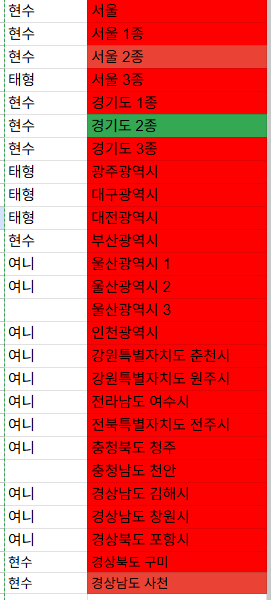
문제의 데이터
거의 5일동안 끌어오고 있는 fms 전국 데이터 목록
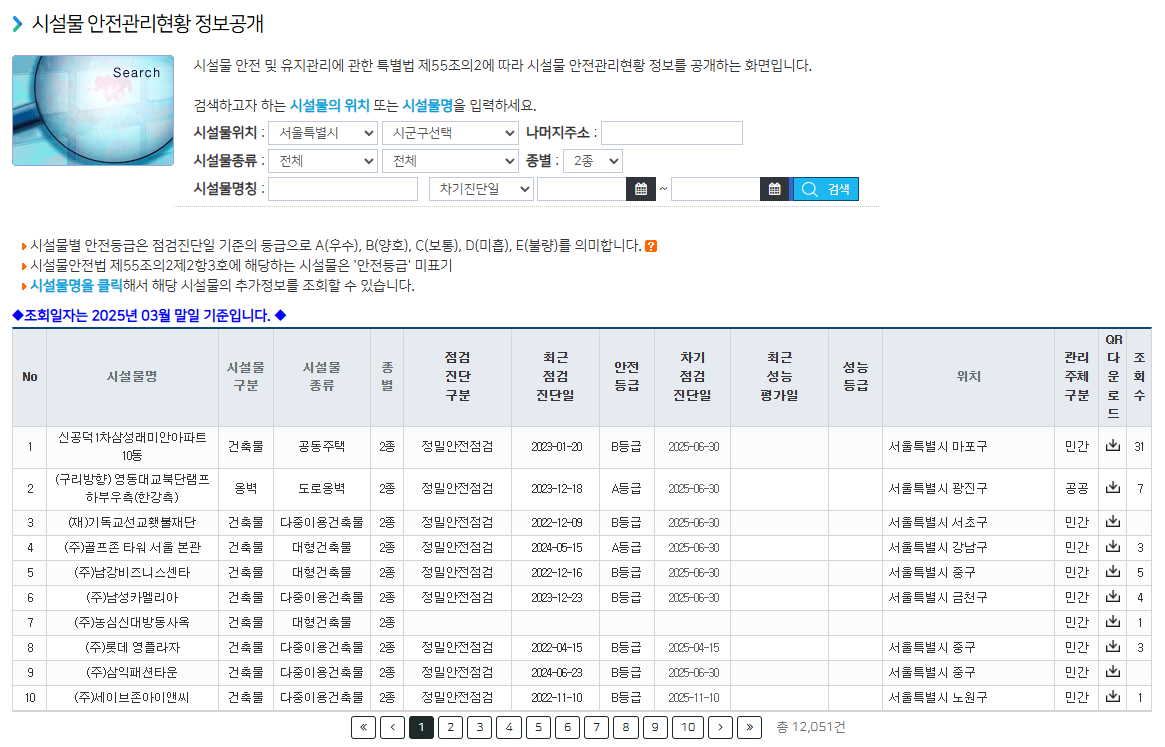
fms : 시설물통합정보관리시스템
cmd창에 먼저 입력
"C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9001 --user-data-dir="C:\chrome-debug-profile"원하는 데이터 입력
크롤링을 위한 code
import time, random, re, math
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException, StaleElementReferenceException, NoSuchElementException
# ────────────────────────────────────────────────────────
# 0) Chrome 세션에 붙기 및 기본 설정
# ────────────────────────────────────────────────────────
opts = Options()
opts.debugger_address = "127.0.0.1:9001"
driver = webdriver.Chrome(options=opts)
wait = WebDriverWait(driver, 20)
# 상세 정보가 로드되는 것을 기다리기 위한 별도의 짧은 대기 시간 설정
detail_wait = WebDriverWait(driver, 10)
# ────────────────────────────────────────────────────────
# 초기 설정: 로그인 팝업 닫기 & mainFrame 진입
# ────────────────────────────────────────────────────────
try:
alert_wait = WebDriverWait(driver, 5)
btn = alert_wait.until(EC.element_to_be_clickable(
(By.XPATH, "//*[self::button or self::a or self::input][normalize-space()='확인']")))
print("👍 로그인 알림창 발견, 확인 클릭"); btn.click(); time.sleep(1)
except TimeoutException:
print("✔️ 로그인 알림창 없어서 바로 진행")
try:
driver.switch_to.default_content()
wait.until(EC.frame_to_be_available_and_switch_to_it((By.NAME, "mainFrame")))
print("👍 mainFrame 진입 성공")
except Exception as e:
print(f"❌ mainFrame 진입 실패: {e}")
exit()
# ────────────────────────────────────────────────────────
# 컬럼 정보 수집
# ────────────────────────────────────────────────────────
header_selector = "div.table-scrollable table thead th"
all_ths = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, header_selector)))
all_keys = [th.text.strip() for th in all_ths]
first_row = wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, "div.table-scrollable table tbody tr[id^='tr_']")))
col_count = len(first_row.find_elements(By.TAG_NAME, "td"))
summary_keys = all_keys[:col_count]
