
서론
이번엔 여러 자료 구조를 배웠으니 다루는 방법에 대해 배운다.
흐름을 보았을 때, AI 모델을 학습 시키기 위해서 데이터를 전처리하는 작업을 배우는 느낌이다! 학부 때 해봐서 어느정도 익숙하다... 그래도 할 건 해야지
시작
데이터를 전처리하는 단계는 두개가 있는데,
하나는 수집한 데이터를 df나 array로 만드는 데이터 구조 만들기
또 하나는 모델링을 위해 데이터를 전처리를 해 줍니당
컴퓨터는 계산만 할 줄 아는 기계기 떄문에 숫자로 바꾸어줘야겠지요? 그게 바로 두번째로 언급한 단계중 하나입니다
근데 이번 강의에선 첫번째 단계를 배울거고 목표를 봅시다!
- 분석을 위해 데이터 구조를 이해하고 생성하기.
- 데이터 분석 절차를 이해하고, 분석 도구를 사용하기.
Chapter 1. 데이터프레임 변경
- 데이터프레임 열 이름 변경
외부에서 데이터를 불러 왔을 때, df 열 이름이 마음에 안들수도 있다.
가독성을 해치거나... 의미없는 문자로 되어있을 때라던지... 두가지 방법이 있다 !- 일부 열만 바꾸기
딕셔너리로 매핑해줘야 한다.
inplace 파라미터는 없이 하면 df에 실제로 반영이 안된다. True를 해야 df 원본도 같이 바뀐다.df.rename(columns = {'col1' : '이걸로', 'col5' : '바꿀래요'}, inplace = True) - 전체 다 바꾸기
변경이 필요 없는 열은 고대로 하면 유지가 되겠지요?df.columns = ['col1', 'col2', '이걸로 바꿀래요', ...]
- 일부 열만 바꾸기
- 데이터프레임 열 추가
df의 데이터를 가공해서 새로운 열을 추가하는 경우도 있다.
합계 열을 평균열로 새로 만든다거나... 마찬가지로 2가지 방법이 있다.- 맨 뒤에 추가하기
존재하지 않는 열 이름으로 데이터를 넣으면 추가가 된다.# mean이란 열이 없다는 가정 df['mean'] = df['total'] / len(df) - 지정한 위치에 추가하기
매개변수는 차례대로 인덱스 위치(0부터 시작), 추가할 컬럼 이름, 데이터df.insert(1, 'new_column', data)
- 맨 뒤에 추가하기
- 데이터 프레임 열 삭제
데이터를 삭제하기전에 신중하게 복제본으로 하길 권장한다...- 데이터 프레임 복제
df = data.copy()
- 삭제하기 (여러개도 가능 : list)
axis는 행과 열을 의미한다. 디폴트는 0이고 행이다!
inplace는 위에서 나왔던 것처럼 원본에 반영할지 여부df.drop(['삭제할 열1, 삭제할 열2], axis = 1, inplace = True)
- 데이터 프레임 복제
- 데이터 프레임 데이터 변경
방법이 여러개있다-
열 전체 값 변경하기
df['수정할 열'] = 0 # 전체 데이터가 0으로 바뀜
-
조건으로 값 변경하기
df.loc[df['수정할 열'] < 1000, '수정할 열'] = 0 # 1000미만 데이터면 0으로 바뀜
-
np.where으로 변경하기df['수정할 열'] = np.where(df['수정할 열'] > 40, 1, 0) # 40 미만이면 0, 아니면 1
-
map()으로 변경하기 : 딕셔너리로 매핑df['gender'] = df['gender'].map({'Male' : 1, 'Female' : 0)}
-
cut()메소드로 연속형 → 범주형으로 변경하기
예를들면 나이 → 연령대, 고객별 구매 금액 → 고객 등급...
