
이번 시간에는 @toMany일때 성능 최적화를 하는 방법에 대해 알아보도록 하자.
@toMany 관계는 2가지 방법이 있다.
1. fetch join으로 다 가져오기
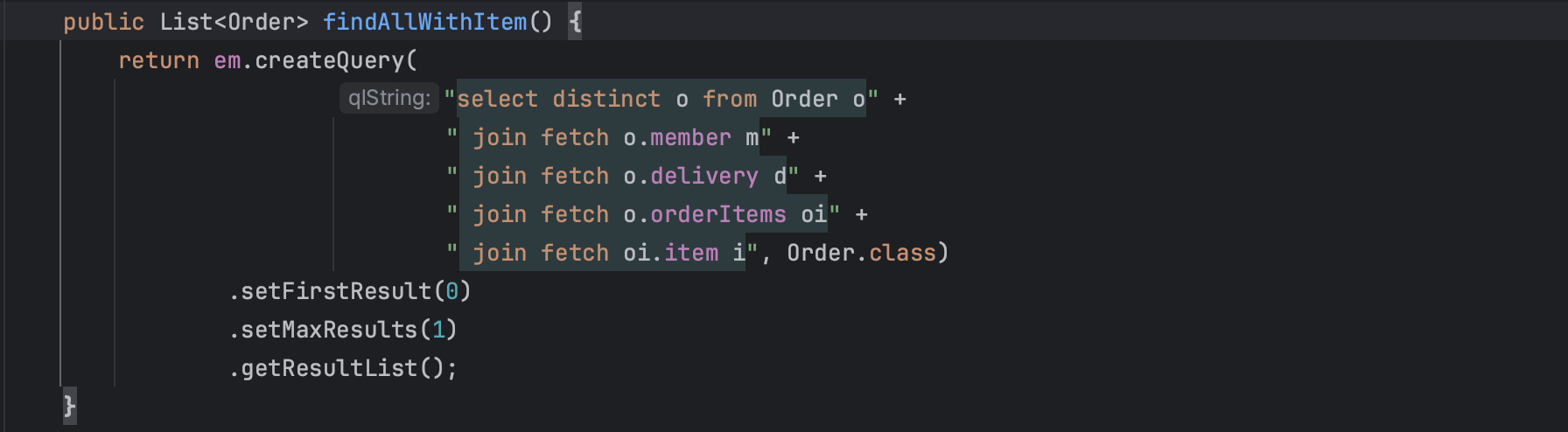
1:N 컬랙션 패치조인은 1번만 가능하다. 1:N:N..일때 계속 컬랙션 패치조인은 안된다.
장점: 한번의 쿼리로 다 가져올 수 있다.
단점:
1. 페이징 처리가 불가능하다.
2. JPA는 이러한 중복을 제거하고 엔티티를 생성하지만, 너무 많은 데이터가 중복되어 메모리에 올라오고, 이는 추가적인 메모리와 처리 시간을 요구한다.
→이유: 1:N 관계를 join하면 N이 중심이 되어 레코드가 쌓인다.
join한 결과를 직접 살펴보자.

쿼리 결과를 확인해 보면, 위와 같이 레코드가 쌓인다.
Order를 기준으로 페이징이 불가능함을 느낄 수 있을 것이다.
이유는 데이터베이스에서 반환된 "행" 수가 엔티티의 수와 일치하지 않기 때문이다.
예를 들어, 페이지당 10개의 Order를 원하지만 각 Order에 5개의 OrderItem이 있는 경우:
Order1, OrderItem1
Order1, OrderItem2
Order1, OrderItem3
Order1, OrderItem4
Order1, OrderItem5
Order2, OrderItem6
Order2, OrderItem7
Order2, OrderItem8
Order2, OrderItem9
Order2, OrderItem10
여기서 setMaxResults(10)을 사용하면 실제로는 두 개의 Order(root entity)만 반환되는 문제가 있다.
이러한 문제를 해결하기 위해서는 Spring이 제공하는 @BatchSize가 있다.
