출발
한기영 강사님은 1기부터 지금까지 쭉 해오셨다는데, 이전 기수들은 다 찬양하던데 왜 그런지 알겠다.
강의를 너무 친절하게 해주신다. 무지한 비전공자도 이해하기 쉽게 설명해주신다. 하지만 나는 아니니깐...
노션에 정리하고, 이를 다듬어서 벨로그에 바로바로 업로드하는게 목표였는데, 월요일에 일이 있어서 시간이 부족했다. 일 끝내고 집에 돌아와서 1시간동안 누워있던 침대는 너무 무섭다. 침대의 악마는 아마 가장 강력한 악마중 하나다...
진짜 시작
Chapter 5. 데이터 분석 / 모델링을 위한 데이터 구조
어떠한 비지니스 문제를 해결하려는지 ?
문제 정의 - 이에 따른 해결 방안 갈구 - 해결 완료 ?
데이터 분석 머신러닝 모델링을 하려면 데이터를 특별한 형태로 정리가 되어야 한다
→ 이는 Numpy와 Pandas library에서 제공해주고 있다.
우리가 분석할 수 있는 데이터는 기본적으로 2차원 형태를 띄고있음.
| Label | 열 | ||||
|---|---|---|---|---|---|
| 행 | 분석 단위 | 샘플 | 관측치 | 데이터 건수 | 정보 |
| 변수 | |||||
| 요인 |
numpy - 수치 연산
pandas - 비즈니스 데이터 표현
요약
1. 분석할 수 있는 정보 종류 2가지 : 숫자, 범주
2. 두가지 종류의 정보가 특별한 구조를 가져야 함
- 기본적으로 2차원 배열 형태
- (분석, 모델링을 위한) 데이터 구조 다루는 패키지 : numpy, pandas
Chapter 6. Numpy 기초
리스트는 데이터 분석분야에서 한계가 있음
값의 집합 개념이 아닌 수학적 계산과 대량의 데이터 계산이 빠르게 가능해야함
그래서 Numpy (Numerical Python) 라이브러리가 만들어짐
→ C언어 기반, 백터 행렬 연산, Array 단위로 데이터 관리
이제 Numpy를 써보자
import numpy as np # import 라이브러리 as 별칭
arr = np.array([1, 2, 3, 4, 5])
