- Describe linear median finding algorithm. Show that its time complexity is Θ(n).
- In hashing function, why the coefficient a should not be 0?
- Read chapter 8.4. Solve example 8.1 in the chapter.
- Use the birthday dataset, do the followings:
4.1. Put them into your unsorted array using set.
4.2. Order them with the birth day. You should consider the following algorithms.
- Basic quick sort
- Pivot X = A[0] or A[n-1]
- Intelligent quick sort
- Pivot X = median of A
- Paranoid quick sort
- Pivot X = E(Good choice)
- Tuple sort 1) The month comes first, and the date second 2) The date comes first, and the month second
4.3. Compare the sorting algorithms
1. 선형적으로 중간 값을 찾는 알고리즘 - 시간복잡도Θ(n)
Θ(Big-Theta) 표기법
- 평균 시간복잡도를 나타냄
- O(Big-O), Ω(Big-Omega) 표기법의 절충안 (즉, 교집합)
선형적으로 중간 값을 찾을 때,
- 가장 빠른 경우 :
Ω(1)orΩ(n)모든 정렬의 값이 미리 정렬되어 있는 경우가 가장 베스트인 경우이다. 이 경우에는 바로 중간 인덱스의 값을 가져오면 중간 값을 찾을 수 있기 때문에,Ω(1)의 시간복잡도가 걸릴 것이다. 또는 정렬을 한 후 중간 값을 찾을 때 삽입 정렬, 쉘 정렬, 기수 정렬, 카운팅 정렬에서 최선의 경우 O(n)이 나오기 때문에Ω(n)이라고 볼 수도 있다.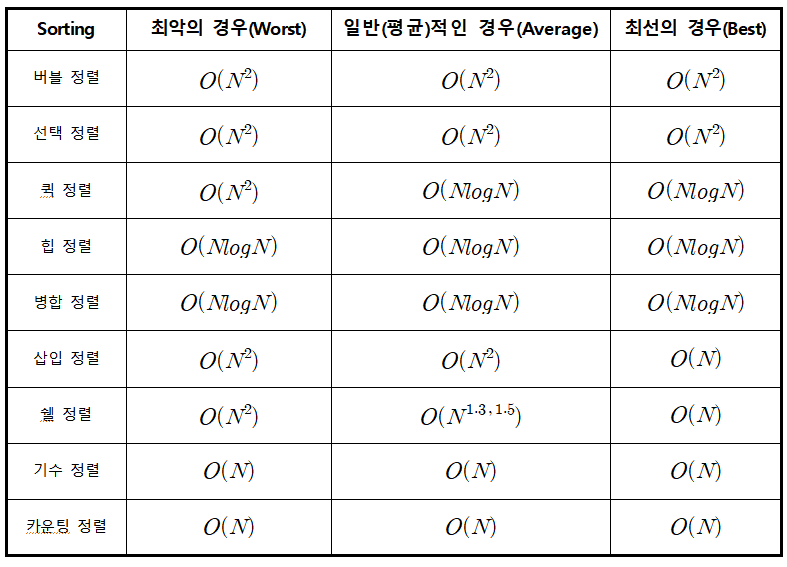
- 가장 최악의 경우(중 그나마 빠른 경우) :
O(n)중간 값을 찾을 때 가장 최악의 경우는 모든 인덱스 값이 정렬되지 않고 복잡하게 섞여 있는 경우이다. 최악의 경우에서 그나마 빠른 경우로는 기수 정렬과 카운팅 정렬을 이용해 작업할 때O(n)의 시간복잡도가 걸린다.
따라서 평균적인 경우에는 다음 그래프를 토대로,
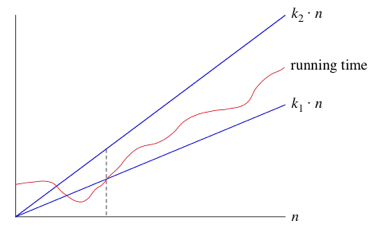
수행 시간이 O(n), Ω(n)이라면 평균 시간복잡도도 Θ(n) 이 된다.
