1. 요약
general robotic model의 성공 요인은, open-ended task-agnostic training (모델 학습 시, task의 목록을 제한하지 않는다는 의미)와, 다양하고 거대한 로봇 데이터를 수용할 수 있는 capacity를 가진 모델 구조에 있다고 주장함. 이를 위해, high capacity를 가지는 robot transformer model과 거대한 데이터셋 구축을 했고, 데이터크기, 데이터 다양성, 모델 크기 등에 따른 모델의 performance및 generalization을 분석했으며, 제안한 모델이 일반화에 강하고, 데이터의 양보다는 다양성이 일반화 성능향상에 중요하다는 사실을 검증함.
2. 문제 정의
여태까지의 ml model이 거대한 데이터셋(image processing, NLP 등)에 의해 downstream task를 해결했듯이, robot task도 비슷하게 해결이 되지 않을까? 가 핵심인 듯.
다양한 로봇 태스크로 구성된 데이터만을 사용해, 단일하면서도 강력한 대규모 멀티태스크 백본(backbone) 모델을 학습할 수 있을까?
그리고 이러한 모델이 새로운 태스크, 환경, 객체에 대해 제로샷 일반화를 보여줄 수 있을까?
두 가지 주요 과제
트랜스포머 기반 정책을 넘어, 본 연구의 초점은 대규모 환경에서 일반화 가능하고 견고한 실제 로봇 조작에 있음.
- 적절한 데이터셋을 구성하는 것
- 좋은 일반화를 위해선 다양한 task와 설정을 포괄하는 규모와 범위를 모두 갖춘 데이터셋의 필요성.
- 13대의 로봇을 운용하며 17개월에 걸쳐 수집한 데이터셋을 사용.
- 적절한 모델을 설계:
- 효과적인 multi task 학습 위해선 high capacity의 모델이 필요. 언어 명령에 조건화된 task를 위해선 transformer 계열 모델이 강점을 가짐.
- camera image, instruction, motor command를 토큰으로 인코딩한 뒤 transformer에 입력하는 RT-1 (Robot Transformer 1)을 제안함.
- 기술적인 측면에서, 본 연구는 실시간 제어에 필요한 계산 효율성과 높은 용량 및 일반화 능력을 결합할 수 있도록 트랜스포머 기반 정책을 구축하는 방법을 살펴봅니다.
3. 기존 접근의 한계
새로운 Task나 다양한 real-world환경에 대한 generalization평가 부재
- 사실상 단일 Task만을 학습. 새로운 task나 다양한 real-world환경에 대한 generalization을 평가하지는 않음.
- 각 task당 demonstration set으로부터 task를 효과적으로 학습하는 데 초점을 맞춤 → task의 확장이나 일반화를 고려하지는 못함.
- 실제 로봇 운용에 필요한 실시간성이나, 모델 규모를 고려하지 않음.
4. 핵심 아이디어
- high capacity 와 inference time을 고려한 model architecture
- instruction과 6장의 이미지를 입력으로, manipulator와 mobile base의 제어 신호를 출력으로 하는 모델구조.
- insruction과 image를 early fusion하도록 FiLM레이어를 추가하여, model이 instruction의 실행에 필요한 특징에 주목하도록 모델을 설계.
- token learner와 token 중복 연산 피하는 방식을 통해 model의 inference time을 줄임(본 논문에선 3Hz로 inference함)
- open-ended task-agnostic training
- 모델 학습시 Task의 제한을 따로 걸어놓지 않음
- Dataset역시 Task를 제한하지 않고 instruction형태로 확장성을 갖도록 함
- diverse / large real robot data
- 13대 로봇, 17개월에 걸쳐 130k 데이터셋을 구축. task의 다양성, 데이터의 양 모두 확보.
- 데이터의 양과 / 다양성에 따른 model 성능 평가 통해서 해당 데이터셋 자체가 일반화성능의 핵심 요인임을 검증.
5. 방법
Environment
- 로봇
- 7DOF, Two finger gripper, mobile base 갖춘 Everyday Robots의 mobile manipulator를 사용.
- 환경
- 3가지 주방 기반 환경을 사용. 두 곳의 실제 주방과, 실제 주방을 모델로 한 훈련환경.