from numpy as array # numpy에서 array 함수만 쓰기
a = array([1, 2, 3, 4, 5]- Numpy 용어 정리
- Axis : 배열의 각 축
- Rank : 축의 갯수 (차원)
- shape : 축의 길이
3차원 arr 경우
x, y 2차원 배열이 z개라고 읽음
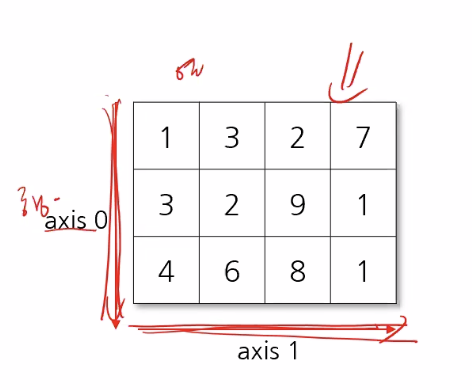
이미 있는 리스트를 Numpy 배열로 만들수도 있고 방법은 다양함
- Numpy 배열 속성
ndim : 차원
shape : 튜플로 배열 형태
dtype : 요소의 자료형 (배열은 자료형 단일임)```python import numpy as np arr = np.array([1,2,3], [4,5,6], [7,8,9]) print(arr.ndim, arr.shape, arr.shape) # 3 (2, 3, 3), int64 // shpae은 차원, 행, 열 순서로 나옴 ```
np.array([…]).reshape()
배열의 형태를 변환하는 메소드```python # reshpae() a = np.array([[11, 12, 13, 14], [15, 16, 17, 18], [19, 20, 21, 22]]) b = a.reshpae(4, -1) # -1로 나머지 부분을 채울 수 있다. (== (4, 3) """ [[11, 12, 13], [14, 15, 16], [17, 18, 19], [20, 21, 22]] """ ```
- 배열 인덱싱과 슬라이싱
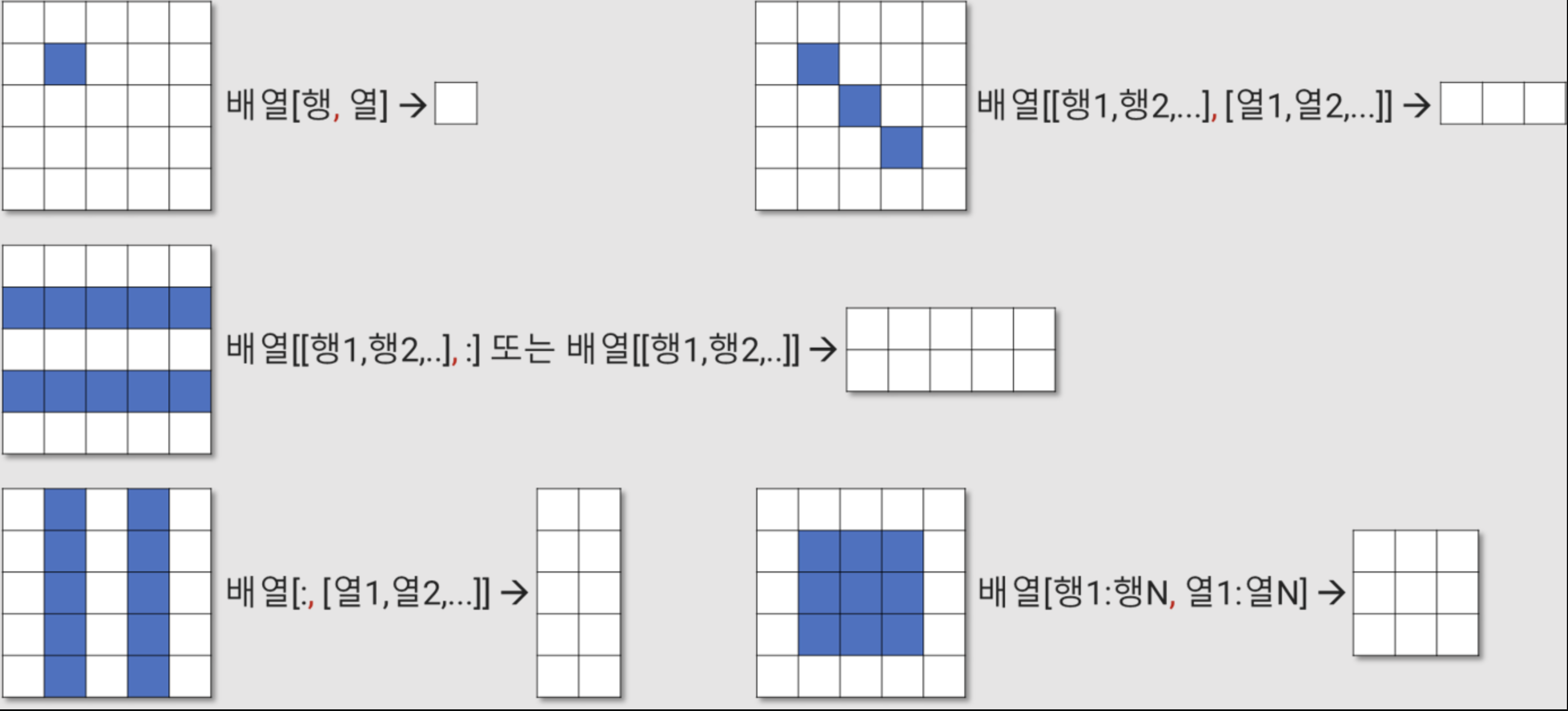
```python
a = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
a([0], [1]] # list 타입으로 출력 []로 감쌌잖아요 [2]
a[0,1] # int형으로 출력 2
# 넘파이는 슬라이싱도 지원함
a[1, :] # [4, 5, 6]
```- 배열 조건 조회
배열에 인덱스 대신 조건을 입력하면 조건에 부합한 요소만 조회한다.