값의 범위를 균등하게 분할할뿐이지 갯수를 균등하게 해주진 않는다.df['Age'] = pd.cut(df['Age'], 3, labels = ['미성년', '청년', '노인']) # 바꿀 열, 등분할 수, 각각 범주 명 (등분할 수는 구간을 정할수 있다.) df['Age'] = pd.cut(df['Age], bins = [0, 19, 50], labels = ['미성년', '청년', '노인']) # 미성년 <= 19, 20 < 청년 <= 50, 50 < 노인
-
Chapter 2. 데이터프레임 결합

두 데이터 프레임을 결합하는 경우는 허다하다. 3가지를 보자
-
pd.concat()결합
매핑 기준 : 인덱스(행) 0 , 컬럼 명(열) 1df = pd.concat(df1, df2], axis = 1, join = 'inner')그림을 참고해서 join을 넣어보자
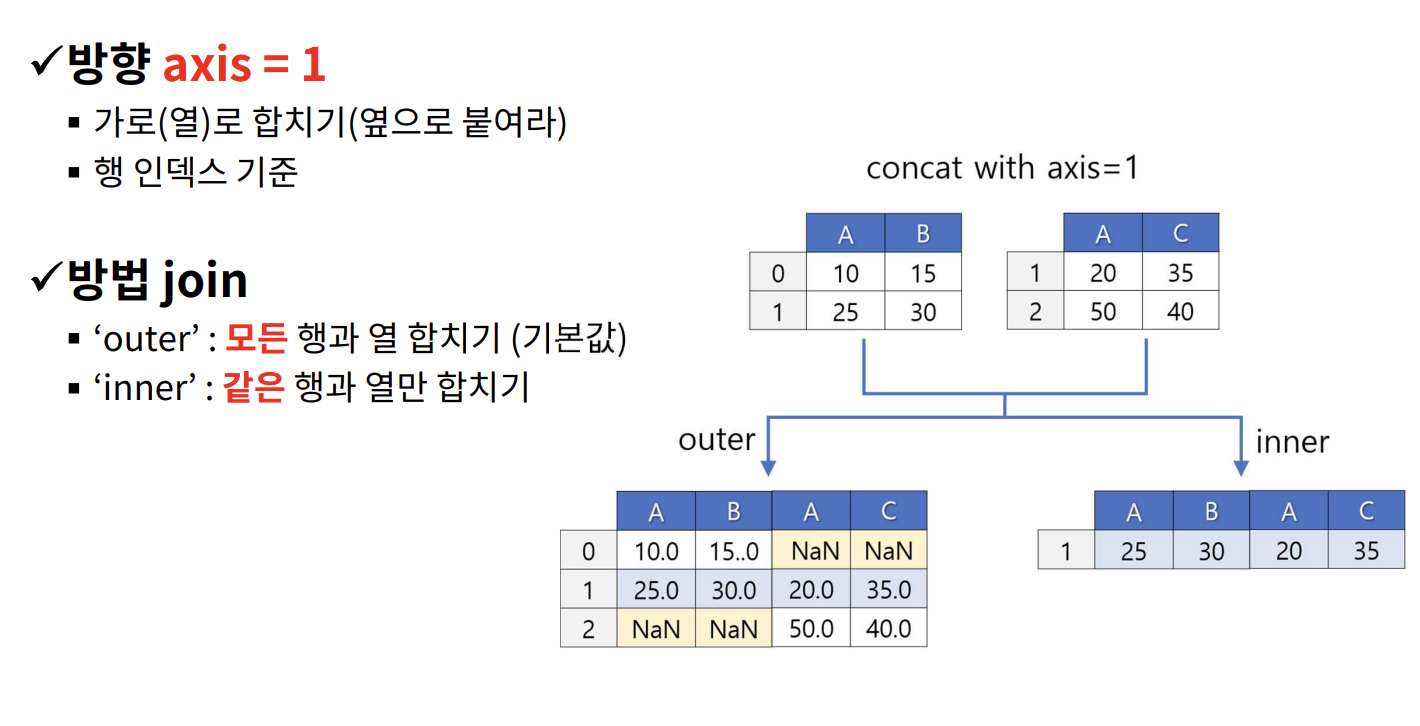
-
pd.merge()결합
옆으로만 병합한다 (aixs = 1)
어떤 컬럼을 기준으로 삼는지 ? (on = '컬럼')
방법 집합으로 보면 됨 (how = 'inner', 'outer', 'left', 'right' 결합 방식에 따라 없는 데이터라면 NaN으로 데이터가 채워진다.df = pd.merge(df1, df2, how = 'inner', on = 'col1' # col1을 기준으로 inner join (교집합(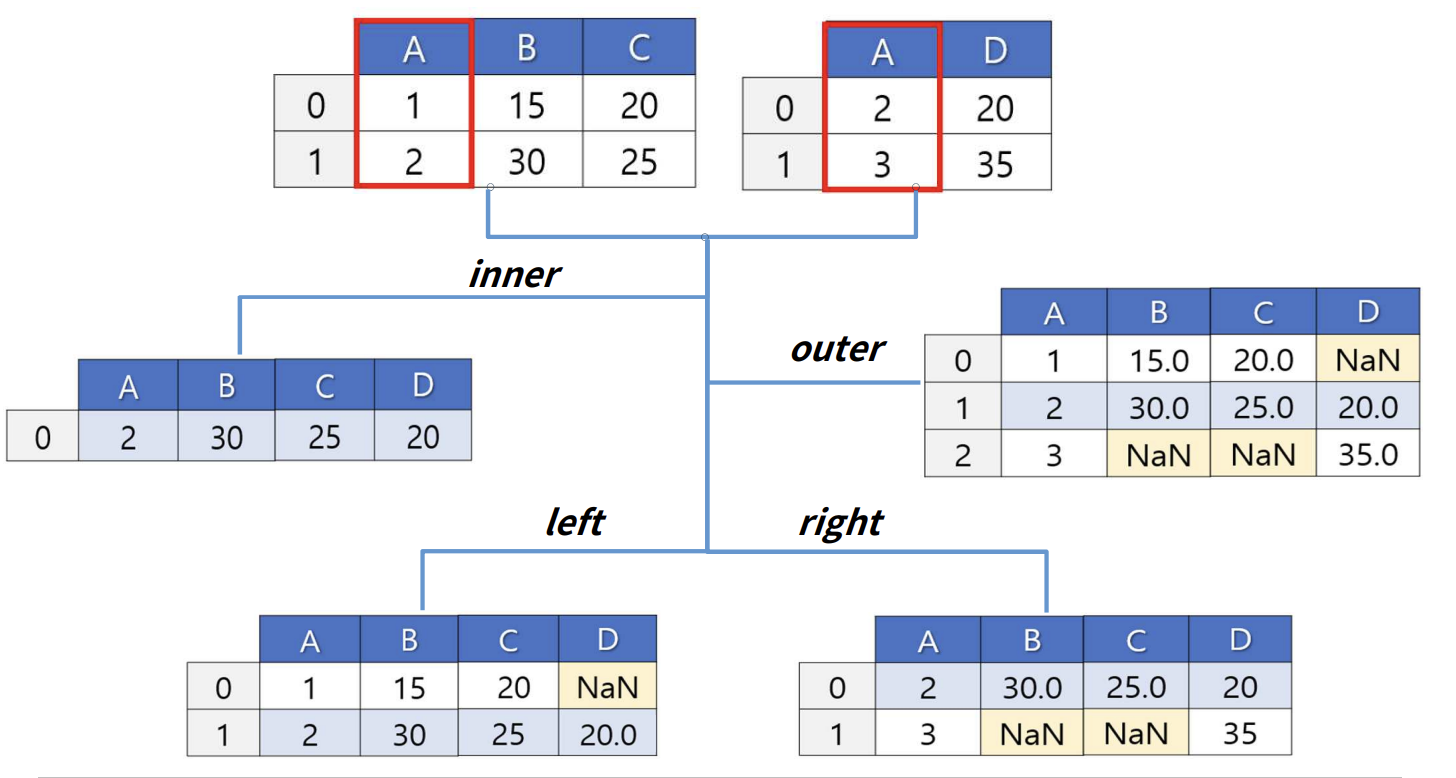
-
pd.pivot()
엥? merge 아니지 않아요? 라고 생각할 수 있겠지만, 구조를 변형해 조회하니 비슷한 결이라고 생각하자...-