- 서로 다른 환경에서 정책 평가하며 정책의 실행능력 및 일반화 능력을 측정함.
dataset
- 데이터 규모: 13대의 로봇으로 17개월간 수집한 13만 개의 시연 데이터.
- 기술(Skill) vs 지시사항(Instruction):
- 기술: 동사 중심의 분류 (예: 집기, 열기)
- 지시사항: 구체적인 문장 중심의 분류 (예: "빨간 컵을 집어서 서랍에 넣어라") -> 총 700개 이상.
- 확장성: 새로운 물체나 복잡한 작업(Long-horizon)을 추가하기 쉬운 구조로 설계됨. → 가서 서랍을 열고, 안에 있는 간식을 꺼내서, 테이블 위에 놓아라. 처럼 여러단계의 하위 작업이 연결된 복잡한 임무(Long horizon)
model input / output
- input(이미지 / 텍스트): 이미지와 Text는 FiLM EfficientNet-B3을 통해 처리되며, Token Learner를 통해 compact set of token으로 변환됨.
- output(action token): Transformer를 통해 처리되고 action을 토큰화 하기 위해 각 action space를 256개의 bin으로 이산화함.(action space가 연속적이지 않음).
- RT-1은 Closed loop로 제어되며, terminate action을 생성하거나, 시간제한에 도달할때까지 3Hz로 동작함.
model architecture
- image feature extract:
- 6장의 이미지 sequence를 ImageNet으로 학습된 EfficientNet-B3모델에 통과시켜 토큰화 함.(300x300 이미지 6장을 9x9x512로 변환함)
- 81개의 visual token으로 flatten한 뒤 다음 레이어로 전달함.
- image, instruction early fusion
- instruction은 USE를 통해 임베딩(instruction을 숫자 벡터로 변환)됨.
- 임베딩은 사전학습된 EfficientNet에 추가된 identity-initialized FiLM Layer의 입력으로 사용되어 image encoder를 조건화 함.(image feature extraction 단계에 instruction에 해당하는 feature에 더 주목하도록 함)
- FiLM레이어 삽입하여 생기는 Side effect(사전 학습된 네트워크의 중간 활성화가 왜곡되어 사전 학습된 가중치를 사용하는 이점이 사라짐.)를 막기위해, 처음에는 FiLM Layer가 항등함수로 작동하여 사전 학습된 가중치의 기능을 보존하도록 함.
- Token Learner
- TokenLearner란 많은 수의 토큰을 더 적은 수의 토큰으로 매핑하도록 학습하는 elementwise attention 모듈임.
- attent 해야할 토큰의 수 압축하여 추론속도 높이기 위한 token learner를 사용.
- 정보에 기반하여 이미지 토큰을 soft-select할 수 있으며, 중요한 토큰 조합만 transformer레이어제 전달함.
- TokenLearner통해 81개의 visual token은 8개의 최종 토큰으로 sub-sample 되어 transformer에 전달됨.
- transformer
- 이미지당 8개씩 생성된 토큰은 히스토리의 다른 이미지와 결합되어, 위치 인코딩이 추가된 48개의 토큰이됨(6장의 이미지. 한장당 8개의 visual token.)
- Action Tokenizer(각 출력은 256개의 bin으로 이산화됨)
- 11차원 출력
- arm 움직임 위한 x y z roll pitch yaw
- 베이스 움직임 위한 x y yaw
- 세가지 모드: 팔 지어, 베이스 제어, 에피소드 종료
- 각 출력은 256개의 bin으로 이산화됨: multi-modal action 분포를 모드 평균내지 않고 잡을 수 있다고 함(추후 보충 필요)
- 11차원 출력
- Loss
- standard categorical cross-entropy entropy
- objective and causal masking
- 둘 다 이전 transformer기반 controller에서 사용됨.
Inference Speed
- TokenLearner를 사용하여 EfficientNet에서 생성되는 토큰 수를 줄임
- 토큰은 한번만 계산하고, 이후 추론에서 겹치는 윈도우에 재사용
- 3Hz로 inference함. 추론 시의 latency를 줄여야만 실제 로봇에 사용 가능한 모델이 되기 때문.
