Isolation Forest를 활용한 이상치 탐지 프로젝트 (비지도 학습 기반)
1. 데이터 전처리
- 이상치 탐지에 사용할 주요 수치형 변수 6개(
수위_최대차,수위_변동성,수온_최대차,수온_변동성,EC_최대차,EC_변동성)에서 0값을 NaN으로 처리한 뒤 평균값으로 대체함 - 기온 및 강수 관련 변수(
사고당일_최저기온등)도 결측치를 평균으로 채움 사고발생일자→ 월(사고_월)로 파생변수 생성 후 원본 컬럼 제거지층명은 원-핫 인코딩 처리- 수치형 변수 전체를 표준화(StandardScaler) 적용
- 전처리 완료된 데이터는
df_model_input에 저장
2. Isolation Forest 모델 학습 및 예측
n_estimators=999,contamination=0.0033,random_state=42로 설정fit()을 통해 모델 학습 후,decision_function()으로 이상치 점수 추출predict()로 이상치 여부(-1: 이상치, 1: 정상) 예측
예측된 이상치 수: (contamination 기준) = n개
평균 이상치 점수, 최소/최대 점수 출력 - 결과는
df_result_iso에 이상치 점수(iso_score)와 예측 결과(is_anomaly_pred_auto)로 저장
3. 수동 임계값 적용 (99.9 퍼센타일 기준)
- 모델의 contamination과는 별개로, 이상치 점수의 하위 0.1%에 해당하는 값을 기준으로 수동 임계값 설정
- 해당 임계값 이하인 경우만 이상치(-1)로 최종 라벨링 (
is_anomaly_pred_final)
final_threshold = np.percentile(iso_clf_score, 0.1)4. 최종 이상치 데이터 분석
- 최종 이상치로 분류된 샘플을
final_anomalies_iso_df에 저장 - 이상치 점수가 가장 낮은 상위 10개 샘플 출력
- 이상치 데이터들의 수치 변수에 대한 기술통계(describe) 확인 가능
5. 모델 성능 간단 평가 (학습 데이터 기준)
- 정상 데이터 중 랜덤 100개 추출 → 모델 예측 결과 비교
- 이상 데이터 중 랜덤 100개 추출 → 모델 예측 결과 비교
정상 예측 비율: 00.00%
이상치 예측 비율: 00.00%- 단, 이 평가는 학습에 사용된 데이터를 기반으로 한 것이므로, 과적합 가능성 존재
- 실제 성능 평가는 별도의 테스트 데이터로 수행 필요
이상치 탐지 프로젝트에서는 Isolation Forest의 특성과 한계(특히 contamination 설정의 민감도)를 고려해, 수동 임계값 설정을 함께 적용하는 것이 중요함.
이 방법을 통해 모델이 자동 분류한 이상치 외에도, 보다 강력한 이상치 후보들을 선별하여 후속 분석 또는 실제 점검 대상으로 활용 가능함.
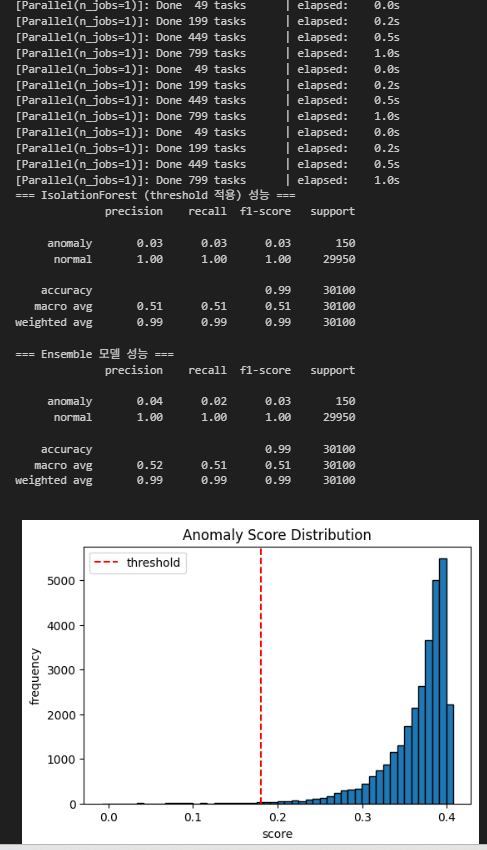
결과가 최악으로 나옴 진짜 망했다.........ㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠ

아자아자
ㅁㄴㅇㄹ..? 이게 뭔 뜻이야...?