groupby()vspivot()
이전에 배운 그룹바이랑 비슷하긴하다# 매장의 일별 카테고리별 판매량을 집계 temp = pd.merge(sales1, product) temp2 = temp.groupby(['Date', 'Categort'], as_index = False)['Qty'].sum() """ Date Category Qty 0 2013-01-01 Drink 0.000 1 2013-01-01 Food 0.000 2 2013-01-01 Grocery 0.000 3 2013-01-01 Household Goods 0.000 4 2013-01-02 Drink 1158.000 ... ... ... ... 119 2013-01-30 Household Goods 932.000 120 2013-01-31 Drink 971.000 121 2013-01-31 Food 751.766 122 2013-01-31 Grocery 1907.797 123 2013-01-31 Household Goods 711.000 """ # pivot temp3 = temp2.pivot('Category', 'Date', 'Qty') """ Date 2013-01-01 2013-01-02 2013-01-03 2013-01-04 2013-01-05 2013-01-06 2013-01-07 2013-01-08 2013-01-09 2013-01-10 ... 2013-01-22 2013-01-23 2013-01-24 2013-01-25 2013-01-26 2013-01-27 2013-01-28 2013-01-29 2013-01-30 2013-01-31 Category Drink 0.0 1158.000 985.000000 1055.000000 1319.000 407.000 1267.000 1115.000 1290.00000 914.000 ... 1114.000 1152.000 924.000 1213.000 1132.000 417.000 830.000 999.000 1140.000 971.000 Food 0.0 1227.652 913.699000 790.366000 901.057 416.912 852.676 829.851 967.58200 775.515 ... 780.201 1025.047 791.388 836.856 880.019 416.783 821.064 668.154 900.092 751.766 Grocery 0.0 3305.130 2613.685001 2711.079001 2746.782 926.282 2689.720 2356.277 3023.57298 1933.235 ... 2242.216 2824.296 2221.805 2393.208 2257.907 1162.207 2208.364 2001.047 2662.485 1907.797 Household Goods 0.0 1070.000 836.000000 834.000000 821.000 257.000 830.000 830.000 917.00000 687.000 ... 786.000 769.000 622.000 701.000 551.000 247.000 625.000 617.000 932.000 711.000 """참고 (시각화)
sns.heatmap(df)
-
시계열 데이터 ?
시계열 데이터는 행과 행에 시간의 순서이며, 시간 간격이 동일한 데이터를 일컫음.
