지난 시리즈
지난 번에는 가상스레드에서 Netty 네트워크 라이브러리를 사용하는 문제 때문에 메모리 급증 현상이 발생했다는 것에 집중했다.이번에는 동일한 아키텍쳐 위에 Log 및 Metric 수집을 위한 Opentelemetry 라이브러리를 적용한 후에 발생한 또다른 메모리 증폭 현상에 대해 집중하려고 한다. 이 현상은 트래픽이 적어 메모리 급증 현상이 없었던 서비스 또한 해당 현상이 재현되었다... 아키텍쳐는 지난 포스팅을 참고하자.
문제 포착 및 가설
Opentelemetry 라이브러리를 추가하여, Metric/Log 수집부에 gRPC/Http로 전송하게 하였더니, 가상스레드 내부에서 Redis 조회하는 메서드와 MQTT로 Pub하는 메서드의 Duration Time이 또 다시 증가하였다. 그 결과 때문인지, 이전과 동일하게 메모리가 폭증하는 현상이 일어났다. 오히려 이전과 동일한 메모리 자원을 사용했다면 OOM이 발생했을만큼 '더' 늘어났다.
이전 포스팅을 보면 알 수 있겠지만, 이 현상이 가상스레드의 OverHead라고 생각했다. 그렇다면 왜 Opentelemetry 로그 전송을 추가했을 뿐인데 이전과 동일한 현상이 발생했을까? 그 원인에 대해 분석한 내용에 대해 정리하려고 한다.
로그 수집 Flow
Metric과 Log 수집 관련된 Flow는 잘 알지 못해, 관련 부서에 문의를 드렸다.
문의 드렸던 내용과 결과는 다음과 같다.
- Log Event가 발생할때마다 수집부로 I/O가 발생하는지?
→ I/O Flush는 N초 주기로 일어나거나 Log Queue Size가 가득 찼을때 발생 - I/O 구현체가 무엇인가? Netty를 사용하는가?
→ 정확히는 알 수 없지만, Opentelemetry에서 사용하는 네트워크 구현체를 따라간다.
Deep Dive
일단 서비스로 인입되는 QPS와 이에 따른 로그 사이즈로는 절대 Flush가 N초 주기로 일어날 리가 없다. 굉장히 짧은 시간안에 Log Queue Size가 가득 찼을 것이고, 이로 인해 수많은 I/O가 발생했을 것이라고 확신했다.
gradle dependencies로 라이브러리 의존성을 확인해보니 OkHttp가 추가되어있었다. 네트워크 I/O를 보낼때 OkHttp를 사용하나보다.
 그러면 OkHTTP가 어떤 방식으로 I/O를 처리하는지 알아볼 필요가 있다. (근데 코틀린으로 되어있더라. 신기했다!)
그러면 OkHTTP가 어떤 방식으로 I/O를 처리하는지 알아볼 필요가 있다. (근데 코틀린으로 되어있더라. 신기했다!)
내부 구조를 살펴보니 OkHttpGrpcSender 클래스에서 로그를 send하는 메서드를 호출할 때, OkHttpClient 클래스에서 이를 호출하고 있다. 정확히는 OkHttpClient 내부의 Dispatcher를 호출한다.
