1. 한 줄 요약
visuomotor policy를 conditional denoising diffusion process로 표현하여 로봇 행동을 생성하는 diffusion policy를 소개함. diffusion을 통해 path 생성하므로 multimodal action에 대해 이점을 가지고, 고차원 행동 공간에 적합함.
visuomotor policy를 위한 diffusion model을 위해 아래 3가지의 기여를 제안.
- receding horizon control
- visual conditioning
- time-series diffusion transformer
2. 문제 정의
로봇의 action을 predict하는 문제는 학습을 시키면 아래 3가지 이유 때문에 다른 supervised learning 문제보다 어려워짐.
- action이 multimodal distribution이라는 것.
- sequential correlation을 갖고 있다는 것.
- 높은 정확도가 필요하다는 것.
3. 기존 접근의 한계
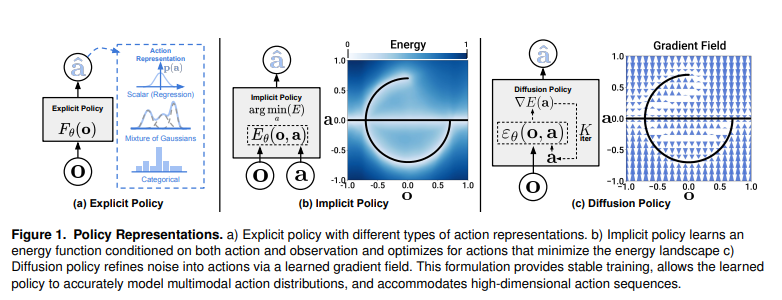
fig1.a explicit policy
- 형태로, observation이 들어오면 action을 출력하는 함수를 학습함.
- multi-modality를 가지는 경우, action을 표현하기 어려워짐.
fig1.b implicit policy
-
의 형태로, 주어진 관측 에 대해 를 최소화하는 행동 를 출력하도록 학습시킴.
-
multi-modality를 더 잘 표현할 수 있지만, 훈련 과정에서 Negative sampling이 필요하며, 계산 과정이 불안정하고 계산 비용이 큼.
💡Negative Sampling이란?
정답 데이터뿐 아니라, 오답 데이터를 의도적으로 섞어줘서 모델이 뭐가 틀린 건지 명확하게 배우게 하는 기법.
Energy-based model이나 Implicit policy는 어떤 행동이 좋은지뿐 아니라, 어떤 행동이 나쁜지를 알아야 Energy Landscape를 제대로 형성할 수 있어서 필수적임.
4. 핵심 아이디어
fig1.c diffusion policy를 제안
- 본 논문에서 제안. Denoising Diffusion 방식으로 로봇 행동을 생성함.
- multi-modal distribution: action score function의 gradient를 학습하고, Langevin Dynamics sampling을 수행함으로써 diffusion policy는 임의의 normalizable distribution을 표현할 수 있음.
- high dimensional output space: image 생성에서의 탁월한 성능에서 알 수 있듯, diffusion model은 고차원의 output space에 유리하며, 이는 sequential한 joint command를 생성할 수 있게 함.
- stable training: diffusion policy는 에너지 함수의 기울기를 학습함으로써, 기존의 에너지 함수 자체를 학습할 때 Negative sampling을 해서 생기는 학습 불안정성을 우회할 수 있음.
5. 방법 (training step & execution)
Engineering Ideas
receding horizon control
- 미래 H step을 내다보고 계획하고, 그중 앞부분만 실행, 한 스텝 진행 후 다시 H step을 반복하는 것.
- 이를 통해 closed-loop manner로 action을 다시 계획할 수 있음.
- long horizon planning과 responsiveness의 밸런스 잡음.
visual conditioning
- 시각적 관측값을 데이터 분포의 일부가 아닌, condition 정보로 처리됨.
- 이를 통해 denoising step이 몇 번이건 간에 visual information은 단 한 번만 추출하게 되고, 계산량을 줄일 수 있게 됨.
time-series diffusion transformer
- CNN 기반 모델의 over-smoothing 효과를 최소화하고 고주파 동작 변화 및 속도 제어가 필요한 작업에 적합한 transformer 기반 diffusion network를 제안함.
- 이미지 생성을 위한 diffusion model에선 CNN을 사용하지만, sequential한 action 출력에는 transformer가 더 적합하다는 뜻인 듯.
visuomotor policy를 위한 diffusion model
- output이 로봇의 action이 되도록 변경.