Time Series Data ⊂ Sequential Data
pd.to_datetime(날짜 데이터, format=)날짜 타입으로 변환할 수 있음 (object → dateTime)
format 참고
- 날짜 요소 추출
df['date'].dt.날짜 요소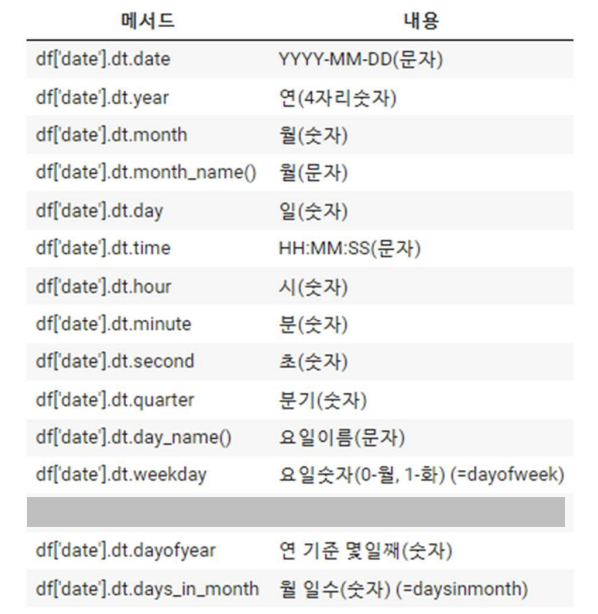
df[’date’].shift(index)시간에 따른 흐름 전후로 데이터를 이동시킬수 있음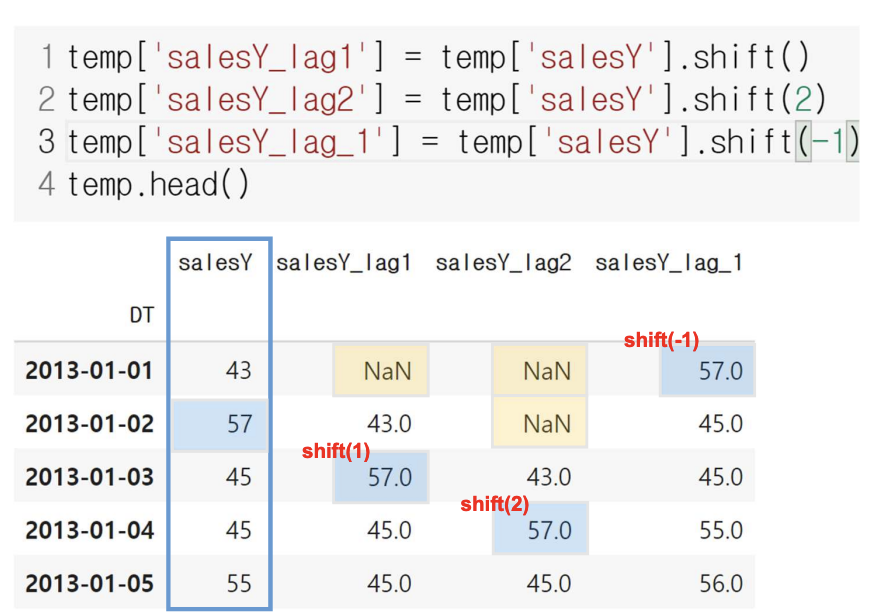
df[’date’].rolling().집계함수()시간에 흐름에 따라 일정 기간의 집계를 이동하며 계산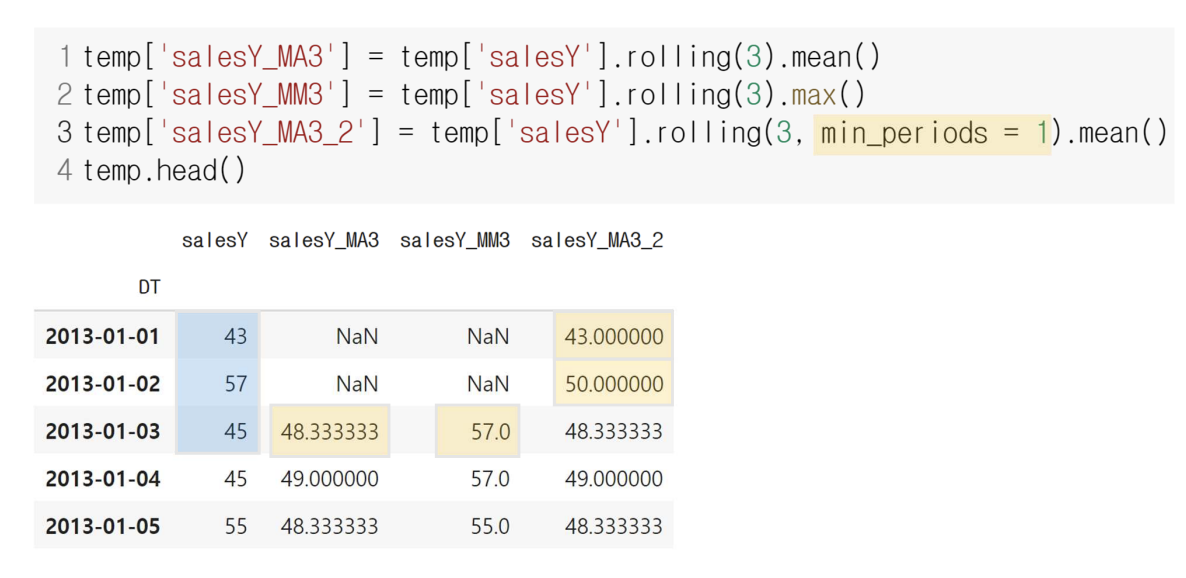
df[’date’].diff(index)특정 시점 데이터, 이전 시점 데이터와 시간 차 구하기 (인덱스를 -로 함)
