문제
- Solve the exercise problem 14 of the chapter 7.

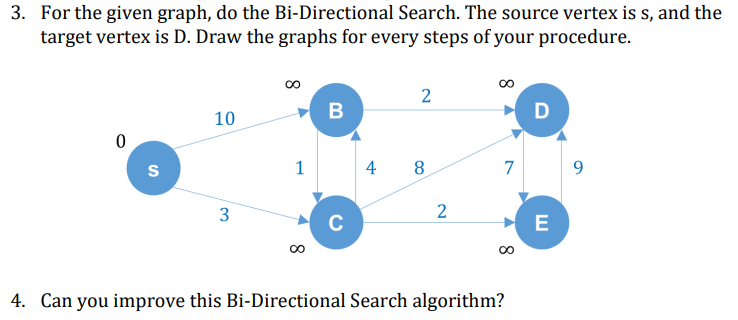
2. Chap07 - 14번 문제
Merge Sort에서는 1) 분할하는 과정과 2) 병합하는 과정이 순차적으로 진행된다.
1) 분할
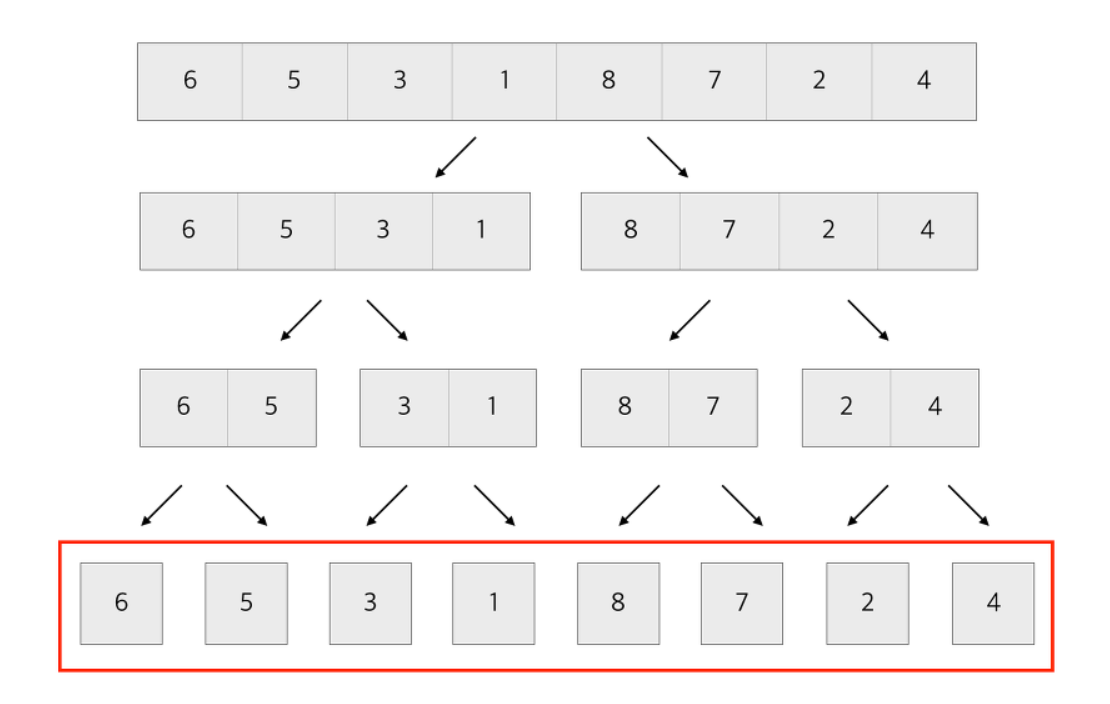
총 N개의 데이터에서, 1개씩 분할하려면
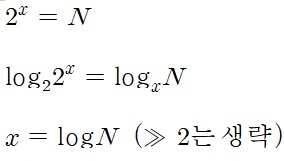
logN번의 단계를 진행하면서 분할해야 한다.
이때, 새로운 부분 배열에 원래 배열에 있던 것을 담는 과정에서 결국 모든 데이터를 한번씩 돌면서 방문하면 각 단계마다 N개의 데이터를 방문하므로
분할할 때 총 logN단계 * (N개의 데이터를 돌면서 새로운 배열에 담음) = NlogN 번의 연산을 수행한다고 판단했다.
2) 합병
합병 단계에서는 1) 분할 단계와 반대로,
logN단계에 걸쳐 각 단계마다 N개의 데이터를
합병하는 단계에서는 부분부분 데이터를 비교해서 합치는데, 결국에는 각 단계마다 전체 N개의 데이터를 다 한번씩 돌면서 방문하면서 비교하므로 N번의 연산이 필요하다.