- 노이즈 제거 과정을 observation에 조건화하여, 현재 observation에 맞는 action sequence를 생성하게 함.
- CNN based: observation에 대한 feature는 한 번만 뽑고 재사용.
- Transformer based: obs_feat를 K, V로 cross-attention. 한 번만 feature를 뽑고, K, V로 사용하여 재사용함.
Closed-loop action sequence prediction
temporal한 일관성/부드러움과 long-horizon planning 모두 가능해야 함.
Time step t에서 policy는 To개의 관측값을 입력으로 받아 Tp개의 행동을 예측하며, 이 중 Ta개만큼의 행동을 re-planning 없이 로봇에서 실행함.
- : the observation horizon
- : the action prediction horizon
- : the action execution horizon
Key Design Decisions
Diffusion policy를 위한 network architecture design을 의미.
CNN vs Transformer
CNN으로 프로토타입 만들어 성능 한계 확인한 뒤, 필요에 따라 transformer로 개발하라고 제안함.
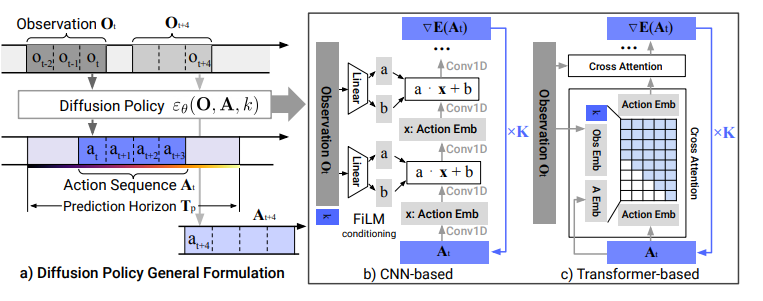
- CNN based backbone
- 1D temporal CNN을 사용 (시간축을 따라 sampling하는 구조). U-Net 구조로 down-sampling → up-sampling을 통해 denoising network 역할을 함.
- FiLM conditioning을 통해 observation의 특징을 한 번 추출하고 재활용.
- 하이퍼파라미터 튜닝에 민감하지 않고, 대부분의 작업에서 잘 동작하지만, 고주파 작업에서 성능 저하됨 (temporal convolution이 저주파에 더 강하기 때문이라 정도로 논문에선 언급. up-sampling → down-sampling 과정을 거치는 과정이 고주파에 불리한 아키텍처인가?).
- Transformer based backbone
- 노이즈가 섞인 action이 transformer의 decoder 블록으로 전달되며 denoising.
- CNN에서의 over-smoothing 문제를 줄이기 위해 transformer를 사용.
- 하이퍼파라미터에 더 민감. diffusion에만 국한되는 건 아님.
Visual Encoder
- raw image를 embedding 로 임베딩함. diffusion policy와 함께 학습됨.
- ResNet-18을 인코더로 사용.
Noise Schedule
- 경험적으로 Square Cosine Schedule이 가장 잘 동작함.
Accelerating Inference for Real-time Control
- DDIM(Denoising Diffusion Implicit Models) 접근 방식을 통해, 훈련 시의 denoising 횟수(100회)와 추론 시의 denoising 횟수(10회)를 분리. 3080 GPU에서 0.1초의 지연시간을 달성함.
6. 실험 (태스크 / 베이스라인 / 메트릭)
15개의 task와 4개의 benchmark를 사용함.
sim, real, fully actuated, under actuated, rigid and fluid 등 다양한 조건에서 실험을 진행.
Diffusion policy가 이전의 SOTA보다 46.9%가량 평균 성공 확률이 더 올라간 걸 볼 수 있었음.
Push-T, Multimodal Block Pushing, Franka Kitchen 등에서 실험 진행함.
실제 환경에서는 2가지 HW 설정에서 4가지 real-world task에 대해 diffusion policy 성능 평가함. 각 설정마다 서로 다른 시연자로부터 수집한 학습 데이터를 사용.
