회귀분석을 하다가 3시간 날려버린 날
오늘은 지난번 상관분석에 이어 회귀분석을 진행했다.
그런데 시작부터 삐끗했다.
처음에는 총 경기 수가 통일되지 않은 데이터를 그대로 분석에 써서, 무려 3시간 동안 회귀분석을 수행했지만… 결과적으로 모든 과정을 다시 처음부터 해야 했다.
각 팀마다 경기 수가 다르면 당연히 평균 성적 비교가 불가능하기 때문에, 결국 경기당 평균치를 계산한 후 분석을 처음부터 다시 시작했다.
1. Spearman 상관분석
가장 먼저 승률(W_PCT)과 다른 변수들 간의 Spearman 상관계수를 구했다.
import pandas as pd
df = pd.read_csv("real_rank_temp.csv")
corr_spearman = df.corr(method='spearman', numeric_only=True)
w_pct_spearman = corr_spearman['W_PCT'].drop('W_PCT').sort_values(ascending=False)
print(w_pct_spearman)결과 요약 (상위 지표들):
PTS: 0.811FGM: 0.788DREB: 0.766REB: 0.733FGA: 0.698
→ 이 변수들이 승률과의 상관성이 상대적으로 높았다.
2. 선형회귀 분석 (scikit-learn)
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_squared_error
X = temp_corr.drop(columns=['W_PCT'])
y = temp_corr['W_PCT']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"R²: {r2_score(y_test, y_pred):.3f}")
print(f"MSE: {mean_squared_error(y_test, y_pred):.3f}")- R² (결정계수): 0.739
- MSE (평균제곱오차): 0.001
→ 설명력은 나쁘지 않았지만, 뭔가 아쉬운 느낌이었다.
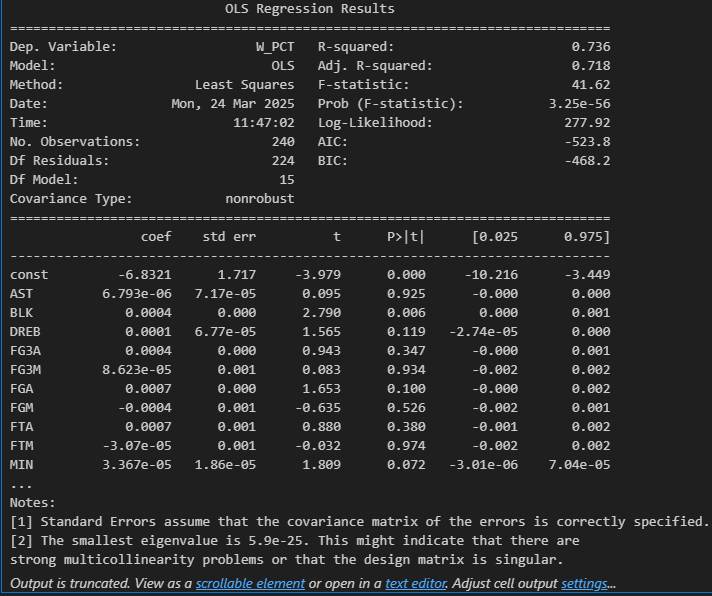
3. OLS 회귀분석 (statsmodels)
추가로 statsmodels를 사용해 회귀분석을 진행했고, 더 자세한 통계적 해석을 확인할 수 있었다.
import statsmodels.api as sm
X = temp_corr.drop(columns=['W_PCT'])
y = temp_corr['W_PCT']
X = sm.add_constant(X)
model = sm.OLS(y, X).fit()
print(model.summary())- R²: 0.736 / Adjusted R²: 0.718
- F-statistic: 41.62 (p < 0.001)
→ 모델 자체는 통계적으로 유의미했지만,
문제는 유의미한 변수가 거의 없었다.
예를 들어:
BLK: p-value = 0.006 (유의)AST,FGM,FTM등 대부분 p-value > 0.3
→ 다중공선성 문제가 있는 것 같았다. (eigenvalue 경고도 있었음)
회고
- 분석 전에 데이터 전처리가 얼마나 중요한지를 다시 한 번 느꼈다.
- 그리고 데이터가 많다고 꼭 좋은 결과가 나오는 것도 아니라는 걸 체감했다.
- 다음에는 다중공선성을 줄이기 위해 변수 선택(Feature Selection)이나 정규화 기법도 고려해야 할 듯하다.

아자아자