Chapter 4. 데이터분석 방법론
CRISP-DM
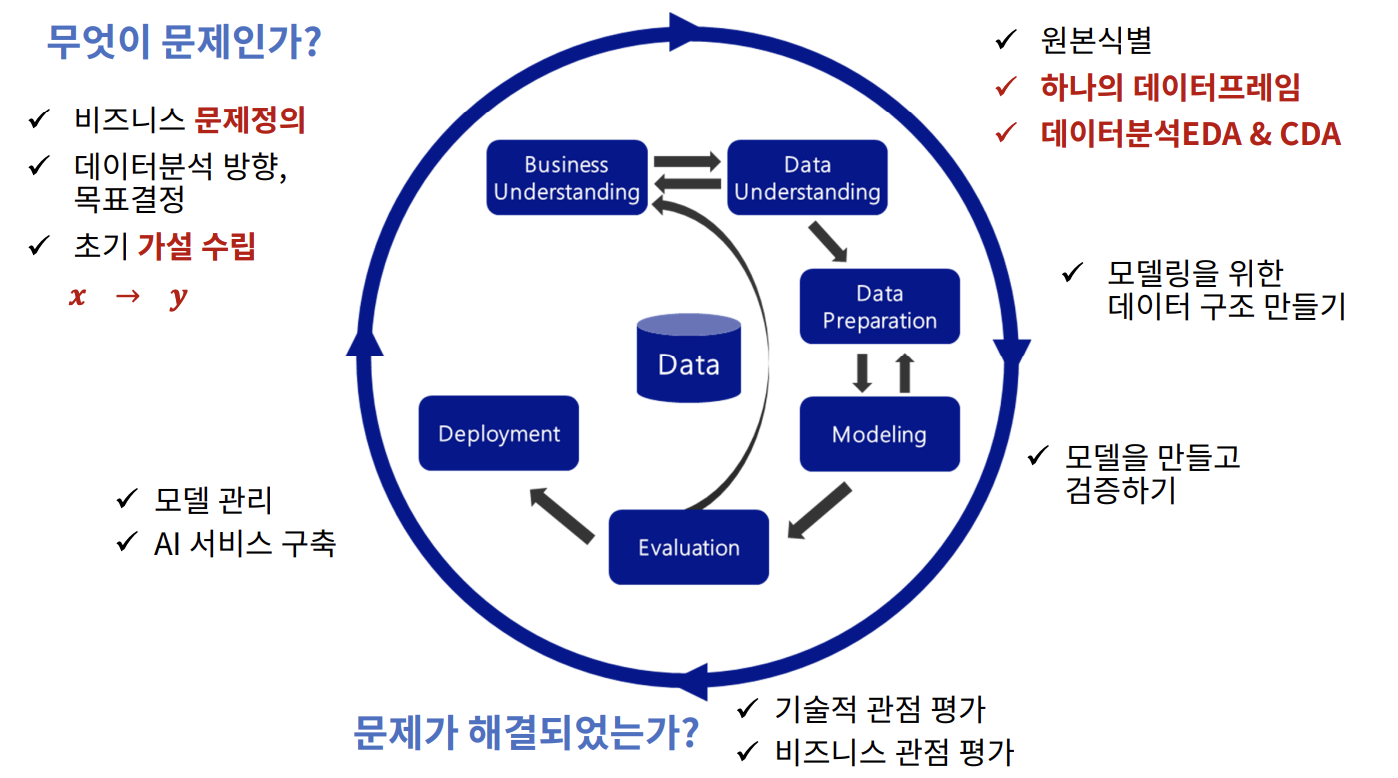
-
Business Understanding - 가설 수립
문제를 정의하고, 요인을 파악하기 위해 가설 수립
- 과학 연구
- 기존 연구 결과로 이어져 내려오는 정설 - 귀무가설
- 기존 입장을 넘기 위한 새로운 연구 가설 - 대립가설
- 여기서 우리가 수립하는 가설을 대립가설이라고도 함
- 가설 수립 절차
- 해결 해야 할 문제가 무엇인가? (목표, 관심사, y)
- Y를 설명하기 위한 요인을 찾기 (x)
- 가설의 구조를 정의하기 (x→y)
- 과학 연구
-
Data Understanding
데이터 원본 식별 및 취득 (초기)가설에서 도출된 데이터의 원본을 확인한다.
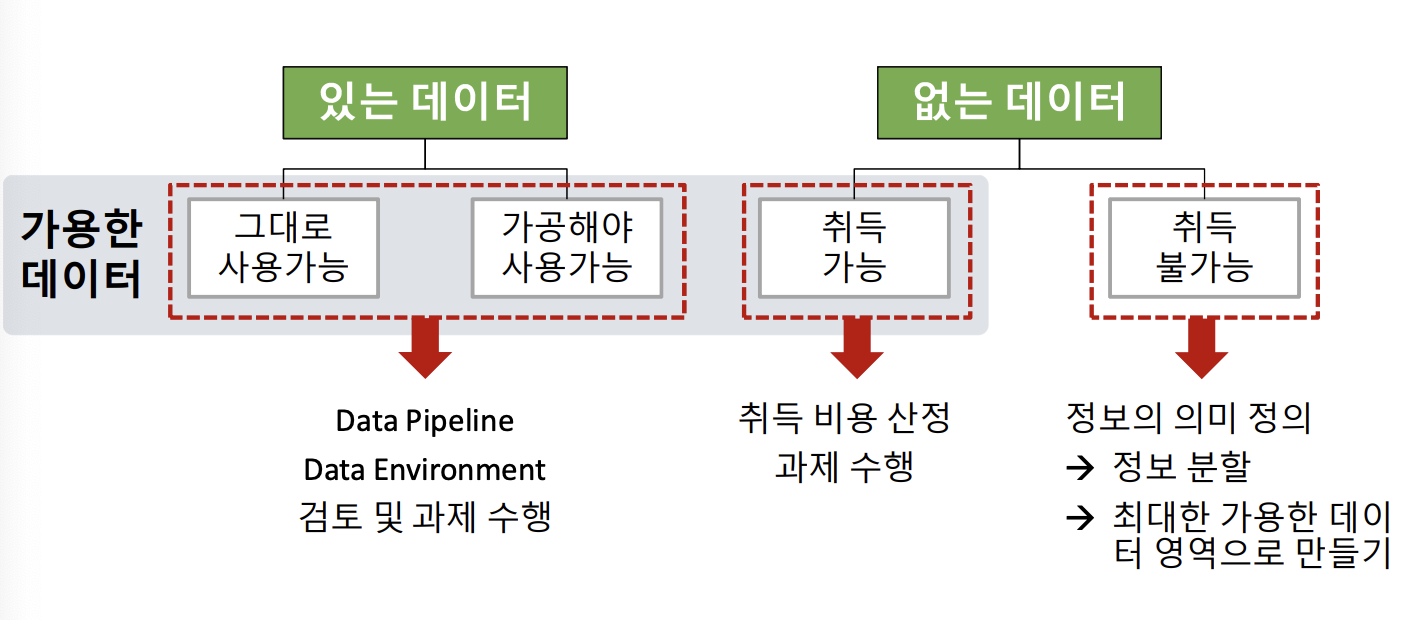
- 데이터 탐색