print("✔️ 요약 컬럼 확정:", summary_keys)
# ────────────────────────────────────────────────────────
# 1+2단계: 페이징 & 상세 파싱
# ────────────────────────────────────────────────────────
try:
total_txt = wait.until(EC.presence_of_element_located(
(By.XPATH, "//div[@class='help-inline' and contains(text(), '총')]"))).text
total_items = int(re.search(r'(\d[\d,]*\d|\d)', total_txt).group(1).replace(",", ""))
rows_on_page = wait.until(EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, "div.table-scrollable table tbody tr[id^='tr_']")))
per_page = len(rows_on_page) or 10
max_page = math.ceil(total_items / per_page)
print(f"👍 전체 {total_items}건, 페이지당 {per_page}건 → {max_page}페이지")
except Exception as e:
print(f"❌ 페이지 수 계산 실패({e}), 1페이지만 시도")
max_page = 1
results = []
current_page = 1
processed = 0
while current_page <= max_page:
try:
driver.switch_to.default_content()
wait.until(EC.frame_to_be_available_and_switch_to_it((By.NAME, "mainFrame")))
print(f"\n>>> {current_page}/{max_page} 페이지 시작")
rows = wait.until(EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, "div.table-scrollable table tbody tr[id^='tr_']")))
for idx in range(len(rows)):
rows = wait.until(EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, "div.table-scrollable table tbody tr[id^='tr_']")))
row = rows[idx]
# ✨✨✨ 새로운 대기 전략의 핵심 ✨✨✨
# 1. 클릭 전, 현재 상세 정보 영역의 '마커'를 찾아둡니다. (첫번째 h2 태그)
try:
marker = driver.find_element(By.CSS_SELECTOR, "div#divDtlArea h2")
except NoSuchElementException:
marker = None # 첫 실행이라 상세 정보 영역이 비어있으면 마커는 없음
cols = row.find_elements(By.TAG_NAME, "td")
summary = { summary_keys[i]: cols[i].text.strip() for i in range(col_count) }
processed += 1
facility_name = summary.get('시설물명', 'N/A')
print(f" - {processed}/{total_items} → {facility_name}")
try:
driver.execute_script("arguments[0].scrollIntoView({block:'center'});", row)
time.sleep(0.3)
row.click()
except StaleElementReferenceException:
print("⚠️ StaleElement, 행을 다시 찾아 클릭합니다.")