참고 :
https://yabmoons.tistory.com/250
http://www.ktword.co.kr/test/view/view.php?m_temp1=6212&id=1420
https://jinseok-gamedev.tistory.com/140
https://memostack.tistory.com/57
2. 해싱 함수에서, a가 0이면 안 되는 이유
해싱 함수를 예를 들어 h(p,m) = (h(ak + b) mod p) mod m 이라고 설정했을 때,
p는 매우 큰 수를 의미하고,
a,b는 임의의 숫자들로, {0, 1, …. p-1}이다.
이때 a가 0이면 데이터의 키 값이 중요한데 죽어버리게 된다.
a로 인해 해싱의 값이 크게 바뀌기 때문에, a는 0이 되면 안 된다.
3. Read chapter 8.4. Solve example 8.1 in the chapter.
n = key의 개수
m = bucket의 개수
Theorem 8.5
각 키가 search 키일 가능성이 동일한 경우, 성공적인 검색의 평균 비교 수 :
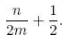
Example 8.1
키가 균일하게 분포되어 있고 n = 2m일 경우, 모든 검색이 실패할 때마다 2m/m = 2개의 비교만 필요하며, 성공적인 검색을 위한 평균 비교 횟수는
위의 공식에 n = 2m을 대입해서 아래와 같이 구할 수 있다.
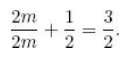
즉, 평균적으로 약 1.5번의 비교를 통해 성공적으로 검색할 수 있다.
4. 생일 데이터 문제
1. Basic Quick Sort
package week4;
import java.util.HashSet;
import java.util.List;
public class homework4_basicQuickSort {
public static void main(String[] args) {
CSVReader csvReader = new CSVReader();
// 4.1. set을 이용해 정렬되지 않은 배열에 넣기
List<List<String>> a = csvReader.readCSV();
csvReader = new CSVReader();
// 4.2.1 Basic Quick Sort : Pivot X = A[0] or A[n-1]
// 여기에서는 Pivot을 A[0]으로 설정
long startTime = System.currentTimeMillis(); // 정렬 시작 시각
basicQuickSort(a, 0, a.size() - 1); // Basic Quick Sort
long endTime = System.currentTimeMillis(); // 코드 끝난 시각
long durationTimeSec = endTime - startTime;
System.out.println("<Basic Quick Sort>");
System.out.println("실행 시간 : " + durationTimeSec + "m/s"); // 밀리세컨드 출력
}
// a[idx1]과 a[idx2]의 값을 바꾸는 함수
static void swap(List<List<String>> a, int idx1, int idx2) {
List<String> t = a.get(idx1);
a.add(idx1, a.get(idx2));
a.remove(idx1+1);
a.add(idx2, t);
a.remove(idx2 + 1);
}
// 4.2.1 Basic Quick Sort
static void basicQuickSort(List<List<String>> a, int left, int right) {
if (left >= right)
return;
int pl = left; // 왼쪽 커서
int pr = right; // 오른쪽 커서
List<String> x = a.get(left); // 피벗
do {
while (Double.parseDouble(a.get(pl).get(2)) < Double.parseDouble(x.get(2)) && pl <= pr) pl++;
while (Double.parseDouble(a.get(pr).get(2)) > Double.parseDouble(x.get(2)) && pl <= pr) pr--;
swap(a, pl++, pr--);
} while (pl <= pr);
swap(a, pl, left); // 피벗과 pl을 교환
// 교환된 후에는 피벗이었던 요소는 이제 pl에 위치함
basicQuickSort(a, left, pl - 1);
basicQuickSort(a, pl + 1, right);
}
}2. Intelligent Quick Sort
package week4;
import java.util.List;
public class homework4_intelligentQuickSort {
public static void main(String[] args) {
CSVReader csvReader = new CSVReader();
// 4.1. set을 이용해 정렬되지 않은 배열에 넣기
List<List<String>> a = csvReader.readCSV();
csvReader = new CSVReader();
List<List<String>> b = csvReader.readCSV();
csvReader = new CSVReader();
List<List<String>> c = csvReader.readCSV();
// 4.2.2 Intelligent Quick Sort : Pivot X = median of A
long startTime = System.currentTimeMillis(); // 정렬 시작 시각
intelligentQuickSort(a, 0, a.size() - 1); // Intelligent Quick Sort
long endTime = System.currentTimeMillis(); // 코드 끝난 시각
long durationTimeSec = endTime - startTime;
System.out.println("<Intelligent Quick Sort>");