합병할 때에는 총 logN단계 * (N개의 데이터를 돌면서 비교 연산) = NlogN 번의 연산을 수행한다.

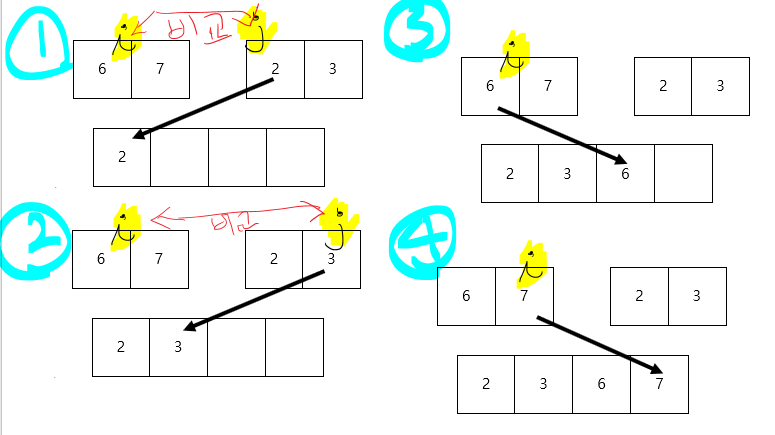
그림 출처 : https://devlimk1.tistory.com/138
따라서
1) 분할 : NlogN
2) 합병 : NlogN
총 2NlogN의 시간복잡도가 걸린다고 판단했다.
3. 양방향 다익스트라 과정
S에서 D로 갈 때의 최소 가중치 경로를 구하는 알고리즘
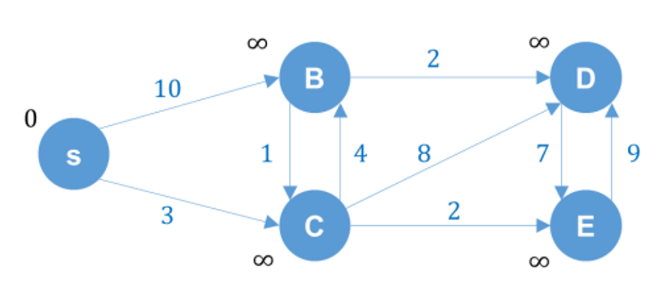
나는 아래와 같은 과정으로 진행했다.
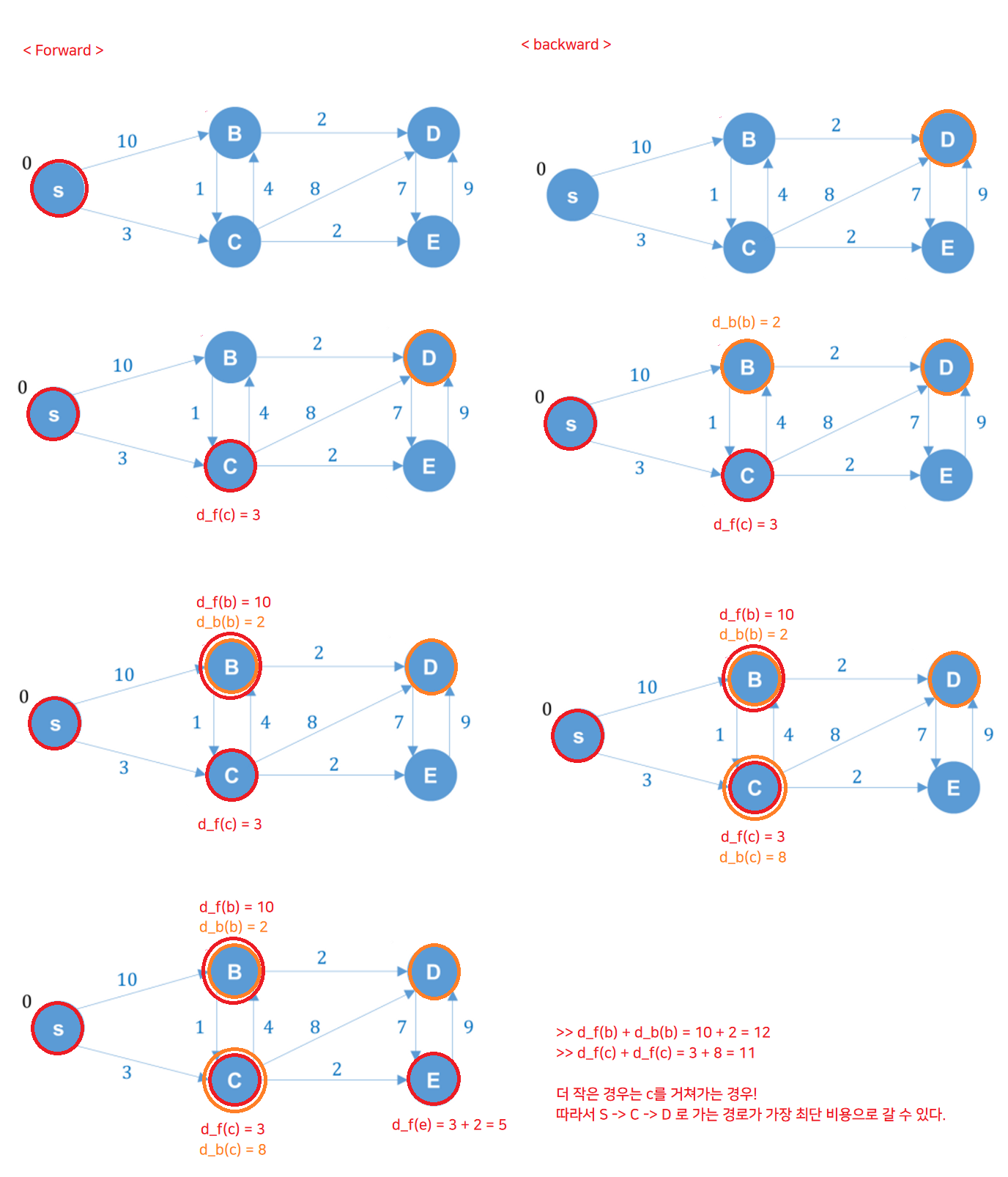
위와 같은 과정을 거치면서 앞쪽에서 출발하는 경우와 뒤쪽에서 출발하는 경우에
크로스된 후 한 번 더 가서 크로스가 되면, 여러 경우 중 더 작은 비용이 드는 경로를 뽑으면 된다.
원리 참고 :
https://copenguin.tistory.com/79