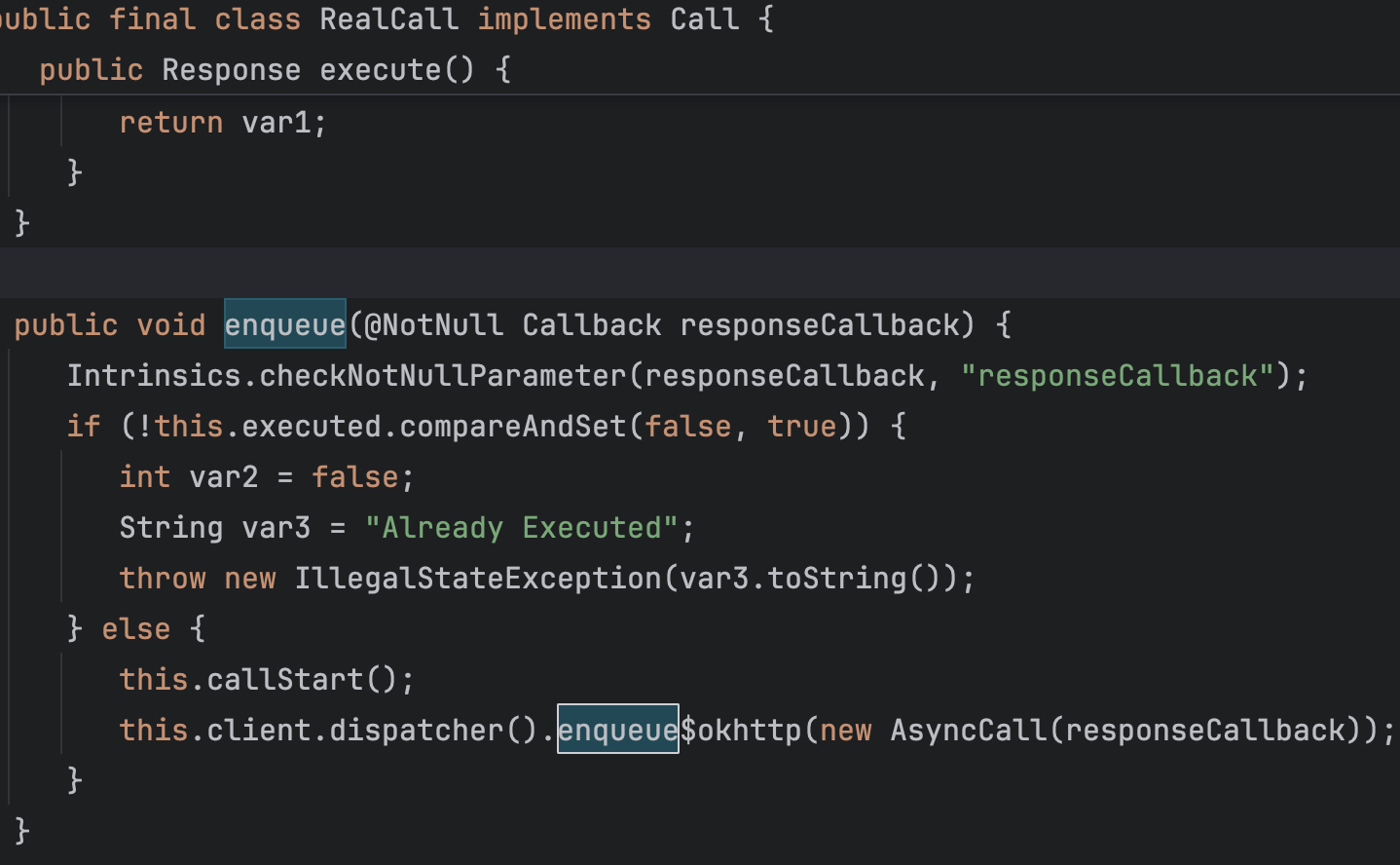 Dispatcher 내부에는
Dispatcher 내부에는 ExecutorService 를 직접 생성해서 비동기 I/O 작업을 함을 알게 되었다.
그런데 이상한부분은, 스레드풀의 스레드 개수가 사실상 무한대였다.. 아래를 보면 믿게 될 것이다.
