[논문리뷰] Orthogonal Subspace Decomposition for Generalizable AI-Generated Image Detection
1. Introduction
- 생성 이미지 탐색의 일반화
- 너무 이른 단계에서 loss fuction의 수렴이 이뤄지면 일반화 성능이 떨어진다
- 일반화 성능이 떨어지는 현상에 대한 PCA관점의 규명
- 이를 해결하는 새로운 모델의 도입
- real image → fake image 에서 파생되는 것임
- SVD로 두 개의 orthogonal space를 만들어서 한쪽은 기존 pattern, 다른 쪽은 새로운 pattern를 학습시킴
- 이때 model은 real image에서는 충분히 학습돼 있고, 이를 최대한으로 활용해 효율적으로 paramter를 사용
2. Method
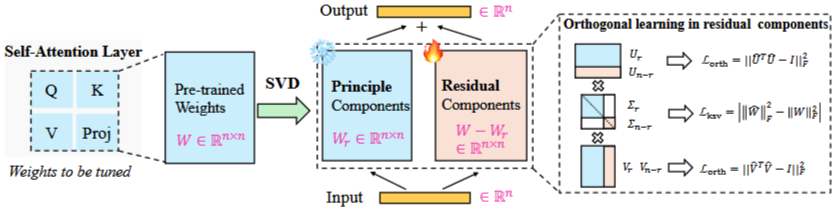
- 위의 SVD 수식을 이용함. 상위 r개의 rank만을 SVD에 이용.
- 은 training중에는 고정함
- 이거는 사전 학습된 모델이 가지고 있는 real에 대한 정보
- 그 다음 두 행렬간 잔차를 이용해 특정 deepfake 위조 방식의 패턴을 찾음
- 아래의 잔차를 계속 학습하여 최적화 함.
- 특정 fake 패턴에 익숙해 지는 방향으로 학습된다
- 여기서 잔차 이미지가 fake pattern을 학습하여 real과 fake를 잘 분리해 내도록 학습하려면 아래 두 가지의 제약 조건을 둔다.
- 이 학습한 방향을 망가트리지 않을 직교 공간에서의 움직임 → 직교성을 보존하는 방향으로 움직인다는 말
- 둘이 직교하면, 가 update 되어도 의 방향은 변하지 않음!
1. Orthognal Constraint
- 는 이다.
- 은 real을 학습하는 직교행렬
- 은 fake를 학습하는 직교행렬
- 과 은 서로 직교
- 또한 동일한 구성이다
2. Singular Value Constraint
- 실제 학습된 내용을 최대한 활용하기 위해 아래와 같이 특이값들을 고정하도록 학습한다
- 이 값은 개별 특이값이 변하는 것은 허용하지만, 제곱합의 총 합은 유지되도록 학습하여 정보의 총량이 일정해지는 방향으로 학습하도록 한다
3. Loss Function
- 여기서 m은 사전 학습된 것의 개수를 나타낸다.
- 다시 말해 clip의 layer수가 된다
4. Experiment
- 특이하게, FF++로 train, val을 나누는게 아니고, FF++로 train, celeb-v2로 val을 하고 있음
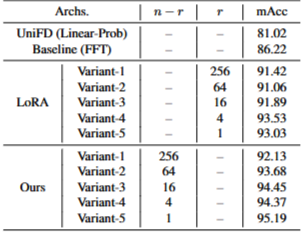
- 이거는 full fine tuning이랑 비교한 건데, n-r이 위에서 말하는 를 학습하는 방식임
- 여기서 r이 작아질 수록 성능이 올라가는 모습을 보이는데 이는 적은 양을 학습하고도 좋은 성능을 거두도록 하는 방식을 말함
- 한가지 의심스러운 건, acc기반인데 auc기반이면 r이 작아질 수록 성능이 떨어지지 않았을까? 하는 의심이 들음
- 여기서 주장하는 top-k rank 를 1로 해야한단 소리인데,,, fake 학습 내용에 잡다한 noise가 없어서 좋다는 말인가?
- BCE loss 기반이면 눈에 띠는 특성 하나를 딱 관찰하면 된다는 말인듯?
5. Conclusion
- 내가 정리한 것
- manifold관점의 접근인듯?
- 해당 개념에 대해 공부해 보고 접근해 봐도 유의미 할 것 같음
- 추가적으로 t축 에서 위조가 들어가는 sadtalker같은데서 파악이 안되는데 이건 너무 한계점인듯?

이것저것 다 합니다.