→ 조회한 결과는 1차원 배열```python score= np.array([[78, 91, 84, 89, 93, 65], [82, 87, 96, 79, 91, 73]]) print(score[score >= 90]) # 91, 93, 91 ```
- 배열의 연산
```python
x = np.array([[1, 2], [3, 4]])
y = np.array([[5, 6], [7, 8]])
x + y
x - y
x * y
x / y
x ** y
np.sqrt(x)
```- Numpy method axis를 생략하면 전체 집계
axis = 0 : 열 기준 집계
axis = 1 : 행 기준 집계-
np.sum(arr, axis)orarr.sum(axis): 원소들의 합 -
np.max(arr, axis): 원소들의 최댓값 -
np.min(arr, axis): 원소들의 최솟값 -
np.mean(arr, axis): 원소들의 평균 -
np.std(arr, axis): 원소들의 표준편차 -
np.argmax(arr, axis),np.argmin(arr, axis):
axis를 생략하면 전체 배열 중 최대/최소를 return
axis로 행 방향, 열 방향 최대/최소를 구할 수 있다a = np.array([[1,5,7], [2,3,8]]) # 전체 중에서 가장 큰 값의 인덱스 print(np.argmax(a)) # 행 방향 최대값의 인덱스 print(np.argmax(a, axis = 0)) # 열 방향 최대값의 인덱스 print(np.argmax(a, axis = 1)) """ 출력 [[1 5 7] [2 3 8]] 5 [1 0 1] [2 2] """ -
np.where(조건문, True일 때 값, False일 때 값)a = np.array([1, 3, 2, 7]) np.where(a > 2, 1, 0) # array([0, 1, 0, 1]) -
np.zeros(value): 0으로 채워진 배열을 생성한다
value는 정수(1차원) 혹은 튜플(다차원)을 넣을 수 있다. -
np.ones(value): 1로 채워진 배열 zeros와 원리는 같다. -
np.full(value, 특정 값): 특정 값으로 채워진 배열 -
np.eye(size): size(1이상 자연수)크기 만큼 정방향 행렬을 배열로 생성 -
np.random.random(tuple): tuple을 매개변수로 받아 튜플 크기의 랜덤값으로 채운 배열 생성 -
Numpy method
axis를 생략하면 전체 집계
axis = 0 : 열 기준 집계
axis = 1 : 행 기준 집계 -
np.sum(arr, axis)orarr.sum(axis): 원소들의 합 -
np.max(arr, axis): 원소들의 최댓값 -
np.min(arr, axis): 원소들의 최솟값 -
np.mean(arr, axis): 원소들의 평균 -
np.std(arr, axis): 원소들의 표준편차 -
np.argmax(arr, axis),np.argmin(arr, axis):
axis를 생략하면 전체 배열 중 최대/최소를 return
axis로 행 방향, 열 방향 최대/최소를 구할 수 있다a = np.array([[1,5,7], [2,3,8]]) # 전체 중에서 가장 큰 값의 인덱스 print(np.argmax(a)) # 행 방향 최대값의 인덱스 print(np.argmax(a, axis = 0)) # 열 방향 최대값의 인덱스 print(np.argmax(a, axis = 1)) """ 출력 [[1 5 7] [2 3 8]] 5 [1 0 1] [2 2] """ -
np.where(조건문, True일 때 값, False일 때 값)a = np.array([1, 3, 2, 7]) np.where(a > 2, 1, 0) # array([0, 1, 0, 1]) -
np.zeros(value): 0으로 채워진 배열을 생성한다
value는 정수(1차원) 혹은 튜플(다차원)을 넣을 수 있다. -
np.ones(value): 1로 채워진 배열 zeros와 원리는 같다. -
np.full(value, 특정 값): 특정 값으로 채워진 배열 -
np.eye(size): size(1이상 자연수)크기 만큼 정방향 행렬을 배열로 생성 -
np.random.random(tuple): tuple을 매개변수로 받아 튜플 크기의 랜덤값으로 채운 배열 생성
-
Chapter 7. Pandas 기초 (1)
Pandas를 시작해 보자
import pandas as pd # 라이브러리 호출Pandas는 곧 DataFrame을 사용하려고 쓴다고 본다
데이터를 처리, 조회, 분석하는데 효율적이고 우리가 흔히 쓰는 excel 형태다.
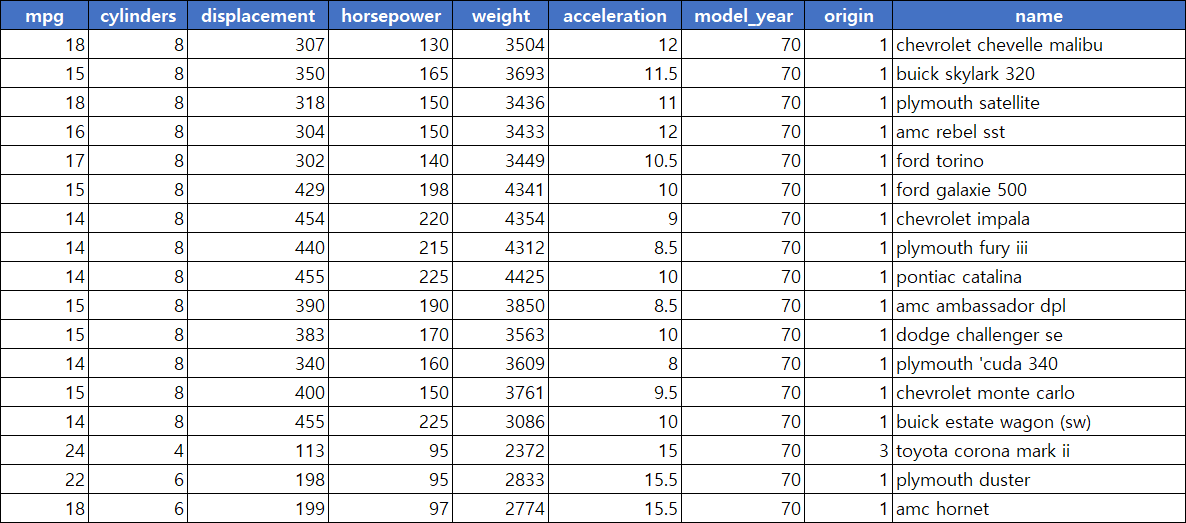
- DataFrame 데이터 프레임은 2차원 (행, 렬)로 이루어져 있다.