실제 enqueue 하는 구현부를 사진으로 보자면
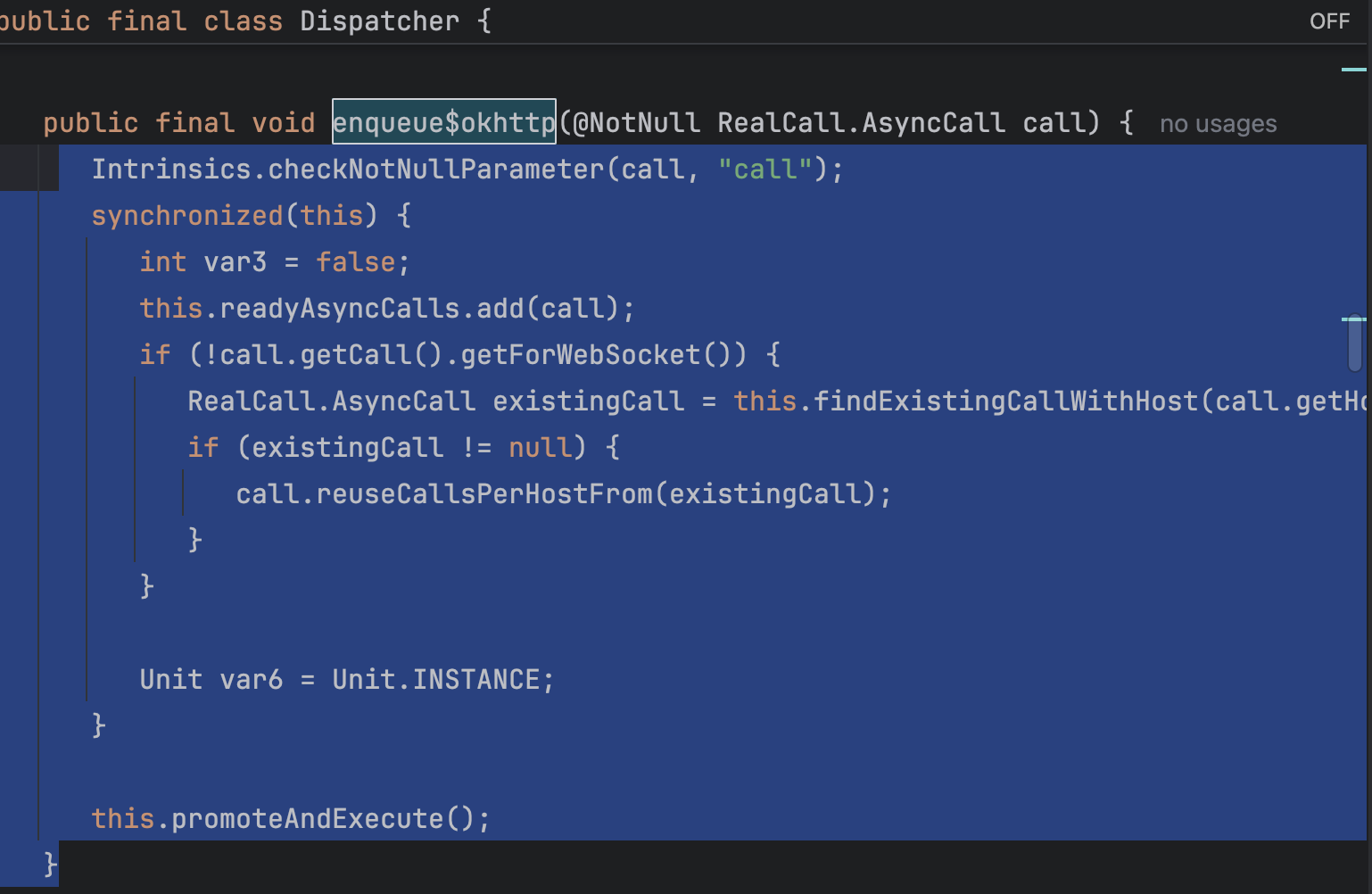
해당 메서드에서 마지막에 promoteAndExecute()를 호출하는데, 요 메서드 마지막부분에 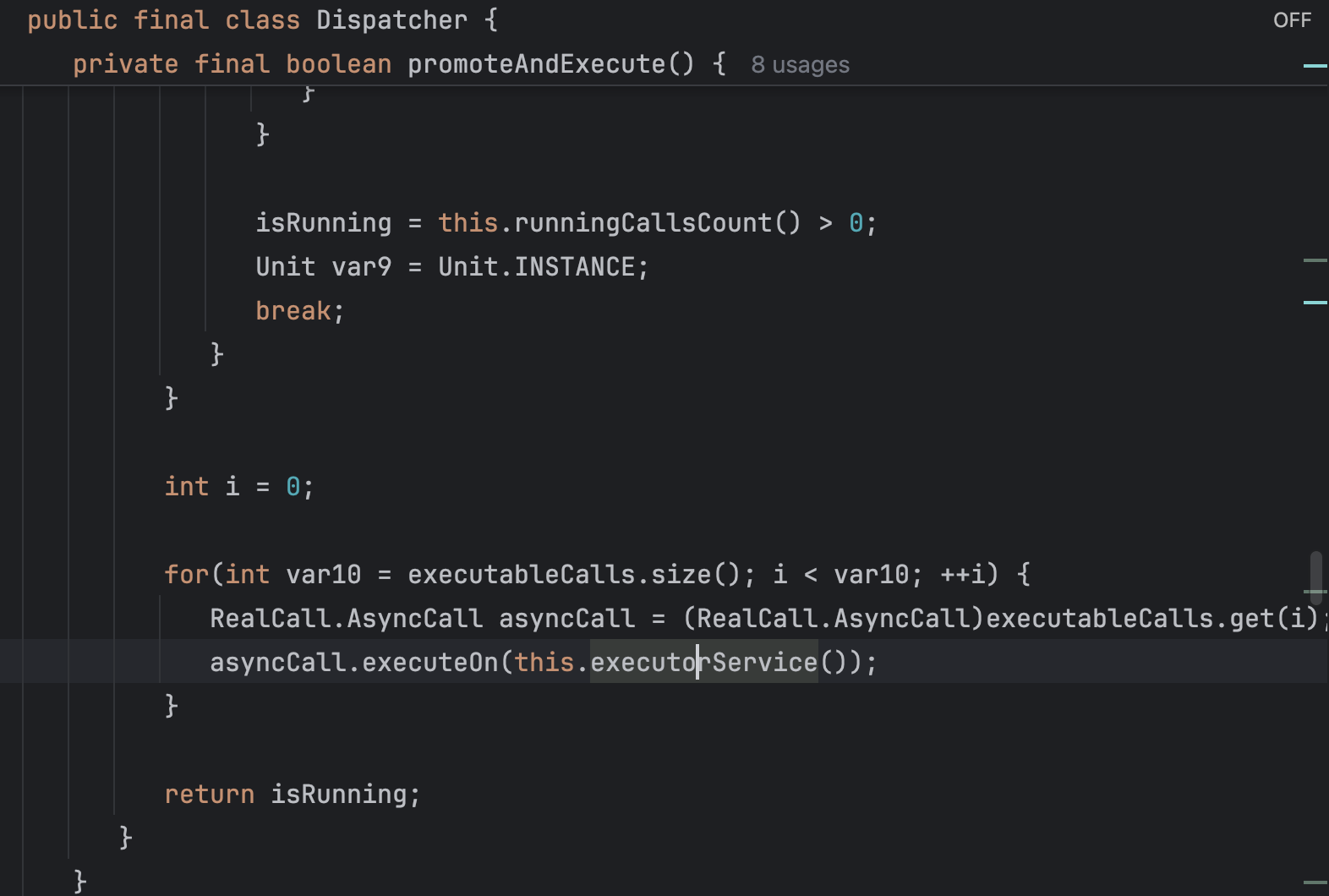
executorService() 메서드를 통해 싱글톤 스레드 풀을 사용하고 있었다. 만일, 싱글톤객체로 JVM에 올라와 있지 않으면 스레드의 개수가 무한대까지 생성 가능한 스레드풀을 생성한다..
OkHttpClient I/O 스레드 풀 전략.. 메모리 폭탄의 범인인가?
this.executorServiceOrNull = (ExecutorService)(new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, (BlockingQueue)(new SynchronousQueue()), Util.threadFactory(Util.okHttpName + " Dispatcher", false)));커스텀 스레드풀을 사용하고 있다. SynchronousQueue 와 함께 무한대까지 스레드를 생성할 수 있다. 이 Queue 전략은 스레드 풀 내에 유휴스레드가 없으면 '무조건' 스레드를 생성하는 방법이다. 그래서 조심히 사용해야하는 Queue이다. 나는 이 전략에서 문제가 있어서 스레드를 계속해서 생성하지 않았을까 추측했다.
