
Spark.intro
데이터 분석가가 spark를 왜 배워야 하는가?!
- 원래 데이터 엔지니어가 하던 일들일 데이터 분석가에게도 요구되고 있음
쿠팡플레이 데이터사이언티스트

오늘의 집

아임웹

올리브영

네이버 바이브

쿠팡

삼성

이처럼 최근에는 대부분의 데이터 사이언티스트 혹은 데이터 분석가 채용 공고에서 Spark 활용 능력을 기본 요건으로 요구하는 기업들이 점점 늘어나고 있다.
그렇다면 데이터 파이프라인이란 무엇인가?
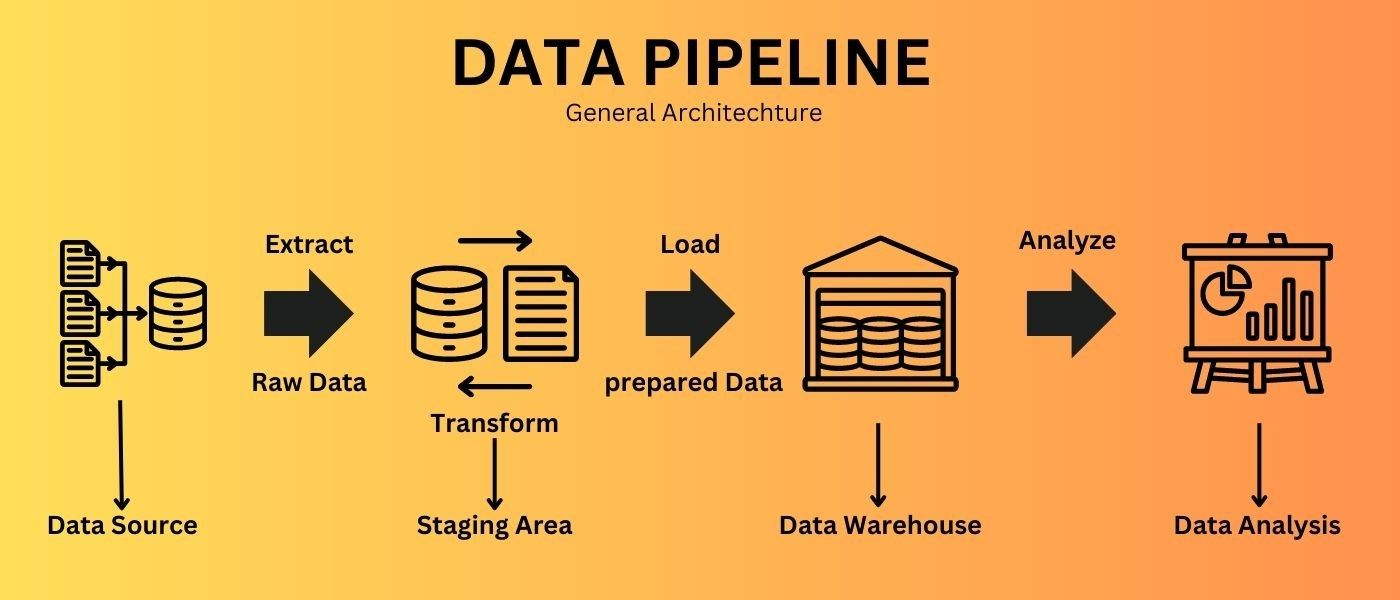
- Data Pipeline : 데이터를 수집하고 저장한 뒤, 이를 가공해 분석 가능한 형태로 만드는 일련의 흐름
- Data Warehouse : 데이터를 테이블 단위로 저장하고 ,회사 전체에서 공통으로 사용하는 중앙 저장소 역할
- Data Mart : 특정 부서나 분석 목적에 맞게 전용 데이터 테이블을 구성한 서브 저장소, Data Warehous보다 작고 목적 특화되어 있음ETL과 ELT의 차이
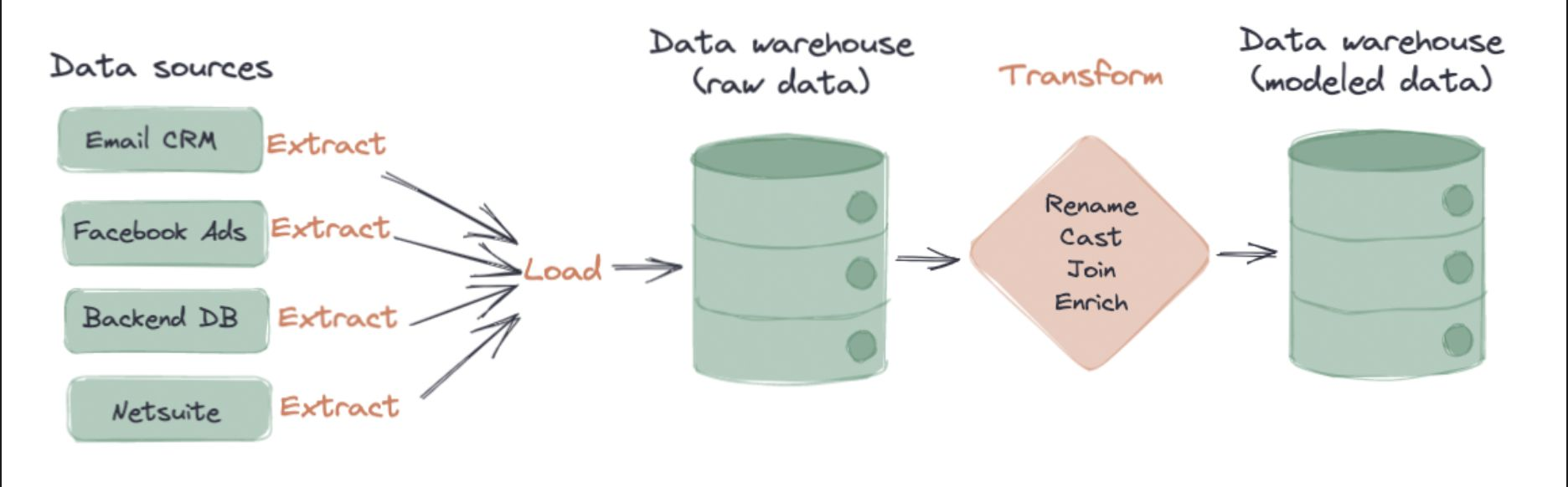
- ETL(Extract,Transform,Load)은 데이터 파이프라인의 핵심 과정이며, Spark나 Airflow같은 도구를 활용해 자동화 된다.
- 최근에는 ELT(Extract,Load,Transform) 구조 많이 사용되며, 데이터 웨어하우스에서 직접 변환하는 역할을 수행
spark 아키텍처
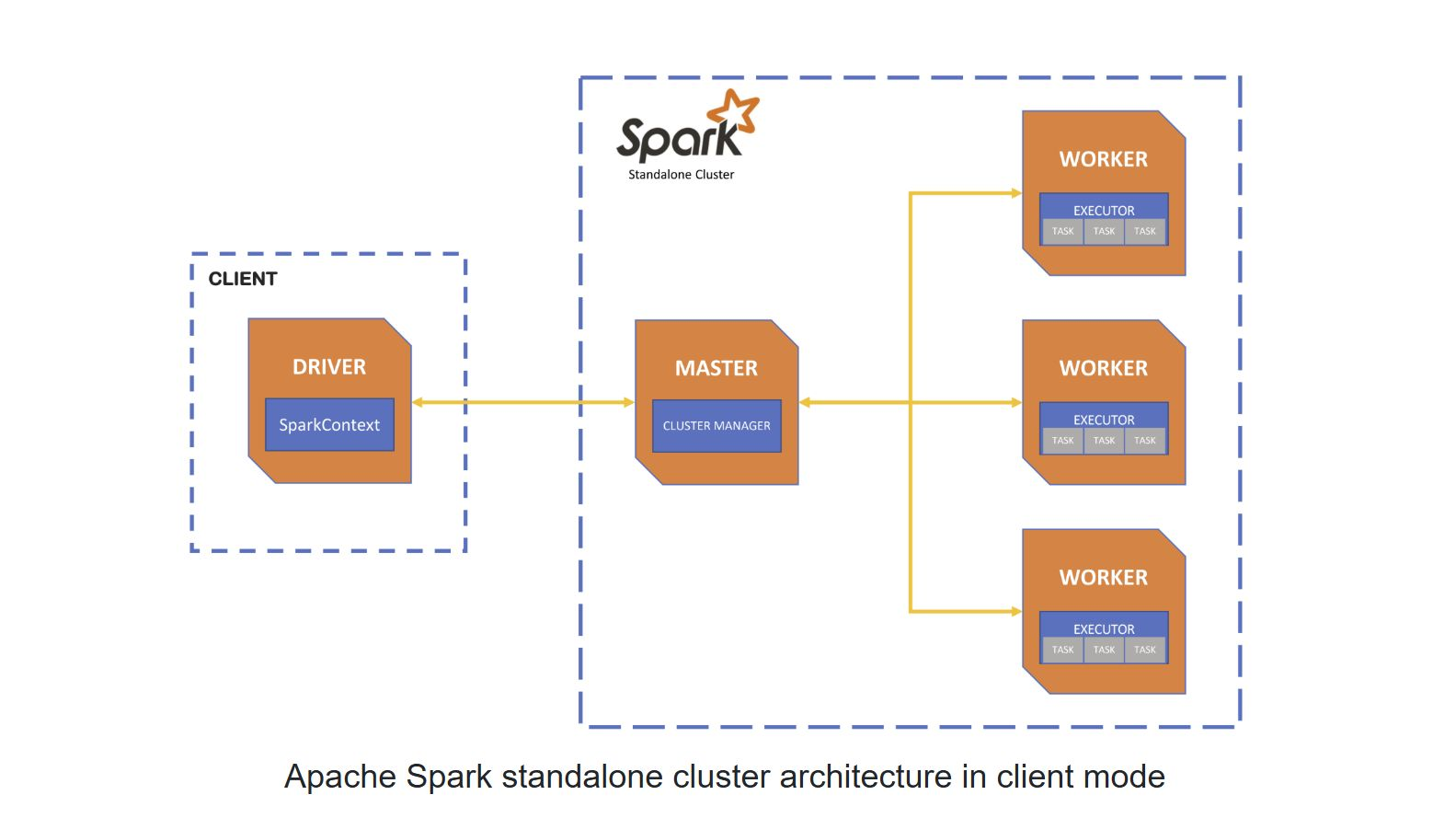
- Apache Spark : 분산 데이터 처리를 위한 오픈소스 프레임웨크
- Driver : 사용자가 직접 작성한 Spark 애플리케이션이 실행되는 주체
SparkContext를 통해 task를 Master에게 전달
사용자 코드의 시작점이자 지휘자 역할
- Master : 클러스터의 자원을 할당하고 전체 작업 상태를 모니터링 함
각 Worker에게 Executor 실행 지시
- Worker : Master로부터 자원을 할당받아 Executor를 실행
Executor는 Task를 메모리에 올려 병렬 처리 수행
실제 작업이 실행되는 노드(즉,작업자)
- Executer : Task를 실행하고 결과를 Driver로 반환
