인덱스 실습
지금까지는 인덱스의 구조와 종류에 대해서 알아보았다. 이제 실습으로 직접 인덱스를 생성해보고, 분석해보는 시간을 가져보자.
인덱스 생성 문법
CREATE [UNIQUE] INDEX 인덱스_이름
ON 테이블_이름 (열_이름) [ASC|DESC]CREATE INDEX로 생성되는 인덱스는 보조 인덱스 이다.
UNIQUE: 중복이 안되는 고유 인덱스를 만들 때 사용하는데, 생략하면 중복이 허용된다. CREATE UNIQUE로 인덱스를 생성하려면 기존에 입력한 값들에 중복이 있으면 안된다. 그리고 인덱스를 샐성한 후에 입력되는 데이터와도 중복될 수 없다. 예를 들어 이름 같이 중복 가능한 것은 UNIQUE로 지정하면 안된다.
ASC|DESC: 인덱스를 오름차순 또는 내림차순으로 만들어준다. 기본은 ASC로 만들어지며, DESC로 만드는 경우는 거의 없다.
인덱스 제거 문법
DROP INDEX 인덱스_이름 ON 테이블_이름;주의할 점은 기본 키, 고유 키로 자동 생성된 인덱스는 DROP INDEX로 제거하지 못한다는 점이다.
ANALYZE TABLE
생성한 인덱스를 실제로 적용시키려면 ANALYZE TABLE문으로 테이블을 분석/처리 해줘야 한다.
ANALYZE table member;
show table status like 'member';ANALYZE TABLE?
ANALYZE TABLE 명령은 데이터베이스 관리 시스템(DBMS)에서 사용하는 명령 중 하나다. 이 명령은 주로 테이블의 데이터 분포 및 통계를 수집하고 업데이트하는 데 사용된다. 인덱스를 최적으로 사용하려면 쿼리 최적화기가 테이블의 데이터 분포에 대한 정보를 알아야 한다.
ANALYZE TABLE의 주요 목적은 다음과 같다.
-
통계 정보 수집: ANALYZE TABLE을 실행하면 DBMS는 테이블의 데이터를 스캔하여 통계 정보를 수집한다. 이 정보는 행 수, 유니크한 값 수, NULL값의 수등을 포함할 수 있다.
-
쿼리 최적화: 데이터베이스는 쿼리를 실행할 때 이 통계 정보를 사용하여 최적의 실행 계획을 생성한다. 예를 들어, 어떤 인덱스를 사용할지, 어떤 순서로 테이블을 조인할지 등의 결정을 내릴 때 이 통계 정보가 중요하다.
-
인덱스의 효율성: 새로운 인덱스를 생성하거나 기존 인덱스를 수정한 후에는 ANALYZE TABLE을 실행하여 인덱스의 통계 정보를 최신 상태로 유지하는 것이 좋다. 이렇게 하면 쿼리 최적화기가 인덱스를 더 효과적으로 사용할 수 있다.
즉, 인덱스를 생성하거나, 수정하면, 인덱스의 최신 통계정보를 데이터베이스에 제공해 쿼리를 효과적으로 실행해야 한다. 그러므로 ANALYZE TABLE을 실행해야 한다.
왜 ANALYZE TABLE을 해야할까?
이 현상은 특히 InnoDB 스토리지 엔진을 사용하는 MySQL에서 흔히 관찰되는 것이다. SHOW TABLE STATUS의 index_length는 디스크 상에서 인덱스가 차지하는 공간의 크기를 나타낸다. 그러나 InnoDB는 일부 작업을 지연 처리하여 효율성을 높이려고 한다. 인덱스 생성도 이러한 작업 중 하나일 수 있다.
이러한 지연 처리의 결과로, 보조 인덱스를 생성한 직후에 SHOW TABLE STATUS를 실행하면 index_length가 0으로 표시될 수 있다.
실제로 인덱스를 생성했지만, 그 크기는 아직 반영되지 않은 것이다.