- @batchSize()
Batch size를 적용하는 법은 매우 간단하다.
application.yaml 파일에 아래와 같이 추가한다.
jpa:
hibernate:
ddl-auto: create
properties:
hibernate:
# show_sql: true
format_sql: true
default_batch_fetch_size: 1000 #최적화 옵션
# open-in-view: falsebatch_fetch_size는 보통 100~1000 사이로 설정한다고 한다.
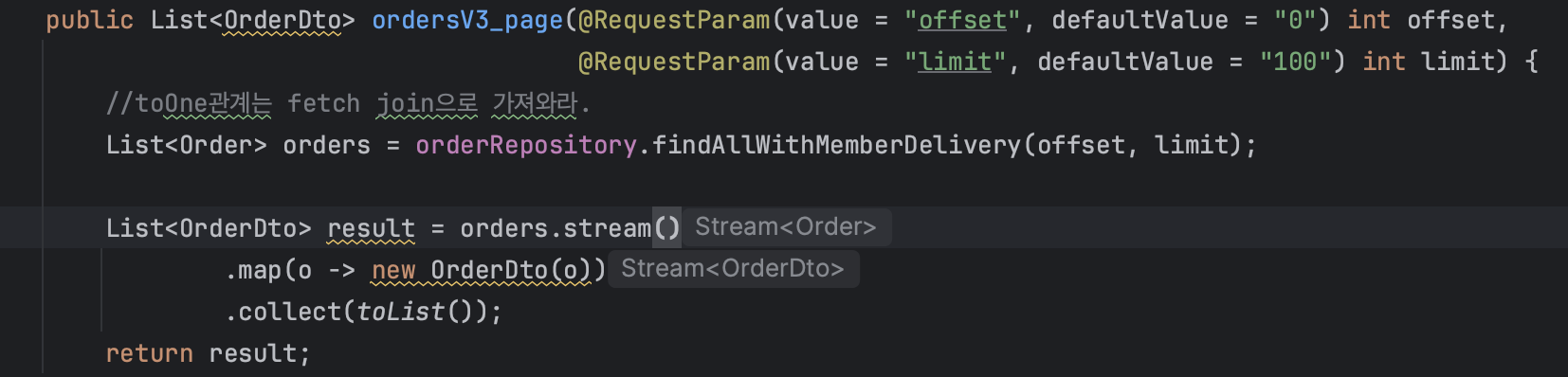
위와 같이 작성하면, 쿼리가 어떻게 나갈까?
- Order와 @toOne으로 연관된 엔티티들까지 fetch join으로 가져오는 쿼리 1번
- orderItem들을 최대 batchsize만큼 한꺼번에 가져오는 쿼리 1번
- Item들을 최대 batchsize만큼 한꺼번에 가져오는 쿼리 1번
=> 3번의 쿼리
