분류(Classification)
- 레이블이 포함된 데이터를 학습하고 유사한 성질을 갖는 데이터끼리 분류한 후, 새로 입력된 데이터가 어느 그룹에 속하는지를 찾아내는 기법
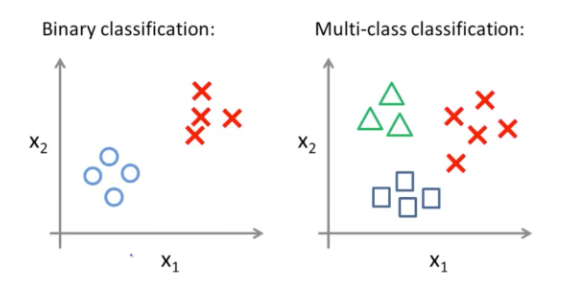
분류의 종류
- 이진 분류(Binany Classification)
- 데이터를 2개의 그룹으로 분류
- 다중 분류(Multiclass Classification)
- 데이터를 3개의 그룹 이상으로 분류
- 분류 알고리즘
- K-최근접 이웃(KNN)
- 서포트 벡터 머신(SVM)
- 의사결정나무(Decision Tree)
- 로지스틱 회귀(Logistic Regression)
- KNN(K-Nearest Neighbors, K-최근접 이웃)
-
새로운 데이터가 들어왔을 때 가장 가까운 유사 속성에 따라 기존 데이터의 그룹(K개의 그룹) 중 어떤 그룹에 속하는지 분류하는 알고리즘 (유유상종)
-
거리 기반 분류 분석 모델
-
기존 관측치의 Y값(Class)가 존재한다는 점에서 비지도학습인 '클러스터링(Clustering)'과 차이가 있음.
-
데이터로부터 거리가 가까운 K개의 다른 데이터의 레이블을 참조하여 분류
-
거리 측정 시 '유클리디안 거리'계산법 사용
-
K 값은 가능하면 홀수로 지정하는 것이 좋음. 동점 상황 방지를 위해.
-
학습 데이터 내에 존재하는 노이즈의 영향을 크게 받지 않으며, 학습 데이터 수가 많을 때 효과적인 알고리즘
-
단점: 어떤 하이퍼 파라미터가 분석에 적합한지는 불분명하기 때문에, 데이터 각각의 특성에 맞게 연구자가 임의로 선정해야 한다.
-
이미지 처리, 영상에서의 글자/얼굴 인식, 영화/음악/상품 추천에 대한 개인별 선호 예측 등에 응용
장점과 단점
-
장점
- 알고리즘이 단순하고 효율적이어서 구현이 쉬움.
- 기저 데이터 분포에 대한 가정을 하지 않아도 됨.
- 훈련 단계가 빠름.
- 수치 기반 데이터 분류 작업에서 성능이 우수함.
-
단점
- 모델을 생성하지 않아 특징과 클래스 간 관계를 이해하는 데 제한적이다.
- 적절한 K 값에 대한 선택 필요
- 데이터가 많아지면 분류 단계가 느림.
- 명목 특징 및 누락 데이터를 위한 추가 처리가 필요.
- SVM(Support Vector Machine)
- 두 개의 그룹(데이터)을 분리하는 방법으로 데이터들과 거리가 가장 먼 초평면(hyperplane)을 선택하여 분리하는 방법
- 패턴인식, 자료분석을 위한 지도학습 모델분류와 회귀분석을 위해 사용
- 의사결정나무(Decision Tree)
- 데이터를 분석하여 이들 사이에 존재하는 패턴을 예측 가능한 규칙들의 조합으로 나타내며, 그 모양이 ‘나무’와 같음.
- 로지스틱 회귀(Logistic Regression)
- 통계 모형(로짓(logit) 모형이라고도 함)은 분류 및 예측 분석에 자주 사용
- 지정된 독립 변수 데이터 세트를 기반으로 보팅/보팅 안 함 등과 같은 이벤트가 발생할 확률을 추정
- 결과는 확률이므로 종속 변수는 0과 1 사이

개발자로서 성장하는 데 큰 도움이 된 글이었습니다. 감사합니다.