System.out.println("실행 시간 : " + durationTimeSec + "m/s"); // 밀리세컨드 출력
}
// a[idx1]과 a[idx2]의 값을 바꾸는 함수
static void swap(List<List<String>> a, int idx1, int idx2) {
List<String> t = a.get(idx1);
a.add(idx1, a.get(idx2));
a.remove(idx1+1);
a.add(idx2, t);
a.remove(idx2 + 1);
}
// 4.2.2 Intelligent Quick Sort
static void intelligentQuickSort(List<List<String>> a, int left, int right) {
int pl = left; // 왼쪽 커서
int pr = right; // 오른쪽 커서
List<String> x = a.get((pl + pr) / 2); // 피벗
do {
while (Double.parseDouble(a.get(pl).get(2)) < Double.parseDouble(x.get(2))) pl++;
while (Double.parseDouble(a.get(pr).get(2)) > Double.parseDouble(x.get(2))) pr--;
if (pl <= pr)
swap(a, pl++, pr--);
} while (pl <= pr);
if (left < pr) intelligentQuickSort(a, left, pr);
if (pl < right) intelligentQuickSort(a, pl, right);
}
}3. Paranoid quick sort
package week4;
import java.util.List;
public class homework4_paranoidQuickSort {
public static void main(String[] args) {
CSVReader csvReader = new CSVReader();
// 4.1. set을 이용해 정렬되지 않은 배열에 넣기
List<List<String>> a = csvReader.readCSV();
csvReader = new CSVReader();
// 4.2.3 Paranoid quick sort : Pivot X = E(Good choice)
long startTime = System.currentTimeMillis(); // 정렬 시작 시각
paranoidQuickSort(a, 0, a.size() - 1); // Paranoid Quick Sort
long endTime = System.currentTimeMillis(); // 코드 끝난 시각
long durationTimeSec = endTime - startTime;
System.out.println("<Paranoid Quick Sort>");
System.out.println("실행 시간 : " + durationTimeSec + "m/s"); // 밀리세컨드 출력
}
// a[idx1]과 a[idx2]의 값을 바꾸는 함수
static void swap(List<List<String>> a, int idx1, int idx2) {
List<String> t = a.get(idx1);
a.add(idx1, a.get(idx2));
a.remove(idx1+1);
a.add(idx2, t);
a.remove(idx2 + 1);
}
// 4.2.3 Intelligent Quick Sort
static void paranoidQuickSort(List<List<String>> a, int left, int right) {
int pl = left; // 왼쪽 커서
int pr = right; // 오른쪽 커서
List<String> x = getPivot(a, left, right); // 피벗
do {
while (Double.parseDouble(a.get(pl).get(2)) < Double.parseDouble(x.get(2))) pl++;
while (Double.parseDouble(a.get(pr).get(2)) > Double.parseDouble(x.get(2))) pr--;
if (pl <= pr)
swap(a, pl++, pr--);
} while (pl <= pr);
if (left < pr) paranoidQuickSort(a, left, pr);
if (pl < right) paranoidQuickSort(a, pl, right);
}
// pivot을 설정하는 메소드
private static List<String> getPivot(List<List<String>> a, int left, int right) {
int mid = left + (right - left) / 2;
if (Double.parseDouble(a.get(left).get(2)) > Double.parseDouble(a.get(mid).get(2))) {
swap(a, left, mid);
}
if (Double.parseDouble(a.get(left).get(2)) > Double.parseDouble(a.get(right).get(2))) {
swap(a, left, right);
}
if (Double.parseDouble(a.get(mid).get(2)) > Double.parseDouble(a.get(right).get(2))) {
swap(a, mid, right);
}
return a.get(mid);
}
}4. Tuple sort : 첫 번째 원소부터 정렬 1) month - First, date - Second
package week4;
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class homework4_tupleSortMonthFirst {
public static void main(String[] args) {
CSVReader csvReader = new CSVReader();
// 4.1. set을 이용해 정렬되지 않은 배열에 넣기
List<List<String>> a = csvReader.readCSV();