- EDA (Exploratory Data Analysis) 탐색적 데이터 분석
- 개별 데이터의 분포, 가설이 맞는지 파악
- 결측치, 이상치 파악
- CDA (Confirmatory Data Analysis) 확증적 데이터 분석
- 탐색으로 파악하기 애매한 정보는 통계적 분석 도구(가설 검정) 사용
- EDA (Exploratory Data Analysis) 탐색적 데이터 분석
- 정리된 2차원 구조의 데이터셋을 분석하는 방법 이전에 본 EDA, CDA
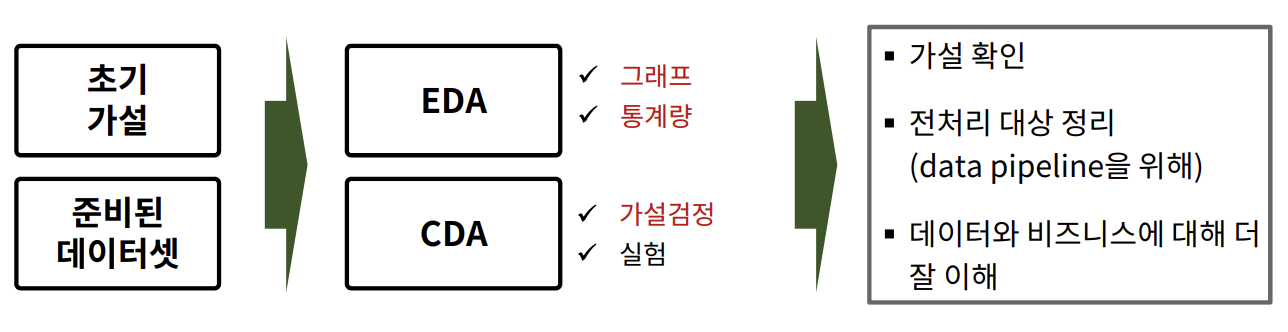
- 언제 어떤 그래프를 그리고 어떻게 해석해야되는지?
- 언제 어떤 통계량을 구하고 어떻게 해석해야 되는지?
- 언제 어떤 가설 검정 방법을 사용하고 어떻게 해석해야 되는지?
EDA & CDA 진행 순서
- 단변량 분석 : 개별 변수의 분포
- 이변량 분석1 : feature(x)와 target(y) 간의 관계 (가설 확인 단계)
- 이변량 분석2 : feature들 간의 관계
- 데이터 탐색
-
Data Preparation
- 개요 모든 셀에 값이 있어야 한다. 모든 값은 숫자이어야 한다. 값의 범위를 일치 시켜야한다(정규화)
- 수행되는 내용
→ 결측치 조치, 가변수화, 스케일링, 데이터 분할
- 개요 모든 셀에 값이 있어야 한다. 모든 값은 숫자이어야 한다. 값의 범위를 일치 시켜야한다(정규화)
-
Modeling
- 모델링 (학습, Learning, Training) 데이터로부터 패턴을 찾는 과정 오차를 최소화 하는 패턴 결과물 : 모델 (모델은 수학식으로 표현)
- 모델링을 위한 재료 학습 데이터 알고리즘
- 모델링 (학습, Learning, Training) 데이터로부터 패턴을 찾는 과정 오차를 최소화 하는 패턴 결과물 : 모델 (모델은 수학식으로 표현)