!https://raw.githubusercontent.com/Jangrae/img/master/dataframe_sample.png행렬 헷갈리면 입모양으로 기억해보자
행 - 입모양이 가로로 길게
열 - 입모양이 세로로 길게
- Series 시리즈는 하나에 정보에 대한 데이터들의 집합으로 데이터 프레임에서 하나의 열이라고 보면 된다. (1차원)
ex ) 위 사진에서 mpg 열, origin 열 등등…
{kind=link}
이제 코드로 보자
import pandas as pd
# "그 데이터 셋" 타이타닉
path = "https://raw.githubusercontent.com/DA4BAM/dataset/master/titanic_simple.csv"
df = pd.read_csv(path)이제 df를 활용 해보자
- DataFrame Method
df.head(int): 상위 데이터 확인df.tail(int): 하위 데이터 확인df.shape: 데이터 프레임의 크기df.values: 값 정보 확인(저장하면 2차원 Numpy 배열이 됨)df.columns: 열 정보 확인df.dtypes: 열 자료형 확인df.info(): 열에 대한 상세한 정보 확인 - 데이터 타입 string의 경우 objectdf.describe(): 기초통계정보 확인 - 개수, 평균, 표준편차, 최소값, 사분위값을 표시df.sort_values(by = '열 이름', ascending): 특정 열을 기준으로 정렬
여러 열 기준으로 활용 가능하고 (리스트로 매개변수)ascending는 True / False 기준으로 내림차순 오름차순으로 정렬함 (디폴트는 True - 오름차순)```python df.sort(by = ['age', 'Pclass'], ascending = [True, False]) ```df.reset_index(drop): 뒤죽박죽 되어있는 Index 번호를 초기화 해준다.
drop은 True/False로 False로 설정 시 기존 인덱스를 새로운 컬럼으로 추가한다. (디폴트는 False)df['열 이름'].unique(): 열의 데이터들의 고유값을 배열로 returndf['열 이름'].values_count(): 고유값과 갯수를 Series로 return
Chapter 8. Pandas 기초 (2)
오늘 가장 중요한 챕터
- 데이터 프레임 특정 열 조회
df['열 이름']
df.열 이름
data[['열 이름']]무슨 차이냐면… 마지막 줄 빼고 Series로 return한다.
마지막 줄은 DataFrame으로 return한다.
→ DataFrame으로 받는다면 여러 메소드를 또 이용할 수 있다 ~~~ Series도
- 조건으로 조회
-
df.loc[조건]: 입력한 조건에 부합하는 데이터만 조회할 수 있다df['열 이름'] > 10 # 해당 열의 bool 값을 Series return df.loc[data['열 이름'] > 10] # 조건에 부합하는 열의 행을 DataFrame return여러 조건을 붙일수도 있다
df.loc[(data['열 이름'] > 10) & (data['열 이름'] == 4)] df.loc[(data['열 이름'] > 10) | (data['열 이름'] == 4)] # and나 or말고 비트연산자 써야함 -
조건이 점점 많아지면 가독성을 해칠 수 있다. 그럴 땐 이 메소드를 써보자
df['열 이름'].isin([value1, value2, ...]): 매개변수인 list의 값과 같은 것들만 bool 타입 Series로 리턴한다.df['열 이름'].between(value1, value2, inclusive): value1 ≤ ? ≤ value2에 부합하는 값만 bool 타입 Series로 리턴한다.inclusive 매개변수 (디폴트는 ‘both)
’left’ : value1 ≤ ? < value2
’right : value1 < ? ≤ value2
’both’ : value1 ≤ ? ≤ value2
’neither’ : value1 < ? < value2
-
# isin(), between 예제
df.loc[(df['열 이름'].insin([values...])]