6. 실험 (태스크 / 베이스라인 / 메트릭)
6.1 실험환경 설정
Everyday Robots의 모바일 머니퓰레이터를 사용하여 세 가지 환경(실제 사무실 주방 두 곳과 이를 모델링한 학습 환경)에서 평가됨.
학습된 작업 성능 (Seen task performance) 평가
- 학습 데이터셋에서 추출한 명령을 사용. 물체 배치나 환경요소의 변화 포함되어있어, 현실적인 환경 변동성에 대한 일반화 능력이 요구됨.
- 물체 집기 36개, 물체 쓰러뜨리기 35개, 물체 똑바로 세우기 35개, 물체 옮기기 48개, 다양한 서랍 열기·닫기 18개, 서랍에서 물체 꺼내기·넣기 36개로 평가
처음 보는 작업의 일반화(Unseen tasks generalization) 평가
- 처음 보는 작업에 대한 일반화 평가하기 위해, 21개의 새로운 명령을 테스트
- 학습 데이터에 각 object와 skill은 일부 존재하지만, 새로운 조합으로 결합됨.
강건성 평가
- 방해물 강건성 30개, 배경 강건성 22개의 실제 작업 수행.
- 새로운 주방(다른 조명 / 배경), 다른 카운터 표면(패턴이 있는 식탁보 등)에서 평가함.
장기 시계 시나리오(Long-horizon scenarios)
- 더 현실적인 장기 시계 시나리오에 대한 일반화 평가
- 평가는 2개의 실제 주방에서 15개의 장기 시계 명령으로 구성. 각각 10개의 skill sequence를 수행해야 함.
- 테이블 위의 모든 물건을 어떻게 버릴것인가? 와 같은 상위 명령으로부터 SayCan시스템을 통해 자동으로 생성됨.
6.2 RT-1은 다수의 명령을 학습하고 새로운 작업·물체·환경에 일반화할 수 있는가?
본 논문에서 제안한 모델 다른 SOTA 모델 보다 Large real robot dataset을 동한 open-ended task-agnostic training에 더 적합하고 높은 성능을 이끌어내는지 비교.
동일 데이터셋으로 학습시킨 다른 모델과 전반적 성능 비교
-
RT-1의 전반적 성능, 일반화 능력, 강건성을 기존 모델과 비교.
-
Gato, BC-Z, BC-Z XL(BC-Z의 더 큰 버전)과 비교
-
unseen task, 방해물, 배경 변화를 적용하여 zero-shot 일반화 및 강건성을 평가.
-
결과: 전반적으로 일반화 성능 및 강건성이 타 모델보다 높음(→ 논문에서 보인 학습 방법론 및 거대한 데이터셋에 제안된 구조가 적합하다)
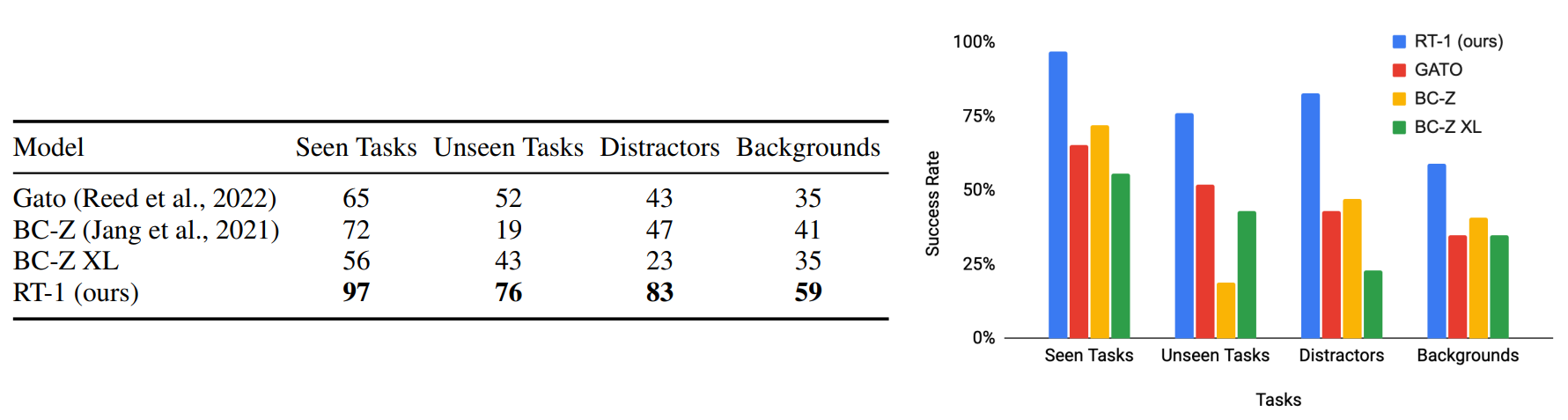
- unseen task: 76%수행 2등보다 24% 높음
- 방해물: 83%수행 2등보다 36%높음
- 배경: 59%수행 2등보다 18%높음
generalization to realistic instructions
-
현실적 시나리오에서의 알고리즘을 평가. 학습환경과 크게 다른 환경을 제공하여 일반화 성능을 평가
- 서랍에 간식을 다시 채우고, 쓰러진 양념병을 정리하고, 사람이 열어둔 서랍을 닫는 등.