ANALYZE TABLE을 실행하면 InnoDB는 테이블의 통계 정보를 강제로 업데이트한다. 이 과정에서 인덱스의 실제 크기도 계산이 되어 index_length 값이 업데이트된다.
따라서, ANALYZE TABLE후에 SHOW TABLE STATUS를 실행하면 index_length값이 올바르게 업데이트되어 표시되는 것이다.
DB안에는 인덱스가 실제로 적용되었지만, 이를 통계로 업데이트해서 우리가 보려면 ANALYZE TABLE을 해야 한다.
실습
다음과 같은 테이블이 있다고 가정해보자.
CREATE TABLE member
( mem_id CHAR(8) NOT NULL PRIMARY KEY,
mem_name VARCHAR(10) NOT NULL,
mem_number INT NOT NULL,
addr CHAR(2) NOT NULL,
phone1 CHAR(3),
phone2 CHAR(8),
height SMALLINT,
debut_date DATE
);
INSERT INTO MEMBER VALUES('TWC','트와이스',9,'서울','02','11111111',167,'2015.10.19');
INSERT INTO MEMBER VALUES('BLK','블랙핑크',4,'경남','055','22222222',163,'2016.08.08');
INSERT INTO MEMBER VALUES('WMN','여자친구',6,'경기','031','33333333',166,'2015.01.15');
INSERT INTO MEMBER VALUES('OMY','오마이걸',7,'서울',NULL,NULL,160,'2015.04.21');
INSERT INTO MEMBER VALUES('GRL','소녀시대',8,'서울','02','44444444',168,'2007.08.02');
INSERT INTO MEMBER VALUES('ITZ','잇지',5,'경남',NULL,NULL,167,'2019.02.12');
INSERT INTO MEMBER VALUES('RED','레드벨벳',4,'경북','054','55555555',161,'2014.08.01');
INSERT INTO MEMBER VALUES('APN','에이핑크',6,'경기','031','77777777',164,'2011.02.10');
INSERT INTO MEMBER VALUES('SPC','우주소녀',13,'서울','02','88888888',162,'2016.02.25');
INSERT INTO MEMBER VALUES('MMU','마마무',4,'전남','061','99999999',165,'2014.06.19');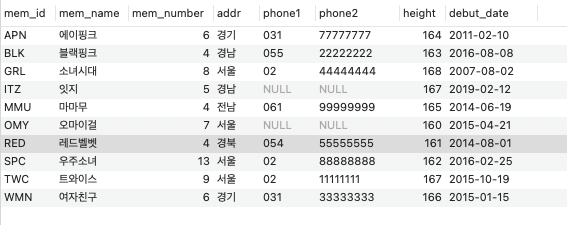
SHOW INDEX from member;
위와 같이 PK를 하나 두어 테이블을 생성하면, 자동으로 클러스터 인덱스만 생성되고, 보조 인덱스는 하나도 생성이 안되었다.
이번에는 STATUS를 통해서 인덱스의 크기를 보면 16K이다.
show table status like 'member';
데이터가 많지 않아서 16KB까지는 필요 없지만, 최소 단위가 1페이지이므로 1페이지에 해당하는 16KB가 할당되어 있음을 확인할 수 있다.
Index_length는 보조 인덱스의 크기인데 member는 현재 보조 인덱스가 없어서 표기되지 않았다.
단순 보조 인덱스 생성
이제 이 테이블에 주소(addr)에 중복을 허용하는 단순 보조 인덱스를 생성해보자. 인덱스의 이름은 idx_member_addr로 지정했다.
CREATE INDEX idx_member_addr
on member (addr);보조 인덱스는 단순 보조 인덱스와, 고유 보조 인덱스로 나뉘는데, 단순 보조 인덱스는 중복을 허용한다.