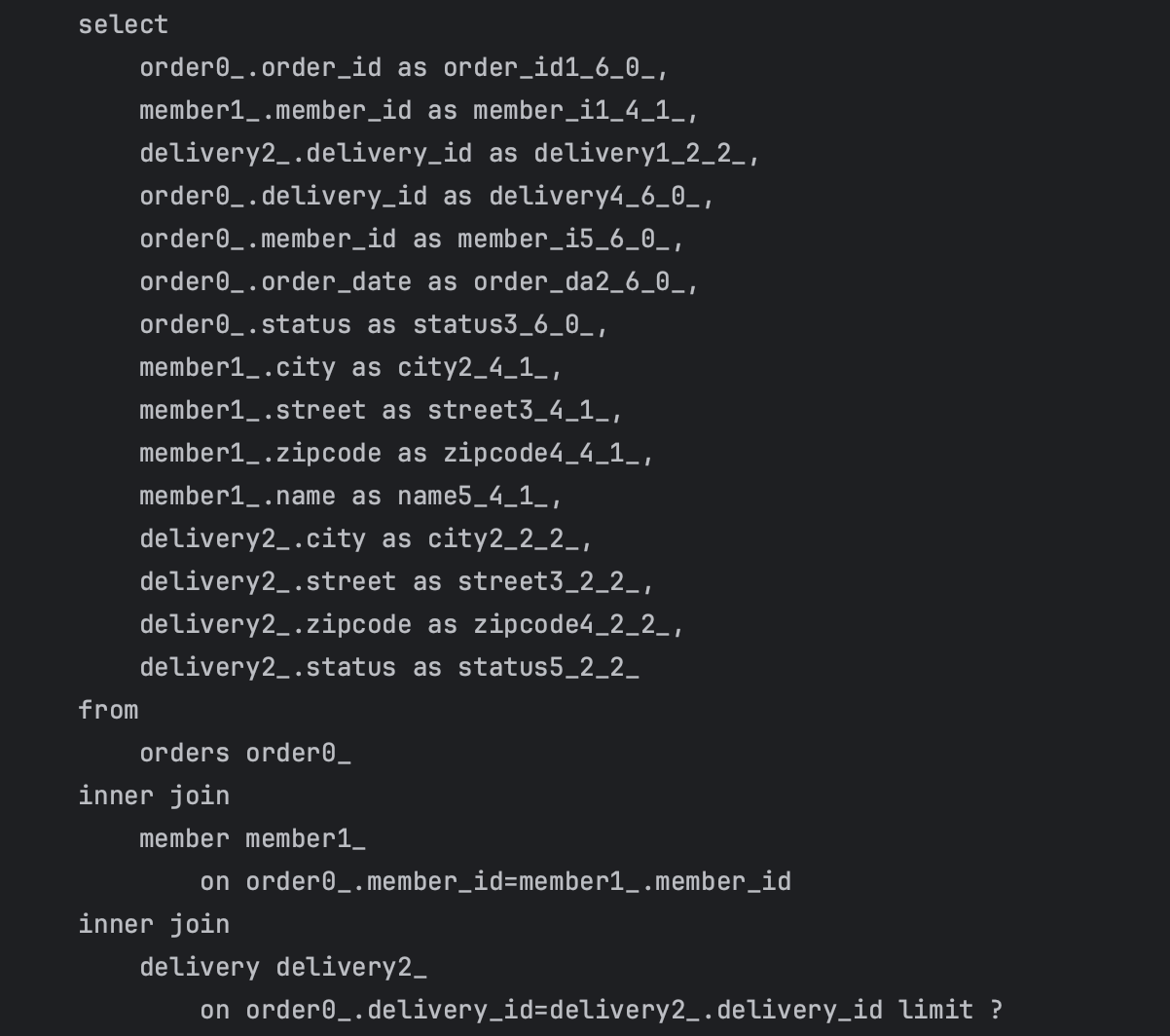
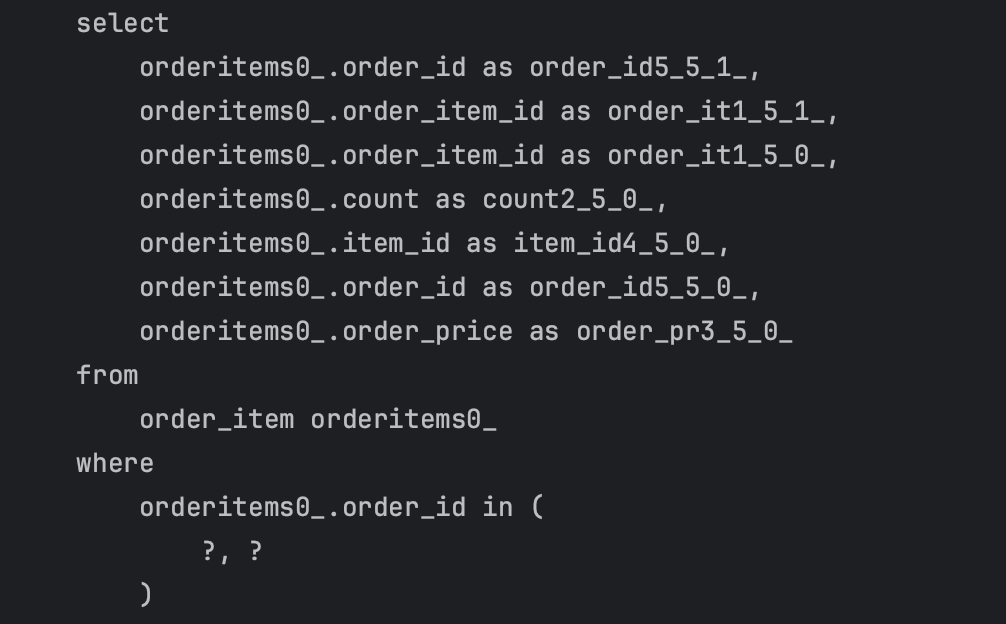
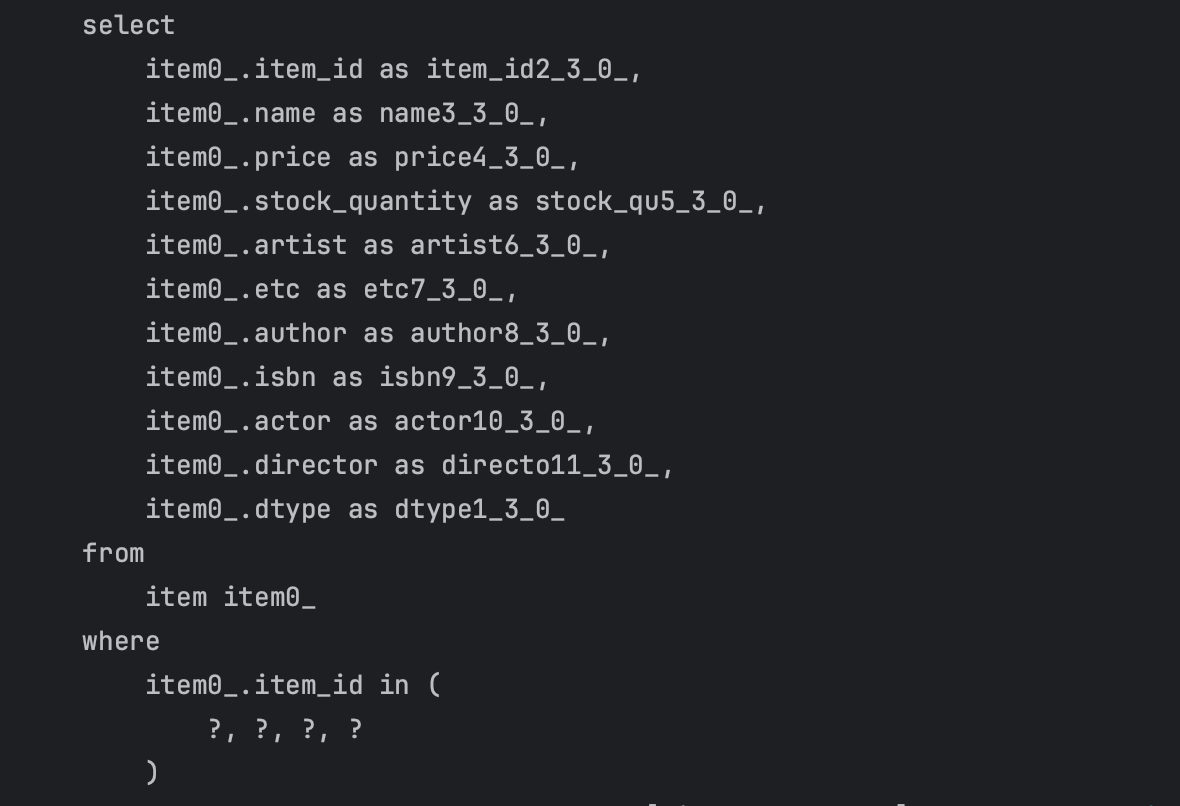
사진들을 통해 총 3번의 쿼리가 나감을 확인할 수 있다.
인상 깊은 점은 in절을 통해서 한번의 쿼리로 한꺼번에 가져온다는 점이다.
이상 1:N 관계일때의 1+N 문제를 해결하는 두 가지 방법에 대해 알아보았다.
