평상시에는 메모리 사용량이 300MB 안쪽으로 사용했던 서비스가, 트래픽이 몰리는 피크시간 때마다 메모리사용량이 메모리 임계치만큼(6G) 치솟는 현상이 발생했다.
이후, 지속적인 GC로 6GB → 300MB → 6GB → 300MB 로 요동을 치다가 트래픽이 잠잠해지면 다시 300MB 안쪽으로 유지되었다.
또한, 트래픽이 2배정도 적은 곳에도 같은 서비스코드로 운영되고 있는데, 그 서비스는 트래픽이 많은 시간대에도 300MB안쪽으로 유지되고 있었다.즉, 특정 임계치 이상의 트래픽을 받으면 메모리 과점유 현상이 발생하고 있는 문제가 발생중이다.
이 현상을 한달 반째 틈날 때마다 분석중인데.. 아직 해결이 되지는 않았지만 나를 위해서라도 이를 정리해보려고 한다.
대략적인 아키텍처
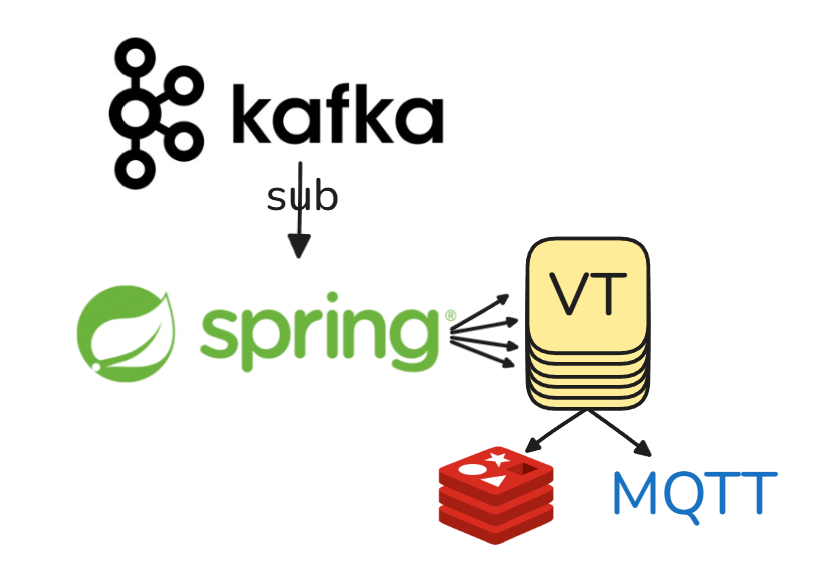
대강의 아키텍쳐는 다음과 같다.
(1) 초당 'N'k씩 들어오는 메세지를 구독하여
(2) 이를 Virtual Thread로 위임 하고, Virtual Thread에서
(3) redis 조회 후,
(4) MQTT로 PUB 한다.
이 때, Virtual Thread는 무한히 생성할 수 있으므로, 상한을 CPU개수에 비례하게 설정하였다.
가설 세우기
(1) 뻘짓한 가설 - Kafka 메시지 병목
서버가 처리할 수 있는 요청보다 더 많은 메세지를 받아서 서버 메모리에 부하를 일으켰다.
즉, Virtual Thread 개수가 병목이다.
로컬에서 실제 운영환경의 코드와 비슷하게 만들어놓고 부하테스트를 돌렸다. Virtual Thread의 개수를 1개만 두고, 메세지를 1000개, 2000개, 3000개를 발행해도 메모리는 동일했다.
도대체 왜지?
이는 Spring Kafka에서 메세지를 받았음을 전송하는 Ack가 별다른 설정이 없으면 @KafkaListener 어노테이션이 붙은 메서드가 완료될때, 비로소 Kafka에 ack를 보내기 때문이다.
지금의 상황은 Listener 어노테이션이 적용된 메서드가 동기방식이기 때문에, 실제 서버 내부 로직이 끝나기 전까지는 Ack를 보내지 않아 구독되는 메세지의 양은 일정할 수 밖에 없다.
그러니 메모리가 안튀지! 다소 바보같았던 가설이었다.