메모리 기반 처리로 빠른 속도 보장
메타데이터만 읽으며, 실행 종료 시 자원 회수됨
S3 Parque 파일 읽기 : Spark vs Pandas 완벽 비교
- SPARK
#spark 방식 예시
df = spark.read.parquet(`~`)
df.filter(df.amount>1000).groupby("region").sum().show()- Driver가 하는일
- S3 메타데이터 읽기 : 파일목록, 파티션 정보, 스키마 정보만 읽음 (실제 데이터 X)
- 논리적 실행 계획 생성
FileScan parquet -> Filter(amount>1000) -> Aggregate[region][sum(amount)] - Master : 클러스터 자원 할당
- 각 Worker 상태 확인 -> Executor 할당
- Worker/Executor : 병렬 데이터 읽기
┌────────────────┐ ┌────────────────┐ ┌────────────────┐
│ Executor 1 │ │ Executor 2 │ │ Executor 3 │
│ │ │ │ │ │
│ Task 1,2,3,4 │ │ Task 5,6,7,8 │ │ Task 9,10 │
│ │ │ │ │ │
│ S3 → part-0000│ │ S3 → part-0004│ │ S3 → part-0008│
│ S3 → part-0001│ │ S3 → part-0005│ │ S3 → part-0009│
│ S3 → part-0002│ │ S3 → part-0006│ │ │
│ S3 → part-0003│ │ S3 → part-0007│ │ │
└────────────────┘ └────────────────┘ └────────────────┘
↓ ↓ ↓
각자 필터링 각자 필터링 각자 필터링
& 부분 집계 & 부분 집계 & 부분 집계- 네트워크 흐름
- T0 : Driver가 메타데이터만 조회
- T1 : Executro가 병렬로 S3에서 파일 스트리밍 다운로드
- T2 : 로컬 메모리에서 필터링 + 집계
- T3 : 결과를 Driver에 전달
- T4 : 최종 결과 조합 및 출력
- Pandas 방식
import pandas as pd
import s3fs
fs = s3fs.S3FileSystem()
df = pd.read_parquet(~)
