scan은 정렬이 되지 않는다면 불가능하기 때문이다.
보조 인덱스를 사용하여 데이터에 접근하려면, 먼저 보조 인덱스를 통해 주 키 값을 찾고, 그 후 주 인덱스를 사용하여 실제 데이터에 접근해야 한다.
예제
데이터베이스에 '사용자' 테이블이 있다고 가정하자. 이 테이블에는 각 사용자의 ID(주 키)와 이름이 있다.
데이터
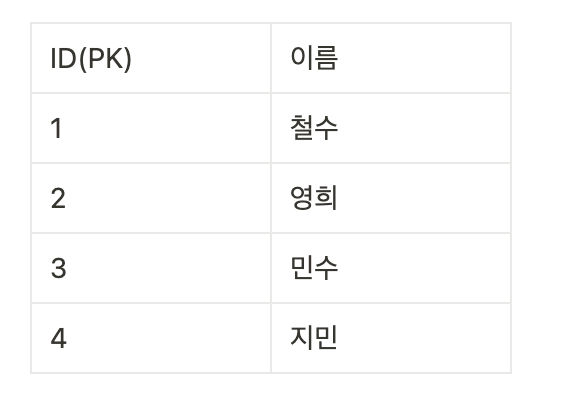
여기서 이름을 빠르게 검색하기 위해 이름에 대한 보조 인덱스를 만들어보자.
이 보조 인덱스는 이름에 따라 정렬된다.
보조 인덱스
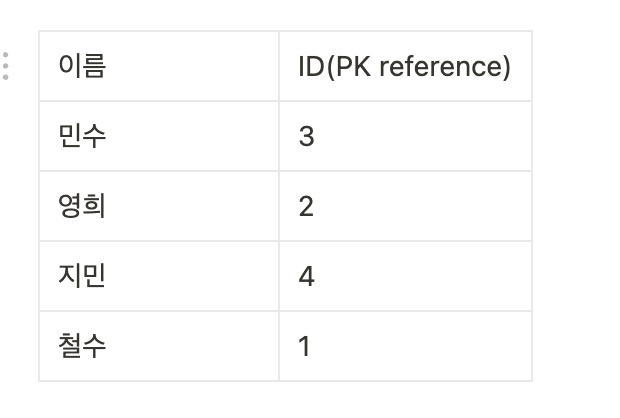
보조 인덱스는 "이름"에 따라 정렬되어 있다. 그러나 보조 인덱스에는 실제 데이터(사용자 정보)가 저장되어 있지 않다. 대신, 각 이름 옆에 해당 사용자의 ID(주 키)가 저장되어 있다. 이 ID는 주 인덱스(또는 데이터 테이블)에서 해당 사용자의 정보를 찾기 위한 참조이다.
따라서 이름으로 사용자를 검색할 때, 보조 인덱스에서 이름을 먼저 찾는다. 그 다음, 해당 이름 옆에 ID를 사용하여 주 인덱스에서 실제 사용자 정보를 찾는다.
인덱스 제거
인덱스를 제거할 때에도 순서가 있습니다.
- 외래키가 있다면 먼저 외래키부터 제거!
클러스터 인덱스와 보조 인덱스가 섞여 있을 때에는 보조 인덱스를 먼저 제거하는 것이 좋다. 왜냐하면, 클러스터형 인덱스를 제거하면 데이터를 재구성하기 때문이다.
drop index idx_member_mem_name on member;
drop index idx_member_addr on member;
drop index idx_mem_number on member;마지막으로 기본 키 지정으로 자동 생성된 클러스터형 인덱스를 제거한다.
alter table member;
drop primary key;만약 테이블이 다른 테이블과 외래키 관계를 가질 경우 다음과 같은 에러가 난다.

그래서 외래 키 관계를 제거해줘야 한다.
관계를 제거하기 전에 외래 키의 이름을 알아야 한다.
information_schema.referential_constraints
는 시스템 테이블로, 데이터베이스의 외래 키 제약 조건에 대한 정보를 제공한다.
select table_name, constraint_name
from information_schema.referential_constraints
where constraint_schema = 'market_db';위의 명령어는 'market_db' 데이터베이스의 모든 외래키 제약 조건의 테이블 이름과 제약 조건 이름을 검색하는 쿼리이다.
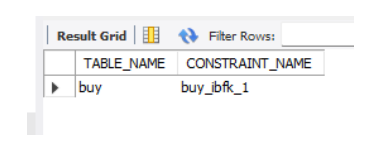
만약 member 테이블에만 엮인 테이블과 fk만 알고 싶으면?
SELECT
rc.table_name AS referencing_table,--'member' 테이블을 참조하는 테이블
rc.constraint_name AS fk_constraint_name,-- 해당 테이블의 외래키 제약 조건 이름
rc.column_name AS referencing_column -- 'member'테이블을 참조하는 칼럼
FROM
information_schema.key_column_usage AS rc
WHERE
rc.referenced_table_schema = 'market_db' AND
rc.referenced_table_name = 'member';이제 외래 키를 알았으니 제거해보도록 하자.
alter table buy
drop foreign key buy_ibfk_1;
alter table member
drop primary key;이번 포스팅까지 해서, 인덱스의 종류와 구조, 및 실습을 진행해 이해해 보았다. 다음 포스팅에서는 인덱스를 효과적으로 사용하는 방법에 대해서 공부해볼 예정이다.