rows = wait.until(EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, "div.table-scrollable table tbody tr[id^='tr_']")))
row = rows[idx]
driver.execute_script("arguments[0].scrollIntoView({block:'center'});", row)
time.sleep(0.3)
row.click()
specs = {}
history = []
try:
# 2. 이전에 찾아둔 '마커'가 사라질 때(stale)까지 기다립니다.
if marker:
detail_wait.until(EC.staleness_of(marker))
# 3. 새로운 내용이 로드될 때까지 기다립니다. (새로운 마커가 나타날 때까지)
detail_wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "div#divDtlArea h2")))
# 4. 이제 안심하고 현재 페이지 소스를 파싱합니다.
soup = BeautifulSoup(driver.page_source, "html.parser")
spec_area = soup.find("div", id="facilDetailArea")
if spec_area:
for tbl in spec_area.find_all("table"):
for tr in tbl.find_all("tr"):
th, td = tr.find("th"), tr.find("td")
if th and td:
specs[th.get_text(strip=True)] = td.get_text("\n", strip=True)
dtl_area = soup.find("div", id="divDtlArea")
if dtl_area:
history_titles = dtl_area.select("h2.page-title-2depth")
for title in history_titles:
if "안전점검등" in title.get_text(strip=True) or "성능평가 이력" in title.get_text(strip=True):
table_container = title.find_next_sibling("div", class_="table-scrollable")
if table_container and table_container.find("table"):
tbl = table_container.find("table")
headers = [th.text.strip() for th in tbl.select("thead th")]
first_row = tbl.select_one("tbody tr")
if first_row:
vals = [td.text.strip() for td in first_row.select("td")]
if any(vals) and "등록된 자료가 없습니다" not in vals[0]:
entry = ", ".join(f"{headers[i]}: {v}" for i, v in enumerate(vals) if i < len(headers))
history.append(entry)
except TimeoutException:
print(f" ⚠️ 상세정보({facility_name}) 로딩 지연/실패 — 요약만 저장")
except Exception as e:
print(f" ⚠️ 상세 파싱 중 오류({e}) — 가능한 정보만 수집")
final = {**summary, **specs, "안전점검 이력": history}
results.append(final)
if current_page < max_page:
try:
pagination = wait.until(EC.presence_of_element_located((By.CLASS_NAME, "pagination")))
next_page_link = pagination.find_element(By.XPATH, f".//a[normalize-space()='{current_page + 1}']")
driver.execute_script("arguments[0].scrollIntoView({block:'center'});", next_page_link)
time.sleep(0.5); next_page_link.click()
except Exception:
print("... 다음 페이지 번호가 없어 화살표로 이동")
arrow_btn = wait.until(EC.element_to_be_clickable(
(By.XPATH, "//a/i[contains(@class, 'fa-angle-right')]/.. | //a[contains(text(), '다음')]")))
driver.execute_script("arguments[0].scrollIntoView({block:'center'});", arrow_btn)
time.sleep(0.5); arrow_btn.click()
current_page += 1
time.sleep(random.uniform(1.5, 2.5))
except Exception as e:
print(f"‼️ {current_page}페이지 처리 중 예외 발생({e}) — 다음 페이지로 넘어갑니다")
current_page += 1
try:
driver.refresh()
time.sleep(2)
except Exception as refresh_err:
print(f"페이지 새로고침 실패: {refresh_err}")
continue
# ────────────────────────────────────────────────────────
# 3단계: 결과 엑셀로 저장
# ────────────────────────────────────────────────────────
print("\n--- 크롤링 완료, 파일 저장 시작 ---")
if results:
sido = "시설물"
for r in results:
if r.get("위치"):
sido_match = re.split(r'\s+', r["위치"])
if sido_match:
sido = sido_match[0]
break
fn = f"{sido}_안전관리현황.xlsx"
for it in results:
if isinstance(it.get("안전점검 이력"), list):
it["안전점검 이력"] = "\n---\n".join(it["안전점검 이력"])
df = pd.DataFrame(results)
all_columns = list(summary_keys) + [k for k in (results[0].keys() if results else []) if k not in summary_keys]
seen = set()
unique_columns = [x for x in all_columns if not (x in seen or seen.add(x))]
df = df.reindex(columns=unique_columns)
df.to_excel(fn, index=False, engine='openpyxl')
print(f"✅ 완료! 총 {len(results)}건을 '{fn}'로 저장했습니다.")
else:
print("⚠️ 수집된 데이터가 없어 파일 생성하지 않음")

아자아자


이게 뭐야..?