df.loc[(df['열 이름'].between([value1, value2, inclusive = "neither"])]- 데이터 프레임 집계 데이터 프레임도 특정 열에 대해 집계 함수를 사용할 수 있다.
max(),min(),mean(),median()로 여러 열을 집계하면 Series로 return
열들의 평균이나 여러 값들을 이렇게 구할 수 있다. 그리고특정 열의 값에 대한 다른 데이터를 집계하고 싶을 땐df['특정 열'].max() df['특정 열'].min() df['특정 열'].mean() df['특정 열'].median()groupby()를 애용하자-
df.groupby('집계 기준 열 이름', as_index)['집계 대상 변수'].집계메소드(): 이건 원형을 보기보단 예제를 보자
편의점 매출에서 성별에 대한 평균 지불 금액을 알고싶다고 가정하자df.groupby(['성별'], as_index = False)['지불 금액'].mean() # as_index는 성별을 index로 사용을 bool로 결정 (디폴트는 True) """실제 데이터가 아닌 예시입니다. 성별 지불금액 0 남자 10000 1 여자 8000 """마찬가지로 여러 열에 대해 값을 구할수도 있고 집계 낼 수도 있다.
df.groupby(['성별', '나이대'], as_index = False)['지불 금액', '물품 갯수'].mean() """ 계산을 거치지 않은 예시입니다... 성별 나이대 지불금액 물품갯수 0 남자 미성년자 3000 2 1 남자 성인 12000 5 2 여자 미성년자 4000 3 3 여자 성인 9000 4 """무엇이 보이는가 ? 특정 열은 범주형을 위주로 사용한다. (가끔 수치형 쓸 때도 있음)
-
여기서 끝이 아니다~
~~밤대추풋고추생강계피당귀향로타임로즈마리백미흑미오곡잡곡설탕구운소금히말라야소금말돈소금후추대파쪽파양파실파잣은행초콜릿된장콩장쌈장두반장애호박늙은호박단호박딸기양배추파파야두리안등의열대과일등을몽땅찜기에때려놓고50시간푹끓인후여기서끝이아니다돼지고기소고기말고기양고기닭고기꿩고기쥐고기하마고기악어고기코끼리고기개고기물고기불고기바람고기환단고기참치꽁치넙치뭉치면살고흝어지면참다랑어를갈아넣고여기서끝이아니다비린내를제거하기위해월계수청주잭다니엘피노누아와인머루주매화수막걸리커피콩을넣고여기서끝이아니다잡내제거를위해랍스타곰발바닥제비집베니스상인의겨드랑이살한근토끼발닭모이주머니최고급와규스테이크마이아르겉껍질테운부분으로잡내를제거하고여기서끝이아니다에비양삼다수아이시스아리수보리수빼어날수라싸수아름다울미백미현미흑미별미를넣고여기서끝이아니다~~집계 함수들을 더 여러개로 사용할 수도 있다. 그건 바로,,,
-
agg([집계 함수 이름 리스트]): 평균만이 아닌 최대 최소값도 같이 구하고 싶을 수도 있다.df.groupby(['성별', '나이대'], as_index = False)['지불 금액', '물품 갯수']\ .agg(['mean', 'max' 'min']) # 메소드 체이닝으로 코드가 길어졌다. 끊긴 부분에 '\'를 사용하면 긴 코드를 줄바꿈하여 사용 할 수 있다. """ 지불금액 물품갯수 mean min max mean min max 성별 나이대 0 남자 미성년자 3000 2000 4000 2 1 4 1 남자 성인 12000 10000 14000 5 3 7 2 여자 미성년자 4000 3000 5000 3 1 5 3 여자 성인 9000 6000 12000 4 2 6 """ #타이핑 힘들다,,,열 이름들의 행을 또 묶는 열이 등장했다.
보아하니 모든 부분에 대해 집계 값이 나오는데… 집계 대상 행마다 집계 함수를 지정할 순 없나?
→ 라고 생각한 순간 dictionary를 agg의 매개변수로 사용해서 출력 할 수 있다.
df.groupby(['성별', '나이대'], as_index = False)['지불 금액', '물품 갯수']\ .agg({'지불 금액' : 'mean', '물품 갯수' : 'max'}) """ 성별 나이대 지불금액 물품갯수 0 남자 미성년자 3000 4 1 남자 성인 12000 7 2 여자 미성년자 4000 5 3 여자 성인 9000 6 """자 웬만한 기초 numpy, pandas의 기초는 여기서 끝났다. 고생하셨습니다…
-
마무리
좀 늦게 올린 감이 있는데, 이전에 노션에서 쓰고 정리해서 다시 올린다...
12일차까지 빠르게 올려보겠습니다 흑흑