result = df[df['amount']>1000].groupby('region')['amount'].sum()- 동작 과정
- S3 파일 목록 조회
- 순차적 다운로드 & 메모리제 전체 적재
- 30GB ~40GB 에서 메모리 초과(OOM) 가능성
- 핵심 차이점 비교
| 항목 | Spark | Pandas |
|---|---|---|
| 읽기 방식 | 병렬 스트리밍 | 순차 전체 로드 |
| 메모리 사용 | 파티션 단위,효율적 | 전체 적제,RAM 부족 가능 |
| 속도 | 빠름(병렬 처리) | 느림(단일 프로세스) |
| 장애 복구 | 가능(Task 재할당) | 실패 시 처음부터 재시도 |
| 실무 적합성 | 대용량에 적합 | 소규모 파일에 적합 |
그럼 Spark는 만능인가..?!?! OOM(Out Of Memory)은 여전히 존재!
Spark는 분산처리 기반의 강력한 프레임워크지만, 잘못 사용하면 오히려 메모리 초과(OOM)나 성는 저하가 발생할 수 있다. 아래는 Spark 사용시 자주 발생하는 실수와 주의 사항을 정리!
- Collect( ) 사용 지양(Driver 메모리 초과)
huge_df = spark.read.parquet("s3://100gb_data/")
all_data = huge_df.collect() # 전체 데이터를 Driver로 가져옴 -> 위험! - Driver가 8GB 메모리인데 100GB데이터를 collect()로 당기면 -> OOM 발생!
- 올바른 사용 예시
huge_df.show(20) # 결과 일부만 보기
huge_df.take(100) # 100개만 샘플 추출
huge_df.write.parquet("output/") # 분산 저장 - 꼮 필요한 경우가 아니라면 collect() 대신 show(),take() 또는 write()사용!
- 거대한 Broadcast Join 문제
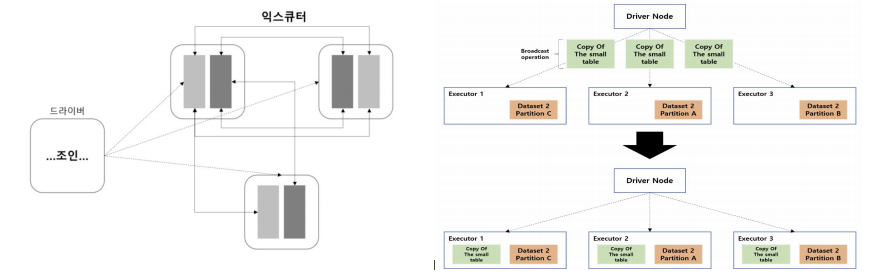
- 작은 테이블은 모드 Executor에 복사 -> Broadcast
- 큰 테이블과 조인시 Executor 메모리 초과 가능성
- 조인 대상이 너무 크거나, 모든 Executor에 복사해야 할 작은 테이블 조차 커지면 -> OOM 발생
- 해결법