하지만 유명한 오픈소스는 이러한 부분이 역시 고려가 되어있었다. 바로 아래 부분이다.
private final boolean promoteAndExecute() {
Object $this$assertThreadDoesntHoldLock$iv = this;
int isRunning = false;
if (Util.assertionsEnabled && Thread.holdsLock($this$assertThreadDoesntHoldLock$iv)) {
throw new AssertionError("Thread " + Thread.currentThread().getName() + " MUST NOT hold lock on " + $this$assertThreadDoesntHoldLock$iv);
} else {
List executableCalls = (List)(new ArrayList());
isRunning = false;
synchronized(this) {
int var4 = false;
Iterator var10000 = this.readyAsyncCalls.iterator();
Intrinsics.checkNotNullExpressionValue(var10000, "readyAsyncCalls.iterator()");
Iterator i = var10000;
while(true) {
if (i.hasNext()) {
RealCall.AsyncCall asyncCall = (RealCall.AsyncCall)i.next();
if (this.runningAsyncCalls.size() < this.maxRequests) {
if (asyncCall.getCallsPerHost().get() < this.maxRequestsPerHost) {
i.remove();
asyncCall.getCallsPerHost().incrementAndGet();
Intrinsics.checkNotNullExpressionValue(asyncCall, "asyncCall");
executableCalls.add(asyncCall);
this.runningAsyncCalls.add(asyncCall);
}
continue;
}
}
isRunning = this.runningCallsCount() > 0;
Unit var9 = Unit.INSTANCE;
break;
}
}
int i = 0;
for(int var10 = executableCalls.size(); i < var10; ++i) {
RealCall.AsyncCall asyncCall = (RealCall.AsyncCall)executableCalls.get(i);
asyncCall.executeOn(this.executorService());
}
return isRunning;
}
}
먼저 I/O 작업을 해야할 작업리스트 executableCalls 를 생성하고,
while 반복문 안에서 현재 등록된 비동기 작업들인 readyAsyncCalls에서 하나씩 순회하며
runningAsyncCalls.size() < maxRequests 인 동안, 즉 실행하고 있는 작업들의 크기가 최대 수행 작업의 크기보다 작을 경우에만 실행 대상 후보에 포함하고,
callsPerHost < maxRequestsPerHost 인 것만 실행대상에 추가한다.
마지막에 실제로 스레드 풀에 넘기는 건 실행대상에 추가된 작업들만 진행한다.
따라서 Dispatcher가 maxRequests, maxRequestsPerHost로 동시 실행 가능한 I/O 스레드 개수를 제한하고 있기 때문에,
단일 Dispatcher 기준으로는 스레드가 무한히 증가하는 상황은 거의 발생하지 않는다.
Back to Problem
너무 메모리로만 치우쳐져서 생각하고 있는 것 같다.
다시 돌아와서, 내가 분석해야할 가설은 'Duration 증가'로 인한 'Memory 증가'현상이다.
'Duration 증가?'
분석 결과 : Duration증가???