-
일반화 수준(L1, L2, L3)
- L1: 새로운 카운터 배치와 조명 조건으로 일반화
- L2: 처음보는 방해물 물체로의 일반화
- L3: 완전히 새로운 작업 설정, 물체 또는 싱크대 근처와 같은 처음보는 위치로의 일반화.
-
결과
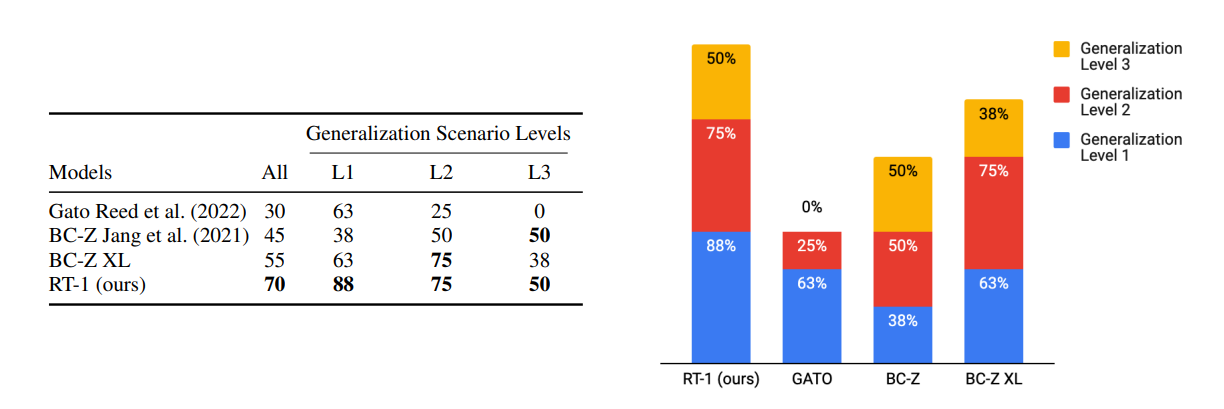
- 전반적인 일반화 성능이 다른 SOTA 모델보다도 높게 나옴.
- RT-1과 비슷한 파라미터 수인 BC-Z XL의 경우, L2에선 성능 비슷했으나, L3으로 넘어갔을때엔 일반화 성능이 RT-1보다 떨어짐.
6.3 시뮬레이션이나 다른 로봇 데이터 같은 이질적 데이터 소스로 모델을 더 발전시킬 수 있는가?
시뮬레이터 데이터를 추가한 뒤 성능평가
-
RT-1이 매우다른 데이터 소스를 학습에 통합하면서도 원래 작업의 성능을 희생하지 않고 개선할 수 있음을 보여줌.
-
실제 환경에서 온 데이터만 가지고 학습시켰을때와, 시뮬레이터에서 온 데이터를 섞어서 학습시켰을때 성능을 비교.
-
결과

- 실제로 본 object / skill에 대해 real only와 real + sim 데이터의 성능은 소폭(2%)감소.