- 작은 테이블인지 확인(broadcast() 사용시 주의)
- 조인 전에 필요한 컬럼만 선택
- where,partition 조건으로 필터링해서 조인 범위 최소화
- 캐시 남용
df1 = spark.read.parquet("data1/").cache() # 10GB
df2 = spark.read.parquet("data2/").cache() # 10GB
df3 = spark.read.parquet("data3/").cache() # 10GB
# Executor RAM이 8GB인데 캐시 30GB? → 💥-
캐시는 빠르게 재사용할 수 있게 해주지만, 무분별한 캐시는 오히러 메모리 터짐의 원인이 된다.
-
캐시는 선택적으로 사용!
- 반복 사용하는 데이터만 캐시
- .unpersisit()로 캐시 해제도 습관화
- 파티션 불균형
df = spark.read.option("maxPartitionBytes", "10GB").parquet("data/")
# → 한 파티션이 10GB, Executor가 8GB면? → OOM!
OR
df = spark.read.parquet("user_activities/")
result = df.groupBy("city").agg(collect_list("activity_detail").alias("all_activities"))- 만약 전체 데이터의 90%가 서울에 물려 있다면?
Partition 0 (Seoul) : 90GB → OOM!
Partition 1 (Busan) : 5GB
Partition 2 (Others): 5GB- group by의 원칙 : 같은 키(ex city='Seoul')는 반드시 하나의 Executor에서 처리해야 함 -> 데이터 쏠림 발생 시 큰 문제
- 분산해서 처리 할 수 없음
Spark는 강력하지만 잘못 쓰면 위험한거 같다.
특히 대용량 데이터를 다룰 때 메모리 한계와 데이터 분산전략에 주의해야 할듯!
갑자기 Zoom이 닫혀 버린 웃픈 상황...
다시 Zoom이 켜지고 혼신의 힘으로 웃음을 참았지만, '정아무개'님 덕분에 강렬하게 실패.
유일하게 캠을 켠 두 명이 서로 웃음을 참느라 카메라에서 사라지고 난리도 아니었음;;;
- 9시가 지나면 어줌단(어둠의 준수단)이 활동한다는 얘기가 있다. 나는 이 이야기를 무척 좋아한다.


아자아자