(2) 그럴듯한 가설 - CPU가 부족하다
CPU가 부족해서 메모리가 터졌다.
다소 어이없어보이지만 이 가설에는 타당한 근거가 있다.
지금부터 이 가설을 뒷받침하는 글을 쓰려고 한다.
근거 → Duration Time
Virtual Thread에서 I/O는 두 번 발생한다.
- Redis
- MQTT
이 때, 트래픽이 많아지는 시점에 해당 I/O들에서 지연시간이 크게 늘어남을 확인할 수 있었다.
CPU랑 연관지어 생각한다면, 지연시간이 크게 늘어났고, 그 지연시간만큼 수많은 가상스레드들이 JVM을 점유하고 있을 것이다. max duration time이 400ms였으니.. 하나의 메세지를 처리하기 위한 객체(가상스레드 포함)들이 동시간대에 무지막지하게 생성되었을 것이다.
그렇다면 왜 지연이 생겼을까?
할 수 있는한 모든 경우의 수를 열어놓고 딥다이브했다.
-
가상스레드에서 발생하는 Redis I/O가 Unmount되지 않고 Blocking이 되고있기 때문일까?
그 말은, Redis에 부하가 있다는 이야기인데, Redis 부하는 관측되지 않았다. -
Redis I/O가 Unmount되면서 다른 가상스레드가 Carrier Thread에 의해 점유되며 뒤쳐지기 때문일까?
Redis 클라이언트가 Lettuce이고, Lettuce가 Netty기반으로 동작해서... mount될 수도 있고 안될 수도있고...
2번까지 찾아보고 나니, Lettuce가 뭐고 Netty가 뭔지 궁금해졌다. (pinning은 없고, unmount가 되는 것같다. 이는 나중에 검증해봐야겠다)
Netty가 뭐에요?
spring boot에서 config로 직접 클라이언트 구현체를 지정하지 않는 이상, 기본으로 채택되는 redis client가 Lettuce이고 Lettuce는 netty기반으로 I/O가 동작한다.
Netty는 비동기/논블록킹 I/O란다.
여기서 중요한점은 Netty가 사용하는 비동기 스레드 풀의 개수는 실제 사용가능한 processor, 즉 CPU의 개수 라는 점이다.
공식문서 & 소스코드 참고
https://redis.github.io/lettuce/advanced-usage/#default-thread-pool-size실제 io.lettuce.core.cluster 하위에 있는
RedisClusterClient클래스는AbstractRedisClient를 상속받는데, 기본 생성자를 호출하면 하위 메서드를 호출하고DefaultClientResources.create()를 호출하게 된다.
처음으로
DefaultClientResources가 참조되는 순간 static block에서 ioThread의 초기화가 일어나는데이 개수가 실제 CPU의 개수와 같다.
현재 운영환경에서 Pod의 CPU는 1vCPU이지만, Node는 한 16쯤 되므로, 거의 16개의 이벤 io thread가 존재한다는 이야기이다.
확신
여기쯤에서 이런생각이 들었다.
(1) 트래픽이 몰려서 수많은 가상스레드들이 생성됨 →
(2) Redis와 비동기 스레드풀의 개수가 16개(노드 vCPU)로 제한됨 3개 (k8s CPU limit 1로 지정할 경우 pod vCPU로 제한됨. 하지만 netty 이벤트 루프 스레드 개수는 최소 3개로 지정됨 max(vCPU,3)) →
(3) 실제 pod가 사용가능한 CPU는 1vCPU인데, 3개의 비동기 스레드풀이 스케줄링 되다보니 처리지연이 생김
근데 더욱 확신을 가지게 된 부분이, MQTT 브로커 통신마저 Netty를 사용함을 알게되었다.
그러면 정말 pod의 vCPU가 낮아서가 문제가 아닐까?
💡 참고사항
실제로 Lettuce 구현체를 사용할때,
RedisTemplate.opsForValue().get()을 사용하게 되면 아래 메서드 로직을 탄다.
statusCommand 가 false이면 pipeline에서 future.get()으로 비동기 작업이 종료되기를 대기함을 알 수 있다. 이게 실제로 unmount되는 작업인지 아닌지는 나중에 알아보도록 하자.