- 하지만, 실제로 보지 않고 시뮬레이터에서만 본 object 에 대해선 성능이 대폭 상승함
- sim only object + seen skill: 64%상승
- sim only object + unseen skill: 26%상승
다른 로봇에서 수집한 데이터를 추가한 뒤 성능평가
-
서로 다른 로봇에서 수집한 데이터를 추가 결합한 실험을 수행.
-
KuKa bin-picking data를 추가한 데이터셋으로 성능을 비교함
- 209000개 bin-picking task 모든 성공 데이터를 추가
- RT-1에서 생성한 데이터셋과 외형, Action space, 배포된 환경의 외형과 동역학 distribution이 완전히 다름(RL agent가 수집했기 때문)
-
표준 classroom 평가와 bin picking평가를 사용함.
-
결과

- Kuka 데이터 혼합 모델은 원래 성능평가에서 2%정도의 감소(미미한 감소)를 보임.
- Bin-picking평가에서 두 로봇으로 같이 데이터 모은 모델이 39%성공률(17%상승됨)을 보임.
- Kuka로만 학습한걸로 하면 0% 성공확률로, 서로 다른 로봇간의 행동 전이는 어렵다는것을 보임.
6.4 다양한 방법은 Long horizon 로봇 시나리오에서 어떻게 일반화되는가?
SayCan framework 내에서 long horizonn 시나리오에서 low-level policy로서 RT-1의 성능을 다른 모델과 비교평가
-
SayCan 프레임워크 내에서 RT-1과 다양한 baseline을 실행함.
-
SayCan은 다수의 저수준 명령을 결합해, 고수준 명령을 수행함. 가능한 고수준 명령의 수는 skill의 수에 따라 증가함.→ RT-1의 기술 폭이 충분히 발휘됨.
-
Long horizon task 의 성공률은 길이에따라 지수적으로 감소하므로, manipulation의 높은 성공률이 중요함.
-
결과
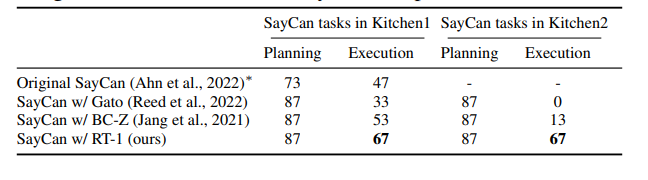
- planning success rate: 로봇이 그 명령에 대해 올바른 skill들을 골랐는가?
- execution success rate: 로봇이 그 명령을 실제로 성공적으로 수행했는가?
- 같은 LLM플래너 위에 low level policy만 갈아끼웠을때, RT-1이 long horizon에서 성공률이 가장 높음.
- 각 skill에 대해 일반화 성능 및 강건성이 높은 RT-1이 Long horizon 로봇 시나리오에서 높은 성능을 보임.
6.5 데이터 양과 다양성에 따라 일반화 성능은 어떻게 변하는가?
-
robotics에선, data의 사이즈는 primary bottleneck이 아니며, maximum size는 latency requirement에 의해 제한됨.
-
본 연구에서는 size에 대한 ablation이 아닌, 데이터셋의 size와 diversity가 어떤 영향을 끼치는지에 주목함.
-
real robot에서 데이터 수집하는 작업의 비용은 크기때문에, 원하는 성능과 일반화를 위해 데이터를 정량화 하는 작업은 중요함.
-
실험 설계. 데이터 양과 다양성의 효과를 분리하기 위해 두 종류의 축소 데이터셋을 만들었음.