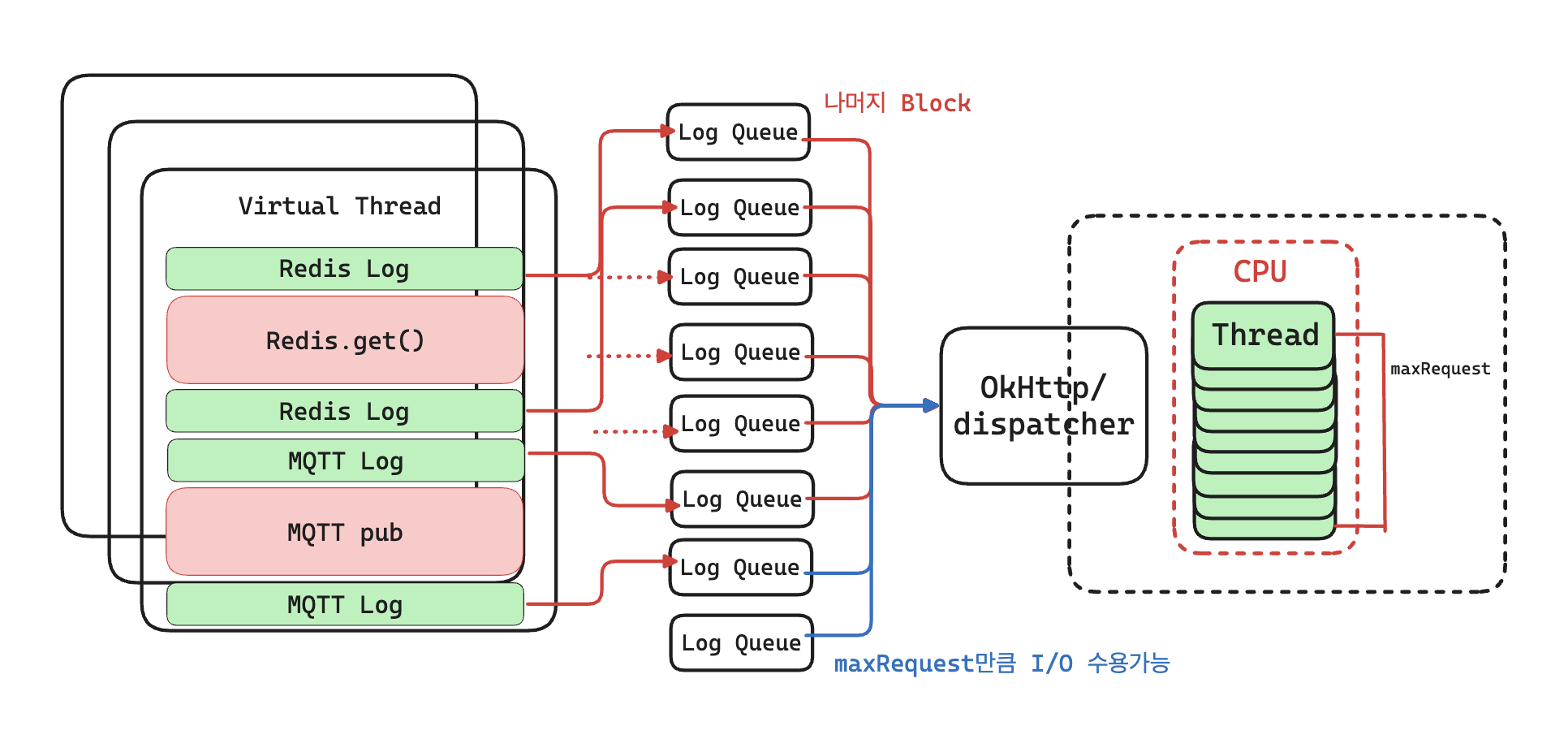
'지연'에 초점을 맞춰 보면, 현재 발생한 문제는
로그가 쌓이는 속도 > 전송/처리 속도 때문인 것으로 보인다.
처음에는 OpentelemetryAppender 내부에 BlockingQueue가 존재하고, 로그를 한 번에 모아 보내는 방식이라고 추정해 BatchLogRecordProcessor를 사용하고 있을 것이라 생각했다.
그러나 실제 호출 스택과 SDK 구현을 따라가보면, 배치 방식이 아닌SimpleLogRecordProcessor 를 사용하고 있는 것으로 보인다..