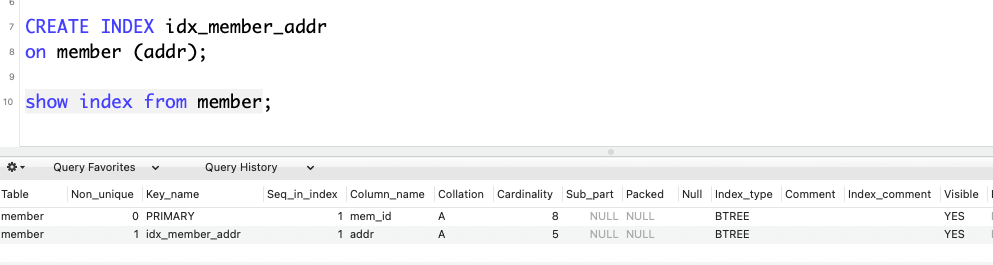
non_unique가 1이므로 중복을 허용한다는 의미이다.
보조 인덱스가 추가되었음을 위의 사진으로 볼 수 있다.

하지만, 전체 인덱스의 크기를 봐보면, index_length가 보조 인덱스의 크기인데, 이상하게도 크기가 0이 나온다.!!
-->analyze table 명령을 입력하면, 통계가 수집되고 업데이트된 정보를 우리가 확인할 수 있다.
보조 고유 인덱스 생성
이제는 고유 보조 인덱스를 생성해보자.
이 테이블에서 고유 보조 인덱스를 생성해볼 만한 열을 찾아보자.
고유 보조 인덱스는 중복을 허용하지 않는다. 회원 이름이 적합해보인다.!!
CREATE UNIQUE INDEX idx_member_name
on member (mem_name);이 상황에서 새로운 데이터를 넣는다고 가정해보자.
INSERT INTO MEMBER VALUES('MOO','마마무',2,'태국','001','99999999',165,'2014.06.19');mem_name이 동일하게 데이터를 넣어보면 에러가 발생한다.

왜냐하면 생성한 고유 보조 인덱스로 인해서 중복된 값을 입력할 수 없기 때문이다.
그래서 절대로 중복되지 않는 값들에만 UNIQUE옵션을 사용해야 한다.
생성된 인덱스의 활용
일단 먼저 그동안 만든 인덱스를 모두 적용시켜보자.
analyze table member;
show index from member;
첫 번째로 전체 조회를 해보자.
select * from member;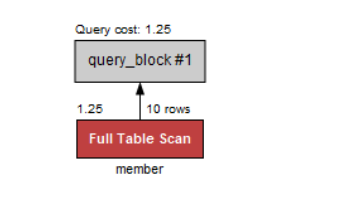
select *은 인덱스를 사용하지 않고 전체를 조회하는 방법이라 FULL TABLE SCAN을 한 것이 확인된다.
이번에는 인덱스가 있는 열을 조회해보자.
select mem_id, mem_name, addr from member;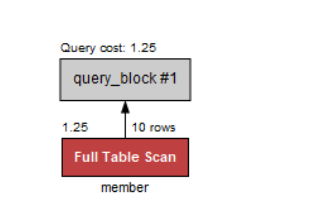
이렇게 열 이름이 select 다음에 나와도 인덱스를 사용하지 않는다.
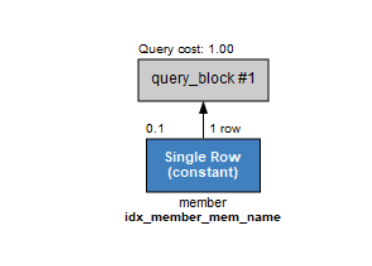
인덱스가 생성된 mem_name 값이 '에이핑크'인 행을 조회해보자.
select mem_id, mem_name, addr from member where mem_name='에이핑크';이번에는 Single_ROW(constant)라고 되어 있다. 이 용어는 인덱스를 사용해서 결과를 얻었다는 의미이다.
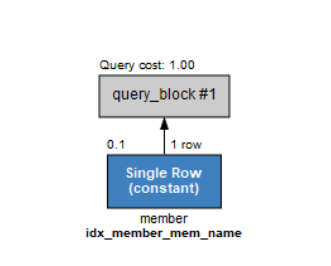
즉,WHERE 절에 열 이름이 들어있어야 인덱스를 사용한다.