- 양 축소 (다양성 유지): 모든 작업을 그대로 두되, 데이터가 많은 작업에서 예시 수를 잘라냄
- 작업당 200개 제한 → 전체의 51%
- 작업당 100개 제한 → 전체의 37%
- 작업당 50개 제한 → 전체의 22.5%
- 다양성 축소 (양 유지): 데이터가 적은 작업들을 통째로 제거
- 작업의 75%만 남김 → 전체 데이터의 97% 유지
- 양 축소 (다양성 유지): 모든 작업을 그대로 두되, 데이터가 많은 작업에서 예시 수를 잘라냄
-
결과
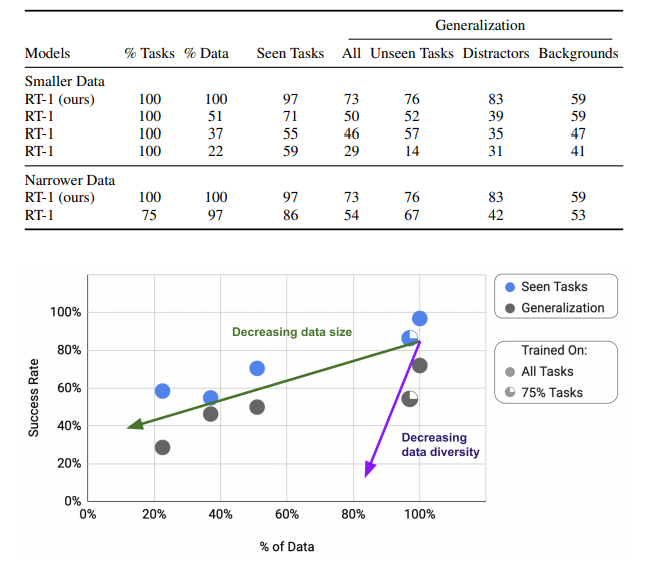
- 데이터의 양을 줄이는것보다, Task의 양을 줄이는게 Model의 성능을 더 크게 줄였음.(data의 97%를 유진한 채, task의 25%를 제거했는데, dataset을 49%까지 줄였을때와 비슷한 수준의 generalization performance를 보임)
7. 내 생각
- 메커니즘 납득
- 모델 아키텍처
- FiLM을 통한 image와 text의 early fusion의 경우, robot task 를 수행함에 있어서 image feature를 적은 파라미터로 쉽게 뽑아낼 수 있는 방법이라 생각함.
- 명시적으로 joint 입력을 closed loop로 처리하지 않은 점
- RT-1은 명시적으로 joint값을 closed loop으로 처리하지 않고 매 추론마다 다음 joint값을 image observation으로 implicit하게 추론함.
- 모든 입력을 image + text token으로 통일하면 robotics문제를 일반적인 NLP나 CV 문제처럼 다룰 수 있게 하며, cross-embodiment를 더욱 손쉽게 가능하게 해줌.
- 하지만, 각 joint의 각도값은 사실상 공짜로 주어지는 데이터인데, 이 데이터를 사용하지 않고 robot 문제를 푸는건 내 관점에선 조금 이상함. ACT나 Diffusion Policy의 경우 joint값을 closed loop로 처리했는데, joint값을 명시적으로 사용한다면 본 논문에서 구축한 거대한 dataset을 더 잘 사용할 수 있지 않을까?
- 데이터셋과 실제 inference frequency간의 Gap
- 3Hz로 제어했는데, 인간시연자의 데이터는 아마 더 고주파수의 데이터임. 이런 Gap에 대해선 어떻게 처리하는지 의문.
- chunking없이 부드러운 모션이 가능한지?
- 이거 위치제어인데, chunking도 없고 이전 joint값도 사용하지 않았음. 이런 상황에서 부드러운 움직임이 가능한지? 해당 모델 사용했을때, 로봇의 진동과 같은 factor를 측정했으면 더 좋았을듯.
- system level robustness
- 현 논문에선 입력으로 vision + instruction으로 모델을 사용하며, joint값은 사용하지 않음.
- 하지만, visoin sensor의 경우, 일부 센서가 오동작할수도있고, port가 반대로 껴져있을수도 있음(실제 로봇에서 이런 일은 흔하게 일어날만한 일이라고 생각)
- 즉 system level에서 로봇이 이상한 데이터를 수집하더라도, 그 성능을 유지할 수 있도록 데이터셋을 구성할 수는 없는지?
- 모델 아키텍처
- 실험 증거 납득
- Large robot dataset에 대한 capacity 분석
- 다른 model과의 비교의 경우, 물론 현재 모델이 large dataset에 대해 capacity가 강한지 비교분석 하려는 점이었으나, 당시에 이정도의 대규모 로봇 데이터셋을 사용한 연구가 없었음.