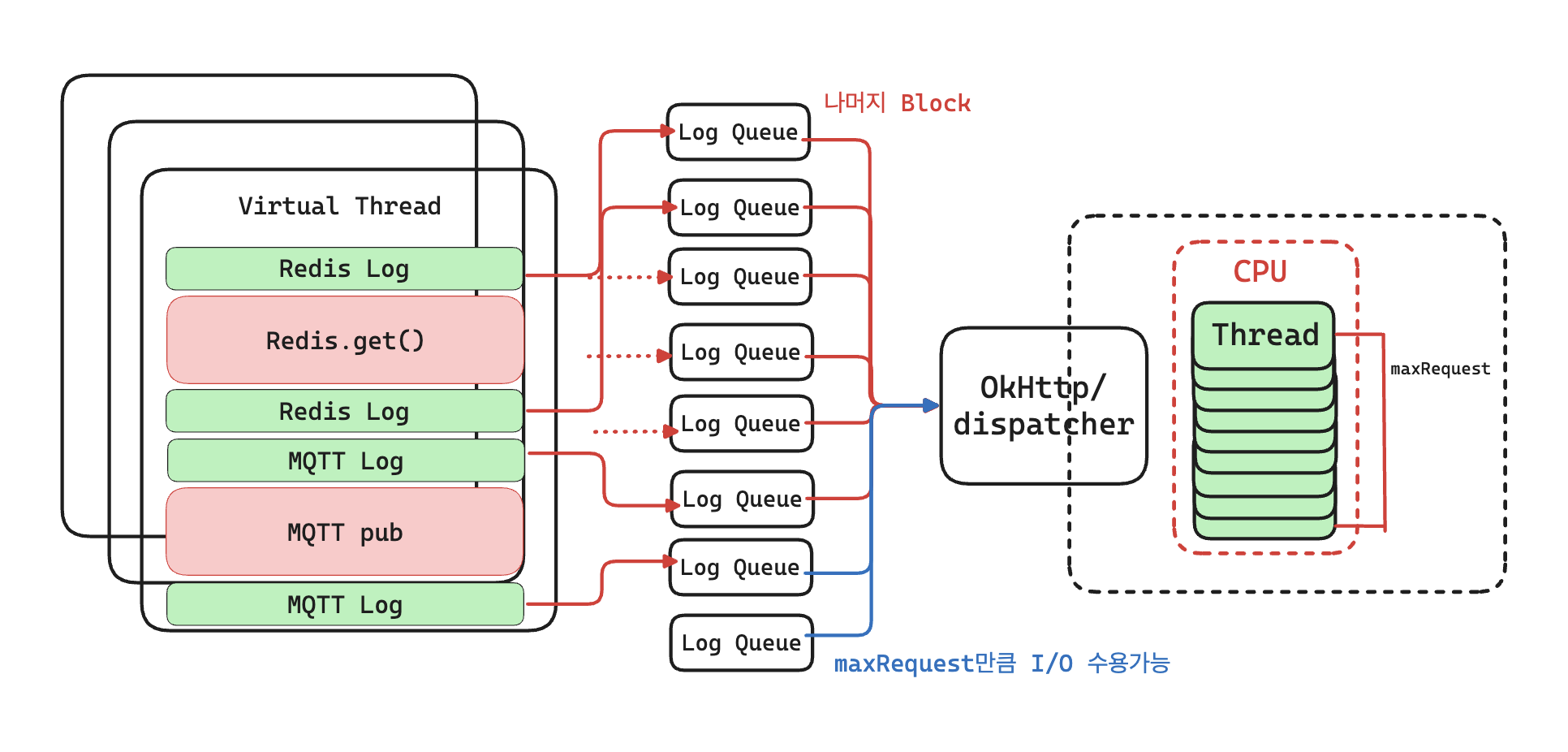
즉, 로그가 발생할 때마다 별도의 큐에 저장해 비동기적으로 모아 보내는 것이 아니라,
log.info()를 호출한 스레드가 즉시 Exporter까지 동기로 전송 요청을 건넨다.
이때 OkHttp Dispatcher 클래스에서 동시 요청 제한 갯수로 인해 병목이 생겨
추가 요청은 큐에 대기하거나 block 상태에 머무르게 되고,
그만큼 로그 이벤트가 발생한 가상 스레드가 직접적으로 지연의 영향을 받게 되는 것이다.
즉 아래와 같은 상황이다.
해결 방안
실제 로그 수집 방법, 혹은 설정 파라미터를 개선하거나, CPU성능을 더 좋게하는 방식으로 scale up 하는게 좋아보인다.
당장은 CPU의 성능을 높이는 것이 blocking 스레드의 병목을 줄일 수 있는 방법일 것이다.
근데 이거.. 디버깅포인트로 실제 어떤 stack trace로 함수호출이 이뤄지는지 구현해내는게 쉽지가 않다..허..