https://twinstarinfo.blogspot.com/2019/11/mit-introduction-to-algorithms-lecture_26.html
4. Bi-Directional Search을 개선할 수 있는가
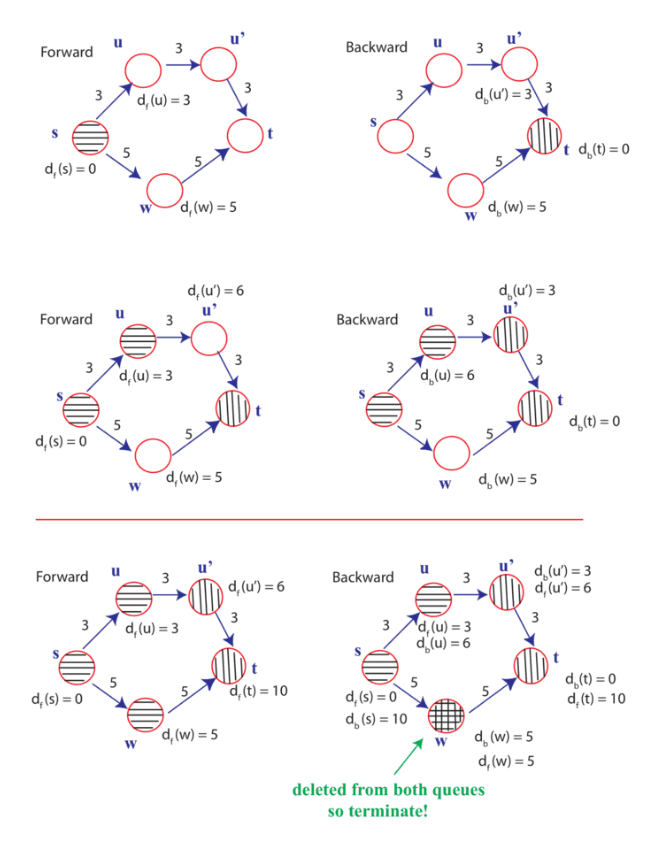
위 과정에서, 5번째 그림 (Forward 쪽 3번째 그림)을 보면,
s -> u 까지 진행한 상황에서 u'을 먼저 선택하지 않고 우선으로 먼저 다음 대기로 있었던 w를 선택하면서 진행한다.
그러나 w를 선택하는 것보다 u'을 선택했다면 더 빠르게 경로를 찾을 수 있었을 것이다.
따라서 우선순위 큐를 이용해, 기존에 다음 대기로 담아져 있었던 노드들과 함께 새로운 대기 상태의 노드들을 같이 담고
간선 가중치가 더 낮은 것을 우선순위큐 맨 앞으로 두어 먼저 빼면서 u'을 보다 먼저 방문할 수 있도록 하면 더 빠른 시간복잡도로 개선할 수 있을 것이라 생각한다.