- 오히려 이 모델을 다른 도메인에 해당하는 dataset으로 학습시키고, 해당 domain에서의 capacity를 비교했다면, 어땠을까?(출력단의 dimension을 바꾸고 image captioning 등의 문제를 풀게 했다면? capacity에 대해서만 비교가 가능했을지도)
- Large robot dataset에 대한 capacity 분석
- 무너지는 가정
- 3Hz는 로봇이 아주 active한 상황에선 사용하기 어렵다고 판단됨. Large dataset을 위한 capacity를 위한 trade off라고 생각이 들지만, 위 실험결과 dataset의 크기보단, 다양성이 더 중요한 factor임. 다양성이 크고 더 적은 데이터셋에 대해선 capacity를 좀 줄이더라도 빠른 inference가 가능하지 않을까?
- 13대의 17개월, 다수 오퍼레이터, 심지어 RL로 생성한 데이터까지 데이터의 분포가 매우 다양한데, 이런 대규모의 데이터셋이 아닌, 한명 혹은 RL policy only로 데이터를 만들었다면? 데이터의 다양성 자체가 살아있었을까?
- 실용적 관점
- 모델 자체는 일반 GPU로도 돌릴 수 있는 구조이지만, 학습은 불가능. RT-1 모델을 fine tunning 해서 사용하는건 가능할까?(출력단 차원을 조금 바꾸고, custom dataset으로 fine tunning)
- 로봇 데이터의 경우 양보다는 다양성이 더 높은 효용을 가진다고 할 수 있음. 다양한 데이터을 생성하기 위한 Factor를 미리 정해두는것도 좋을듯(WB, 임의의 image 노이즈, 조명, object / skill)
- early fusion아이디어는 비단 로보틱스 뿐 아닌 다른 task에도 사용이 가능한 개념이라고 생각이 듬.
- visual only 방법론은, 학술적으로 의미가 있긴 하지만, 실용적인 접근은 아니라고 생각. 현재 로봇의 state값은 대부분의 robot platform에서 주어지는 값이며, 매우 효용이 높은 데이터임. 로보틱스 문제를 NLP나 CV문제처럼 바꿔주고, cross embodiment를 더 용이하게 해주는 이점으로 포기할만한 데이터가 아니라고 생각.
- 모르는 용어
- FiLM (Feature-wise Linear Modulation)
- 어떤 feature map의 각 채널에 (γ, β)를 곱하고 더하는 conditioning 기법:
output = γ × feature + β - γ, β는 conditioning 입력(여기선 instruction 임베딩)에서 계산됨
- 효과: instruction에 따라 image feature의 어느 채널을 강조/억제할지 조절. "사과 집어"라는 명령엔 사과 색/모양 관련 채널이 강해지는 식.
- 어떤 feature map의 각 채널에 (γ, β)를 곱하고 더하는 conditioning 기법:
- TokenLearner
- 많은 토큰 → 적은 토큰으로 줄이는 attention 기반 학습 모듈
- 단순 pooling이나 random sampling이 아니라 "어느 토큰 조합이 중요한지" learnable하게 soft-select
- RT-1에선 81 visual token → 8 token으로 압축. 추론속도 위함.
- USE (Universal Sentence Encoder)
- Google이 만든 사전학습된 문장 임베딩 모델
- 자연어 문장을 고정 차원 벡터(보통 512D)로 인코딩
- RT-1에선 "사과를 집어라" 같은 instruction을 수치 벡터로 바꾸는 데 사용. 이 벡터가 FiLM의 conditioning 입력이 됨.
- identity-initialized
- 새로 추가한 layer를 처음에는 항등함수(아무것도 안 하는 상태)로 초기화하는 트릭
- FiLM 레이어의 (γ, β)를 (1, 0)으로 초기화하면
output = 1 × feature + 0 = feature→ 학습 초반엔 FiLM이 없는 것처럼 동작 - 효과: 사전학습된 EfficientNet의 가중치를 안 망가뜨리면서, 학습 진행되면 점진적으로 FiLM이 conditioning 시작
- 이게 없으면 FiLM이 처음부터 image feature를 마구 왜곡해서 ImageNet pretrain 효과가 사라짐
- FiLM (Feature-wise Linear Modulation)