숫자의 범위로 조회해보자.
숫자로 된 구성 인원수(mem_number)로 단순 보조 인덱스를 만들어보자.
CREATE INDEX idx_mem_number
on member (mem_number);
analyze table member;인원 수가 7명 이상인 그룹의 이름과 인원수를 조회해보자.
select mem_name,mem_number
from member
where mem_number>=7;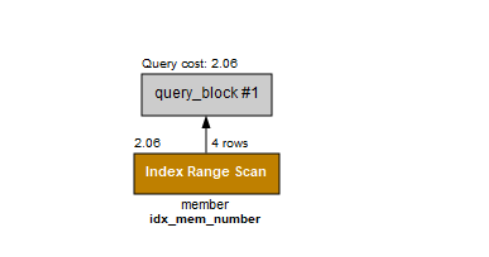
Execution plan을 보면 인덱스를 사용한 것을 알 수 있다.
mem_number >=7과 같이 숫자의 범위로 조회하는 것도 인덱스를 사용한다.
인덱스를 사용하지 않는 경우
인덱스가 있고 WHERE절에 열 이름이 나와도 인덱스를 사용하지 않는 경우도 있다.
인원수가 1명이상인 회원을 조회해보자.
회원은 1명이 이상이므로 모두 조회된다.
select mem_name, mem_number
from member
where mem_number >=1;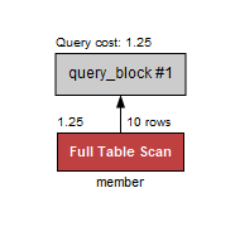
전체 테이블을 검색 한 것을 알 수 있다. 왜나하면 MySQL에서 인덱스 검색보다는 전체 테이블 검색이 낫다고 판단했기 때문이다. 이 경우에는 대부분의 행을 가져와야 하므로 인덱스를 왔다갔다 하는 것보다는 차라리 테이블을 차례대로 읽는 것이 더 효과적이기 때문이다.
인원수(mem_number)의 2배를 하면 14명 이상이 되는 회원의 이름과 인원수를 검색해보자.
select mem_name, mem_number
from member
where mem_numer * 2 >=14;사실 이 SQL은 mem_number>=7이랑 같다.
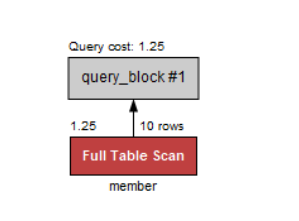
실행해보면 놀랍게도, 전체 테이블을 검색한다.
WHERE 절에 연산이 가해지면 인덱스를 사용하지 않는다.
이런 경우에는 다음과 같이 수정해야 한다.
select mem_name, mem_number
from member
where mem_number >=14/2;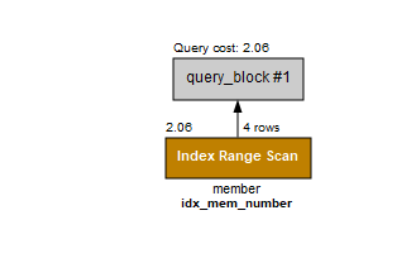
이렇게, where절에 연산을 하지 않도록 수정하면, 인덱스를 사용한다.
따라서 WHERE절에 나온 열에는 아무런 연산을 하지 않는 것이 좋다.
마무리
인덱스에 대해 신기한 사실들을 간단한 실습을 통해서 많이 알 수 있었다.
인덱스를 건다고, 항상 인덱스를 이용하지 않고 데이터베이스가 경우에 따라 FULL SCAN이 더 효율적이라고 판단할 수도 있다는 점이다.
- WHERE절이 있어야 인덱스를 적용해 쿼리 속도를 향상시킬 수 있다는 점
- WHERE절에는 연산을 하면 안된다는 점
- ANALYZE Table을 해야 갱신된 결과를 확인할 수 있다는 점
을 새롭게 알게 되었다.