csvReader = new CSVReader();
// 4.2.4 Tuple sort : 첫 번째 원소부터 정렬
// 1) month - First, date - Second
long startTime = System.currentTimeMillis(); // 정렬 시작 시각
tupleSort_monthFirst(a); // Tuple Quick Sort
long endTime = System.currentTimeMillis(); // 코드 끝난 시각
long durationTimeSec = endTime - startTime;
System.out.println("<Tuple Sort - 1) Month First>");
System.out.println("실행 시간 : " + durationTimeSec + "m/s"); // 밀리세컨드 출력
}
// 4.2.3 Intelligent Quick Sort
// 1) month - First, date - Second
public static void tupleSort_monthFirst(List<List<String>> a) {
Collections.sort(a, new Comparator<List<String>>() {
@Override
public int compare(List<String> o1, List<String> o2) {
int o1_month = Integer.parseInt(o1.get(2).substring(0, 2));
int o1_day = Integer.parseInt(o1.get(2).substring(3));
int o2_month = Integer.parseInt(o2.get(2).substring(0, 2));
int o2_day = Integer.parseInt(o2.get(2).substring(3));
if (o1_month == o2_month) {
return o1_day - o2_day;
}
return o1_month - o2_month;
}
});
}
// 2) date - First, month - Second
public static void tupleSort_dateFirst(List<List<String>> a) {
Collections.sort(a, new Comparator<List<String>>() {
@Override
public int compare(List<String> o1, List<String> o2) {
int o1_month = Integer.parseInt(o1.get(2).substring(0, 3));
int o1_day = Integer.parseInt(o1.get(2).substring(3));
int o2_month = Integer.parseInt(o2.get(2).substring(0, 3));
int o2_day = Integer.parseInt(o2.get(2).substring(3));
if (o1_day == o2_day) {
return o1_month - o2_month;
}
return o1_day - o2_day;
}
});
}
}5. Tuple sort : 두 번째 원소부터 정렬 2) date - First, month - Second
package week4;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class homework4_tupleSortDateFirst {
public static void main(String[] args) {
CSVReader csvReader = new CSVReader();
// 4.1. set을 이용해 정렬되지 않은 배열에 넣기
List<List<String>> a = csvReader.readCSV();
csvReader = new CSVReader();
// 4.2.4 Tuple sort : 두 번째 원소부터 정렬
// 2) date - First, month - Second
long startTime = System.currentTimeMillis(); // 정렬 시작 시각
tupleSort_dateFirst(a); // Tuple Quick Sort
long endTime = System.currentTimeMillis(); // 코드 끝난 시각
long durationTimeSec = endTime - startTime;
System.out.println("<Tuple Sort - 2) Date First>");
System.out.println("실행 시간 : " + durationTimeSec + "m/s"); // 밀리세컨드 출력
}
// 4.2.3 Intelligent Quick Sort
// 2) date - First, month - Second
public static void tupleSort_dateFirst(List<List<String>> a) {
Collections.sort(a, new Comparator<List<String>>() {
@Override
public int compare(List<String> o1, List<String> o2) {
int o1_month = Integer.parseInt(o1.get(2).substring(0, 2));
int o1_day = Integer.parseInt(o1.get(2).substring(3));
int o2_month = Integer.parseInt(o2.get(2).substring(0, 2));
int o2_day = Integer.parseInt(o2.get(2).substring(3));
if (o1_day == o2_day) {
return o1_month - o2_month;
}
return o1_day - o2_day;
}
});
}
}4.3. 비교
(2번씩 실행해서 실행 시간 비교)

회고
내가 구현한 Tuple Sort는 먼저 두번째 원소부터 모두 정렬한 후 첫번째 원소를 보고 정렬한 게 아니라, 한번 비교정렬 할 때 두번째 원소가 같으면 첫번째 원소를 정렬하고.. 이런 식으로 해서 조금 의도와는 다르게 구현한 것 같다. 잘못 구현한 것 같아서 다음에 한번 더 보고 수정해보아야 겠다.
