SpringBoot는 싱글톤으로 Bean 객체를 관리한다.
그렇다면 다중 요청은 어떻게 처리하는가?
→ 스프링부트가 다중요청을 처리하는 것이 아니라, 스프링부트에 내장되어있는 서블릿 컨테이너인 Tomcat에서 다중요청을 처리해준다.
다중요청 처리 흐름
- Tomcat은 다중 요청을 처리하기 위해서, 부팅할 때 스레드의 컬렉션인 Thread Pool을 생성한다.
- 유저 요청(HttpServletRequest)가 들어오면 Thread Pool에서 하나씩 Thread를 할당한다.
- 해당 Thread에서 스프링부트에서 작성한 Dispatcher Servlet을 거쳐 유저 요청을 처리한다.
- 작업을 모두 수행하고 나면 스레드는 스레드풀로 반환한다.
1. 스레드란?
- 프로세스 내에서 실제로 작업을 수행하는 주체
- cpu의 자원을 이용하여 코드를 실행하는 하나의 단위
- 멀티 스레드: 여러 개의 스테드를 가지는 프로세스
2. Thread Pool
SpringBoot에서 Spring-Web 디펜던시를 추가하면
내장 서블릿 컨테이너로 Tomcat을 사용하게 된다.
Tomcat 3.2 이전 버전에서는, 유저의 요청이 들어올 때 마다
Servlet을 실행할 Thread를 하나씩 생성하고, 요청이 끝나면 destory했다.
이는 다음과 같은 두 가지 문제를 발생기킨다.
- 모든 요청에 대해 스레드를 생성하고 소멸하기 때문에 OS와 JVM에 많은 부담이 된다.
- 동시에 일정 이상의 다수 요청이 들어올 경우 리소스(CPU와 메모리 자원) 소모에 대한 억제가 어렵다.
→ 순간적으로 서버가 다운되거나 동시다발적인 요청을 처리하지 못해서 생기는 문제가 생길 수 있다.
이러한 문제를 해결하기 위해,
Tomcat은 다중 요청을 처리하기 위해 Thread Pool 기법을 사용한다.
Thread Pool 기법
Thread를 미리 만들어 놓고, 작업 시 Thread Pool에서 가져가 사용하고, Thread 자원을 해제하는 것이 아닌 Thread Pool에 다시 반납하는 기법
Thread Pool을 사용하는 이유
Thread를 생성하고 할당을 해제하는데 많은 비용이 들기 때문이다.
따라서 미리 Thread를 만들어놓고 사용과 반납 사이클을 가진다.
이러한 Thread Pool의 size는 application.yml 혹은 application.properties를 이용해서 설정 가능하다.
(만약 설정을 주지 않는다면,SpringBoot AutoConfiguration에서 정의한 디폴트값을 주입하게 된다. 해당 디폴트 값은org.springframework.boot.autoconfigure.web.ServerProperties클래스에서 확인할 수 있다.)
- 설정 예시
server:
tomcat:
threads:
min-spare: 10 # 아무 작업이 없어도 활성화 되어있는 Thread 개수
max: 200 # Thread Pool의 최대 개수 (계속해서 Thread가 부족할 경우 추가 생성해서 최대 한도가 200이라는 뜻)
accept-count: 100 # 작업큐 아직 할당받지 못한 요청들이 대기하는 큐의 크기
connection-timeout:
max-connections: # 지정된 시간에 서버가 승인하고 처리할 수 있는 최대 연결 수이며, 놀고 있는 Thread가 없다면 accept-count을 기반으로 연결할 수 있음- 스레드풀의 size는 애플리케이션마다 다르지만,
일반적으로적정 스레드 개수 = cpu 수 * 1+ 대기, 유휴 시간/서비스 시간)이다.
- cpu 대기시간이 서비스 시간보다 짧다면 cpu 개수보다 스레드가 적어야 성능이 좋다.
- 대기가 짧기에 (context 스위칭 비용이 적기에) 스레드 개수 적어도 상관없기 때문이다.
- 반대로 대기시간이 서비스 처리 시간보다 많다면 스레드 수는 cpu개수보다 많아야 성능이 좋다.
- 대기가 길기에 (context 스위칭 비용이 많기에) 스레드 개수를 늘려 대기를 줄여야 하기 때문이다.
어플리케이션마다 서비스 시간, 환경 등등이 다르므로 적절한 Thread Pool의 크기를 애플리케이션을 실행하며 튜닝하는 것이 가장 좋다.
3. Thread Pool의 기본 흐름
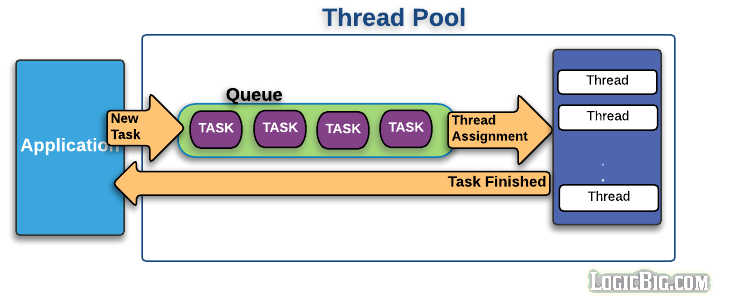
- 첫 작업이 들어오면, core size만큼의 스레드를 생성한다.
- 유저 요청(Connection, Server socket에서 accept한 소캣 객체)이 들어올 때마다 작업 큐(queue)에 담아둔다.
- core size의 스레드 중, 유휴상태(idle)인 스레드가 있다면, 작업 큐에서 작업을 꺼내 스레드에 작업을 할당하여 작업을 처리한다.
- 3-1. 만약 유휴상태인 스레드가 없다면, 작업은 작업 큐에서 대기한다.
- 3-2. 그 상태가 지속되어 작업 큐가 꽉 찬다면, 스레드를 새로 생성한다.
- 3-3. 3번과정을 반복하다 스레드 최대 사이즈 에 도달하고 작업큐도 꽉 차게 되면, 추가 요청에 대해선 connection-refused 오류를 반환한다.
- 태스크가 완료되면 스레드는 다시 유휴상태로 돌아간다.
- 4-1. 작업큐가 비어있고 core size이상의 스레드가 생성되어있다면 스레드를 destory한다.
4. Thread Pool 기법이 효율적인 이유
-
스레드를 재사용하여 불필요한 생성/소멸 비용을 줄인다.
→ 스레드는 생성 자체에 비용이 크기 때문에 한 번 만들어두고 반복 사용하는 것이 더 효율적이다. -
스레드 수를 제한함으로써 시스템 자원을 통제할 수 있다.
→ max 개수를 설정해 무한 스레드 생성을 막고, 서버가 요청 폭주에 버틸 수 있게 한다. -
요청 큐(작업 대기열)를 활용하여 순차적이고 안정적인 처리 흐름을 유지한다.
→ 스레드가 부족할 경우 요청을 큐에 대기시키며 서버가 다운되지 않도록 방어한다. -
예측 가능한 처리량과 응답 성능을 확보할 수 있다.
→ 적절한 스레드 수와 큐 크기를 설정하면 성능 튜닝이 가능하고, 병목을 방지할 수 있다.
결과적으로, Thread Pool은 성능을 안정적으로 유지하면서 리소스 낭비를 최소화할 수 있는 전략이다.
이로 인해, 고정된 자원으로 최대한 많은 요청을 감당하고, 비정상적인 요청 폭주에 대비할 수 있게 된다.