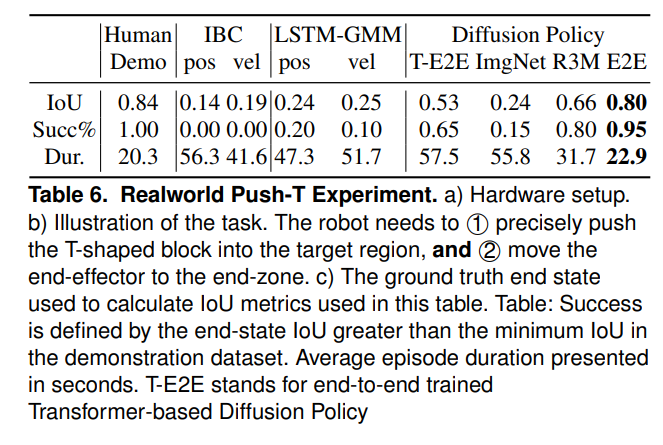
Push-T: diffusion policy의 2가지 아키텍처, 3가지 visual encoder에 대한 ablation을 수행. 위치 vs 속도 제어에 대한 비교도 수행.
모든 작업에서 CNN 백본 사용 + visual encoder를 end-to-end로 학습한 diffusion policy의 변형이 가장 우수.
Key findings
Short horizon multimodality
즉각적인 목표를 달성하기 위한 여러 가지 방법을 의미. diffusion policy는 Push-T에서 오른쪽/왼쪽 어디로든 균등하게 접근하는 법을 배움.
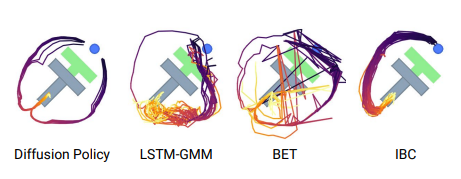
Long-horizon multimodality
여러 하위 목표를 일관되지 않은 순서로 완료하는 것을 의미. Block Push나 Kitchen Task에서 특정 object와 상호작용하는 것은 임의적임. 두 작업 모두 기준 모델 대비 큰 폭으로 성능이 향상됨.
Position control
diffusion policy는 position control에 더 유리함. 다른 baseline의 경우 velocity control에서 더 성능이 보였지만, diffusion policy의 경우 위치 제어에서의 더 큰 강점을 보임.
Trade-off in action horizon
action horizon이 길면 policy가 일관된 action을 보이고, 데모 데이터에서 아무것도 안 하는 시간에 대한 보상이 가능해지지만, reaction time을 길게 만들어서 성능을 떨어뜨림 (본 실험에서는 8 정도가 최적임을 확인함).
Robustness against latency
diffusion policy는 위치 제어를 사용하여 미래 행동 시퀀스를 예측함. 이는 제어 동안에 발생할 수 있는 latency(네트워크 계산, 이미지 처리 등등)에 대한 강건성을 줄 수 있음 (4 step 정도의 latency에서도 성능을 유지함). 속도 제어가 위치 제어보다 latency에 더 취약하다는 것도 발견함.
Stable to train
diffusion policy의 최적의 하이퍼파라미터가 대부분의 task에서 일관성을 보임을 확인.
Ablation Study
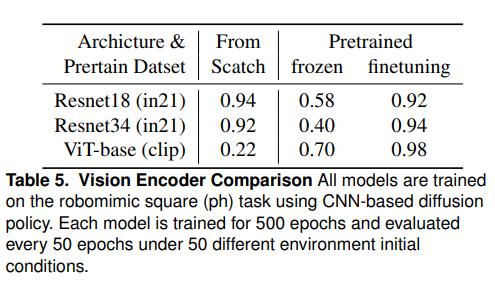
- Vision Encoder 학습 방법을 비교했음.
- 아키텍처
- ResNet-18
- ResNet-34
- ViT-B/16
- 학습 방법
- 처음부터 E2E로 학습 (from scratch)
- 사전 학습된 encoder를 고정 (Frozen)
- 사전 학습된 encoder를 policy network보다 10배 낮게 LR을 조정 (fine-tuning)으로 진행.
- 사전 학습 방법의 경우 ResNet은 ImageNet-21k(image → label)로, ViT-B/16은 CLIP(사진과 설명 텍스트 → 유사도 점수를 출력)으로 진행.
- 결과
- ViT를 처음부터 학습시키는 것은 대단히 어려움 (데이터 양에 제한이 있기 때문).
- 사전 학습된 encoder를 고정시키는 것도 성능이 낮았음. diffusion policy가 대중적인 사전 학습 방식과는 다른 형태의 시각적 표현을 선호함을 시사.
- 사전 학습된 vision encoder를 낮은 learning rate로 fine-tuning했을 때 가장 우수한 성능을 보임. CLIP 사전 학습된 ViT를 fine-tuning할 경우 성공률이 가장 컸음.
Real-world evaluation 1: Push-T
- baseline과의 비교
- Diffusion Policy는 95% 성공률과 평균 IoU 0.8 (인간: 0.84)로 인간에 가까운 성능 보임.
- IBC: 0%, LSTM-GMM: 20% 성공률.
- Robustness against perturbation
- 시연 중 T블록의 위치를 바꾸기, 시연 끝나고 T블록 위치 바꾸기, T블록 카메라를 손으로 가리는 등의 외란 주입.
- 모두 동작하며 T블록을 원래 위치로 잘 옮겼음. → 이전에 관찰되지 않은 관측에 대해서도 새로운 행동을 할 수 있음을 시사.
- Pretrained visual encoder vs end-to-end learning
- end-to-end learning이 pretrained visual encoder보다 더 성능이 좋은 것을 알 수 있음. 논문에 왜 pretrained보다 from scratch end-to-end가 더 좋은지는 명시되어 있지 않음.
Real-world evaluation 2: Mug Flipping
- 잡기, 뒤집기, 전/후방 잡기, 좌측 회전 등 강한 multi-modality를 가지는 task임.
- baseline과의 비교
- Diffusion policy는 90% 가량의 성공률, LSTM-GMM은 한 번도 제대로 못함.
- 실제 환경에서도 multi-modality를 갖는 행동에 대해 diffusion policy가 높은 성능 보임을 알 수 있음.
Real-world evaluation 3: Sauce Pouring & Spreading
- non-rigid body, 6-DOF, 주기적 행동 등을 실제 환경에서 할 수 있는지를 검증.
- 소스를 퍼고, 가운데에 붓고, 펴 바르는 건 장기 패턴과 단기 피드백 모두 필요한 task임.
- baseline과의 비교
- 붓기, 펴기 모두 인간에 근접한 성능을 보임.
- LSTM-GMM은 두 작업 모두에서 성능이 낮음. LSTM-GMM의 은닉 상태가 충분히 긴 이력을 포착하지 못해 단계 전환을 구분하지 못하였음.
7. 내 생각 & 잘 모르는 개념
1. 왜 chunk 간 전환에 Temporal Ensemble을 쓰지 않고, receding horizon을 썼을까?
- ACT 논문의 경우 매 step마다 action chunk를 추론한 뒤, 다음 행동을 수행할 때에는 여태 생성한 chunk에 있는 action의 값들을 가중평균해서 chunk-to-chunk 전환을 부드럽게 했음.
- Diffusion policy에선 chunk 전부를 사용하지 않고, 일부만 사용하여 ( 개의 action만 사용) 한 뒤, 나머지는 버림.
- 처음엔 TE의 주기를 좀 길게 가져가면 chunk를 가중평균해서 사용할 수 있을까 했지만, 시스템 관점 → K번의 denoising은 지연시간의 분산을 키우는 결과를 내게 됨. TE를 위해 몇 스텝마다 predict해야 할지 정하는 문제가 어려워진다고 판단됨.
- 즉, K번의 denoising 과정을 위해서 생긴 trade-off로 연산 시간, 지연의 분산 증가 등이 생겼는데, 이런 상황에서 closed-loop manner로 manipulation 하기 위해선 receding horizon 방법이 더 효과적이었을 것이라 생각됨.
2. 왜 real world에선 vision encoder를 from scratch end-to-end로 학습하는 게 더 성능이 좋을까? simulation과 결과가 다른 이유?
- 정확히 말하면, real world에선 fine-tuning을 직접 비교하진 않았음.
- 실제 환경에서는 from-scratch로 데모 데이터에 정확히 맞춘 representation을 학습하는 게 jittery 문제를 피하는 데에 더 안정적이었다는 해석도 있음.
3. 좀 더 active한 상황에서의 manipulation?
- feedback 제어가 가능하다곤 하지만, 결국 모두 정적인 환경에 manipulator만 움직이는 task로 보임.
- diffusion policy가 receding-horizon으로 closed-loop를 구현했다고 주장하지만, chunk의 동안은 open-loop임. 후속 연구인 RDP, DA-DP, DCDP가 이런 가정을 정면으로 다룬다고 함.
- Mobile manipulation 환경에서는 본 논문의 가정이 더 광범위하게 깨진다 — 고정 카메라, 짧은 horizon, 안정된 시야 등. M4Diffuser는 multi-view로, PoPi는 planner + 짧은 chunk 분리로, iDP3는 egocentric 표현으로 각자 보완한다고 함.
추가로 정리해야 할 개념
- Langevin, receding-horizon, FiLM, 1D CNN, cross-attention는 따로 정리 필요.
